54 KiB
title, space_id, status, published_at, is_comments_enabled, is_liking_enabled, skip_notifications, cover_image, circle_post_id
| title | space_id | status | published_at | is_comments_enabled | is_liking_enabled | skip_notifications | cover_image | circle_post_id |
|---|---|---|---|---|---|---|---|---|
| Projektowanie API dla efektywnej pracy z modelem | 2476415 | scheduled | 2026-03-11T04:00:00Z | true | true | false | https://cloud.overment.com/crafting-blueprints-1772882411.png | 30408378 |
{kind=link}
Różnica między zastosowaniem API w kodzie aplikacji a narzędziami AI dotyczy głównie właściwego zarządzania kontekstem oraz strukturą interfejsu narzędzi. Lekcja S01E02 pokazała to nam z szerokiej perspektywy, a teraz przyjrzymy się temu z bliska.
Na wstępie dodam tylko, że część uwagi skupimy na Model Context Protocol (MCP). Protokół ten spotyka się z negatywnymi opiniami, co może budzić niechęć. Chciałbym jednak, abyśmy dali mu szansę. Po dotychczasowych lekcjach powinno już stawać się jasne, że większość złych doświadczeń użytkowników serwerów MCP nie wynika z samego protokołu, o czym niebawem się przekonamy. Jeśli jednak nie zmieni to Twojego zdania, większość wiedzy z tej lekcji nadal można wykorzystać przy projektowaniu narzędzi dla agentów bez uwzględniania MCP.
Cechy API wpływające na kształtowanie narzędzi dla AI
Powiedzieliśmy już wiele na temat struktury narzędzi, walidacji, obsługi błędów oraz formatów odpowiedzi. Nawet jeśli API obsługuje niektóre z nich w sposób nieprzyjazny dla modelu, możemy to skorygować na etapie projektowania narzędzi. Istnieją jednak przypadki, które trudno zaadresować bez wprowadzenia zmian w samym API.
Przed rozpoczęciem prac nad narzędziem, należy zweryfikować:
- Brakujące bądź ograniczone akcje (np. brak możliwości tworzenia zasobów)
- Sposób odnoszenia się do zasobów, np. po identyfikatorze bądź nazwie. Model powinien mieć jasną informację o tym, że jeśli użytkownik mówi "przypisz etykietę Priorytet", to dany wpis musi uzyskać etykietę o identyfikatorze odpowiadającemu tej nazwie.
- Nieścisłości w strukturach zapytań i odpowiedzi (np. stosowanie content oraz body)
- Niekompletne bądź zbyt szczegółowe odpowiedzi (np. potwierdzanie utworzenia zasobu jedynie poprzez status 201 Created)
- Skomplikowane relacje wymagające wielu akcji dla jednego zadania (np. dodawanie kodu rabatowego wymagające utworzenia promocji i przypisania jej do produktu)
- Obecności mechanizmów wymagających oczekiwania na uzyskanie rezultatu (np. polling). Ich obsługa może być domyślnie utrudniona dla agentów i warto ją zaadresować po stronie kodu.
- Podobnie jak akcje asynchroniczne, dla agentów problematyczny jest rate limit, który również w miarę możliwości powinniśmy adresować po stronie kodu, aby agent nie musiał uruchamiać akcji wielokrotnie.
- Ustawienia paginacji oraz przeszukiwania zasobów. Agenci będą szczególnie często korzystać z tych funkcjonalności, aby uniknąć pobierania zbyt dużej ilości treści z góry.
Obecnie najlepiej jest pobrać oficjalne SDK (jeśli istnieje) i porozmawiać na jego temat z agentem do kodowania (np. Open Code). Zadając pytania, otrzymamy spersonalizowane odpowiedzi, a nawet wygenerujemy skrypty, które zweryfikują nasze założenia. Dobrze jest też zapisywać najważniejsze notatki poprzez generowanie ich treści z pomocą AI. Zasadniczo im więcej informacji zdobędziemy na temat API, tym lepiej.
Planowanie struktury narzędzi oraz schematów właściwości
Po zapoznaniu się z API, planowanie narzędzi opiera się na połączeniu wiedzy na jego temat z wiedzą o projektowaniu narzędzi i schematów dla AI o których rozmawialiśmy w lekcjach S01E01 i S01E02. Najlepiej będzie, jeśli zobaczymy to w praktyce na przykładzie narzędzi do interakcji z systemem plików ale zrealizowanych w sposób produkcyjny. Bo choć narzędzia z przykładu 01_02_tool_use realizowały swoje zadanie, tak na potrzeby zaawansowanego agenta AI będą niewystarczające.
Zanim przejdziemy dalej, wyjaśnię tylko, że Model Context Protocol (MCP) to kształtujący się standard skupiający się na możliwie łatwym połączeniu LLM z zewnętrznymi narzędziami, zasobami czy plikami oraz warstwą autoryzacji czy uprawnień. Na ten moment można wyobrazić sobie, że "MCP Server" to paczka z narzędziami, którą podłączamy do agentów. Później przejdziemy do bardziej precyzyjnej definicji.
W oficjalnym serwerze Filesystem MCP widzimy dokumentację opisującą aż 13 różnych narzędzi, które muszą zostać dodane do kontekstu LLM! Są to konkretnie: read_text_file, read_media_file, read_multiple_files, write_file, edit_file, create_directory, list_directory, list_directory_with_sizes, move_file, search_files, directory_tree, get_file_info, list_allowed_directories.
To całkiem sporo akcji, biorąc pod uwagę fakt, że mówimy tutaj o zaledwie jednym obszarze zadań: interakcji z systemem plików! Tymczasem agenci do kodowania (np. Cursor) pokazują nam, jak skutecznie modele LLM posługują się narzędziami takimi jak grep czy ripgrep. Sam dostęp do shella daje znacznie większe możliwości, lecz jest on zdecydowanie trudniejszy w konfiguracji i wdrożeniu na skalę produkcyjną bez sandboxów, które często przekładają się na wyższe koszty i zwiększają złożoność całego systemu.
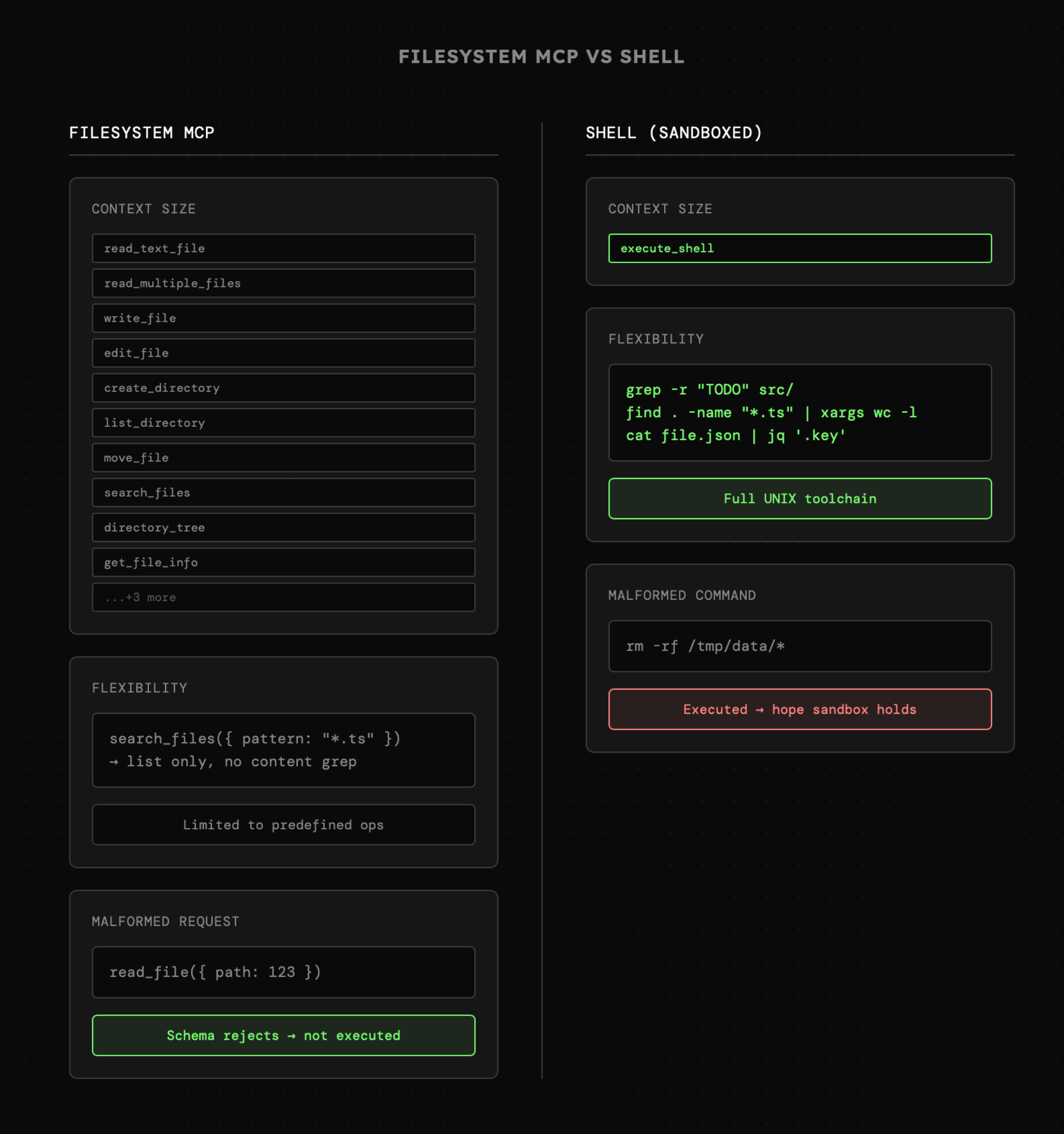
Na pierwszy rzut oka powyższy schemat jasno sugeruje, że wysiłek włożony w podłączenie sandbox'a powinien się opłacić. Natomiast nadal, nie zawsze będziemy mieć taką możliwość. W zamian, możemy skupić się na optymalizacji narzędzi z oficjalnego serwera Filesystem MCP.
Bo jeśli zastanowimy się przez chwilę nad akcjami dotyczącymi plików, tak naprawdę uzyskamy cztery, główne akcje:
- fs_search: Przeszukiwanie plików
- fs_read: Odczytywanie treści
- fs_write: Zapisywanie i edycja treści
- fs_manage: Zarządzanie katalogami i plikami
Zestawiając je z listą narzędzi z Filesystem MCP:
- Search: może obsługiwać zarówno przeszukiwanie plików, jak i struktury katalogów, a także obejmować opcję wyświetlania szczegółów pliku oraz listę dostępnych katalogów.
- Read: może obsługiwać pliki tekstowe, binarne oraz wczytywanie wielu plików na raz.
- Write: może zastąpić write_file oraz edit_file.
- Manage: może zastąpić wszystkie akcje związane z tworzeniem i modyfikacją katalogów oraz plików, wliczając w to ich przenoszenie.
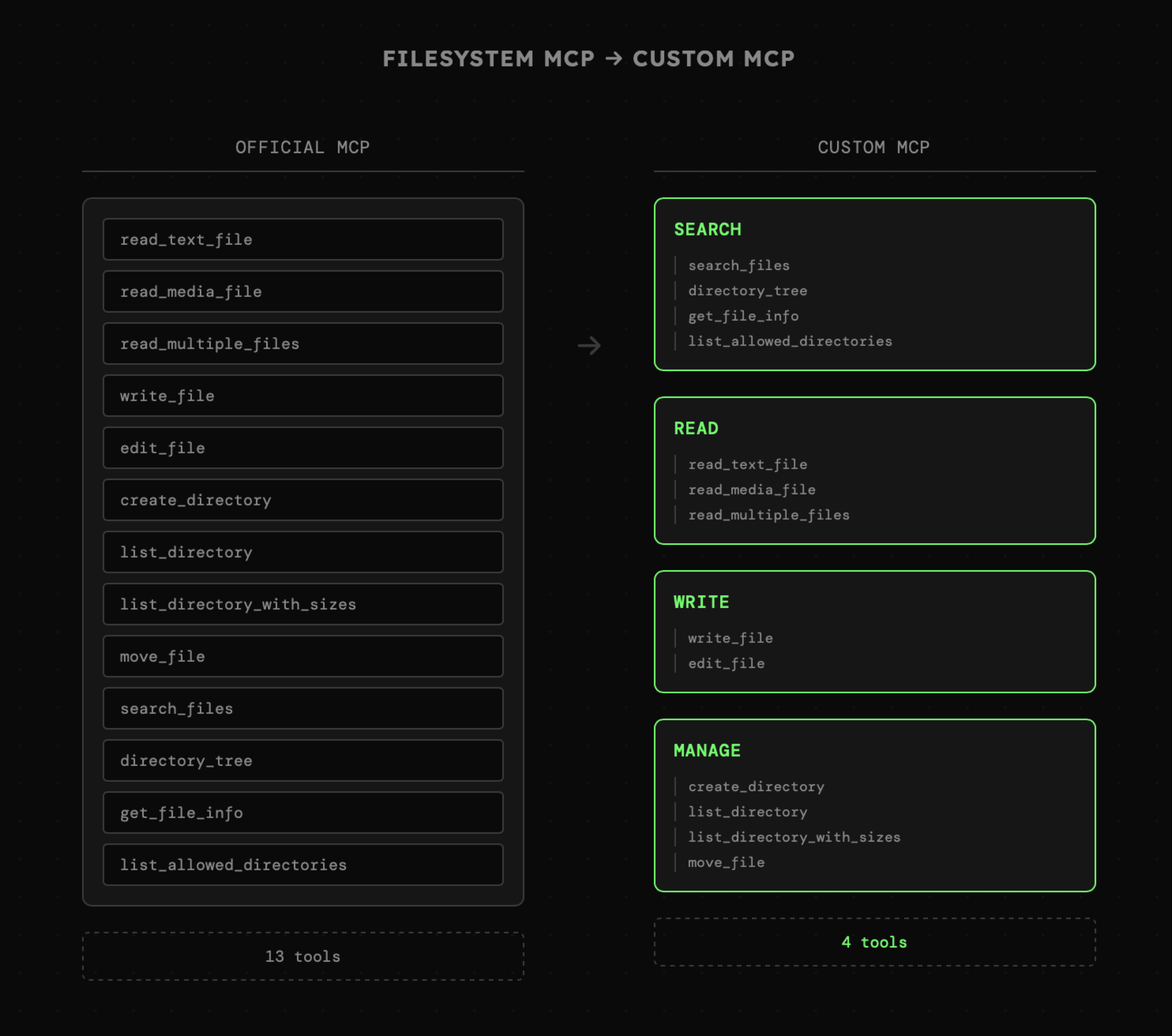
Przy takiej "optymalizacji" narzędzi zawsze należy pamiętać o ich przejrzystości. Celem nie jest wyłącznie zmniejszenie liczby schematów, lecz odnalezienie właściwego balansu między dostępnymi akcjami a skutecznością ich obsługi przez model.
Dokładnie na tej samej zasadzie można planować narzędzia dla AI, analizując dostępne akcje API. Proces ten najlepiej zrealizować wspólnie z LLM. Musimy tylko wgrać do kontekstu plik z zestawieniem dostępnych endpointów, właściwości i obiektów odpowiedzi.
Optymalizacja interfejsu na potrzeby modeli językowych
Mając założenia dotyczące listy narzędzi, możemy przejść do kształtowania ich interfejsu. Na uwadze musimy mieć strukturę API (w naszym przypadku są to akcje dotyczące systemu plików), perspektywę i możliwości LLM oraz przypadki użycia. Zatem:
- API definiuje fundamentalne możliwości i ograniczenia dostępnych akcji
- Perspektywa LLM wymaga zachowania przejrzystości narzędzi
- Możliwości LLM mówią o poziomie złożoności akcji oraz wyników ich działania
- Ograniczenia LLM mówią o potencjalnych problemach, np. halucynacji
- Przypadki użycia adresują potrzeby użytkownika oraz cel budowanych narzędzi
To wszystko pozwoli nam na ukształtowanie schematów, więc przejdźmy teraz przez poszczególne narzędzi, począwszy od fs_read.
Odczytywanie plików i katalogów działa w dwóch trybach, ale współdzieli strukturę parametrów. Po prostu niektóre z nich są ignorowane w zależności od trybu. Podobnie zachowuje się struktura odpowiedzi, ale tutaj pojawiają się już istotne różnice. Patrząc na te schematy, warto zwrócić uwagę na proste nazwy oraz minimalną ilość danych z opcją określania trybu oraz detali.
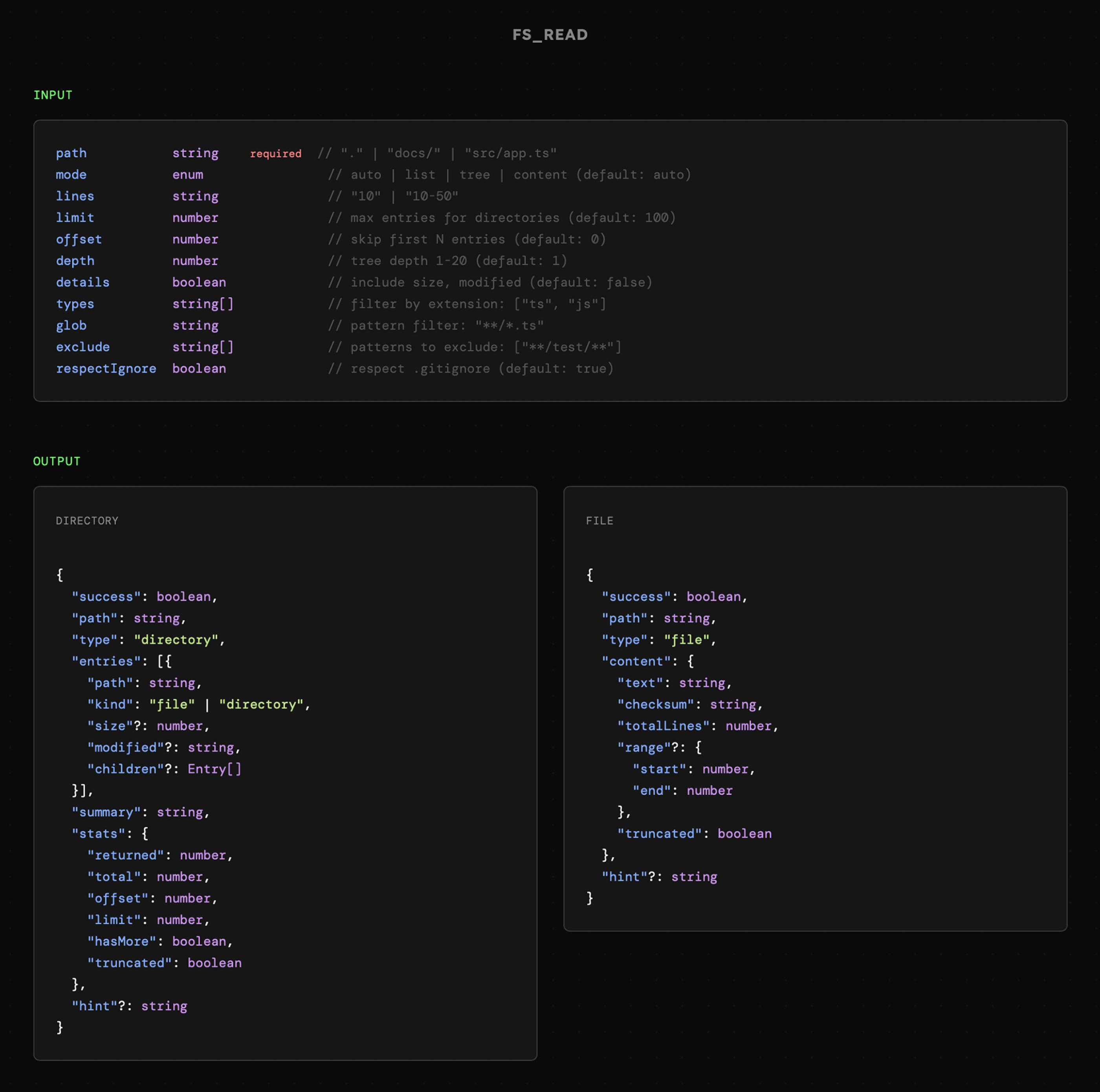
Po stronie implementacji dzieje się dość dużo, ponieważ uwzględniamy różnego rodzaju sytuacje brzegowe oraz pomyłki modelu. W obu przypadkach zwracane są niezbędne informacje wraz z dynamicznie generowaną wskazówką, dzięki której agent potencjalnie wie, co należy zrobić dalej.
Odpowiednio reagujemy na sytuacje w których dokumenty bądź katalogi zawierają zbyt dużo informacji albo gdy agent próbuje przekroczyć narzucone uprawnienia. Podobnie też stosujemy mechaniki wspierające eksplorowanie plików, np. rozwiązując ścieżkę do dokumentu w sytuacji gdy model poda jedynie jego nazwę.
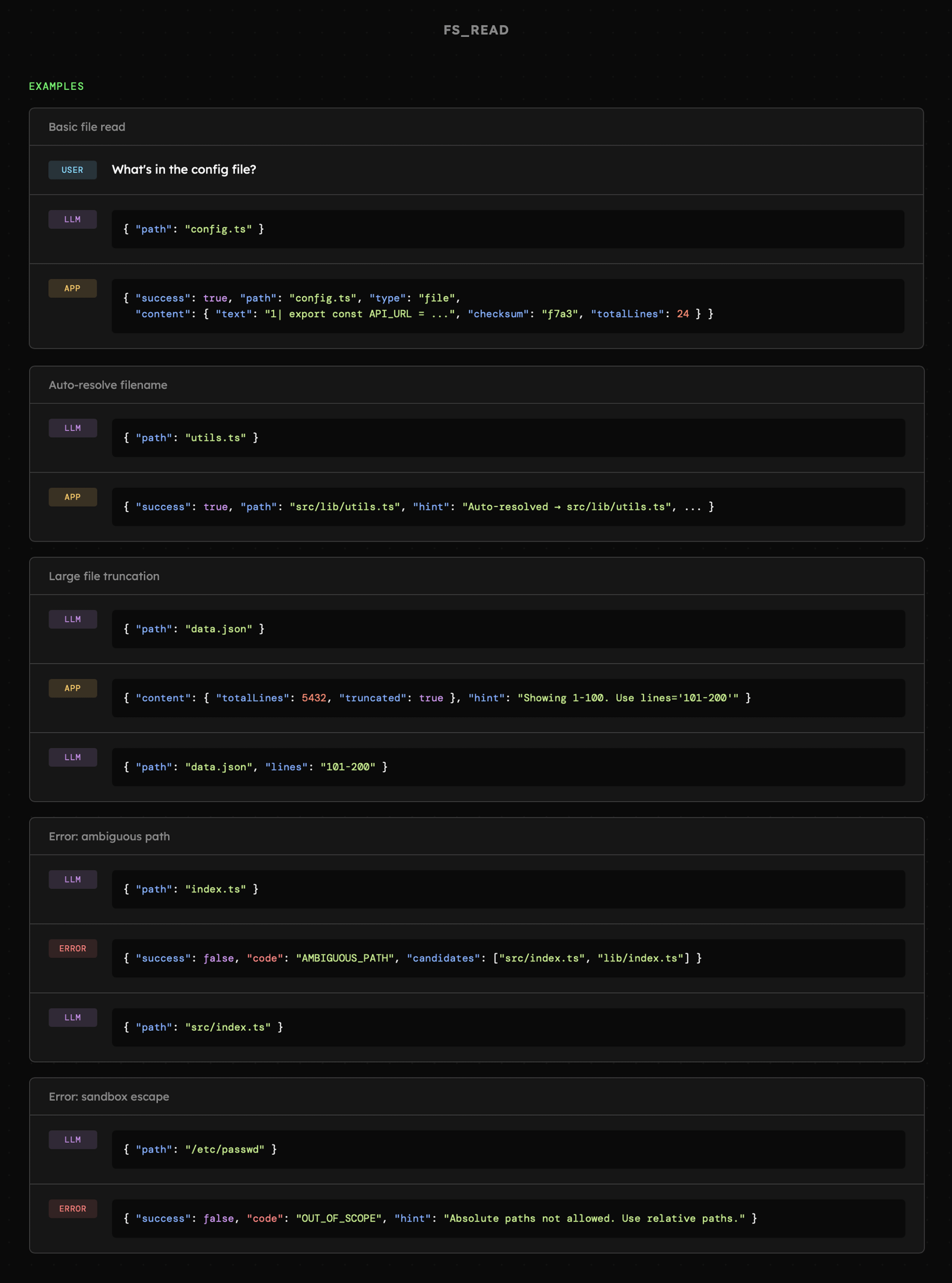
Oczywiście można dyskutować, czy warto było wyodrębnić narzędzia fs_read_file oraz fs_read_directory zamiast jednego fs_read. Decyzję o tym można jednak podjąć indywidualnie, rozważając kontekst konkretnego projektu. W tym przypadku, pracując w ten sposób przez ostatnie miesiące (w nieco zmienionej formie), nie zauważyłem, aby LLM miał problem z ich obsługą.
Bardziej istotny jest tutaj sposób myślenia o implementacji, który wyraźnie wykracza poza standardowe działania stosowane przy projektowaniu API dla narzędzi i usług. Tam znacznie rzadziej dba się o kwestie takie jak automatyczne rozwiązywanie ścieżek czy tak szczegółowe wskazówki. Poza tym widoczne jest tutaj także projektowanie z myślą o przypadkach użycia, dzięki którym adresujemy sytuacje nieprzyjazne dla modelu (np. związane z przekroczeniem kontekstu).
W oparciu o to samo podejście powstało narzędzie fs_write, jednak w tym przypadku pojawia się kilka dodatkowych mechanik wynikających z jego specyfiki. Przeszukiwanie i odczytywanie plików zazwyczaj nie wiąże się ze zbyt dużym ryzykiem, natomiast ich modyfikowanie stwarza znaczną przestrzeń do popełnienia błędów.
Wiemy już, że nie mamy możliwości zabezpieczenia się przed wszelkimi pomyłkami, ale mamy możliwość minimalizowania ryzyka ich wystąpienia. Dlatego zastosowałem weryfikację checksum oraz opcję dryRun. Dzięki nim agent nie może nadpisać pliku, który został w międzyczasie zmieniony oraz może sprawdzić jak będzie wyglądał dokument po wprowadzaniu zmian.
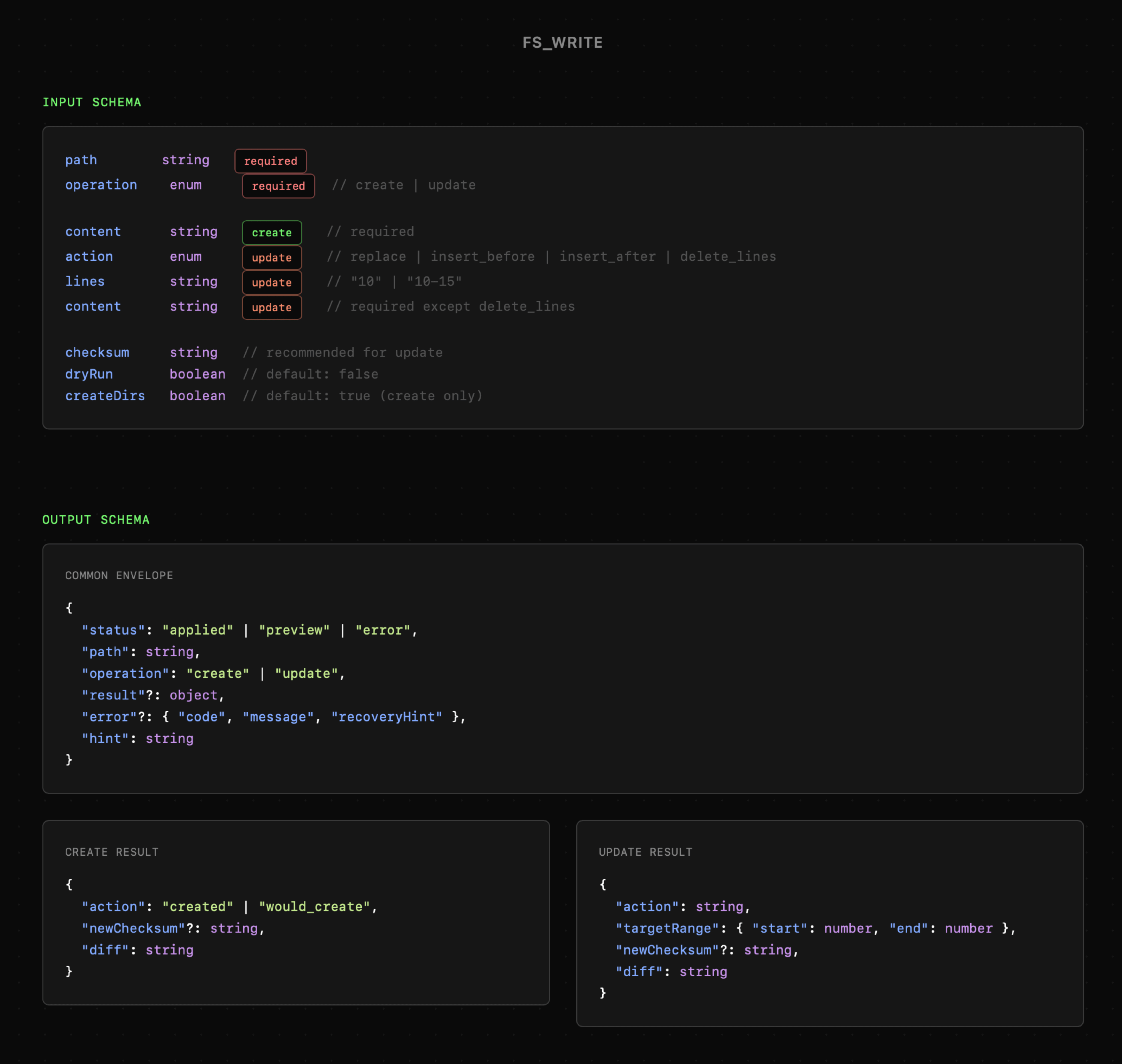
Poniższe przykłady użycia pokazują również odpowiednie podejście do informowania modelu o wynikach. Mogłoby się wydawać, że przy tworzeniu lub aktualizacji pliku zwracanie jego ścieżki nie jest konieczne. W praktyce jest to jednak istotne, aby wzmocnić zachowanie modelu, dzięki czemu będzie on w stanie wykorzystać zmodyfikowany plik w dalszych akcjach.
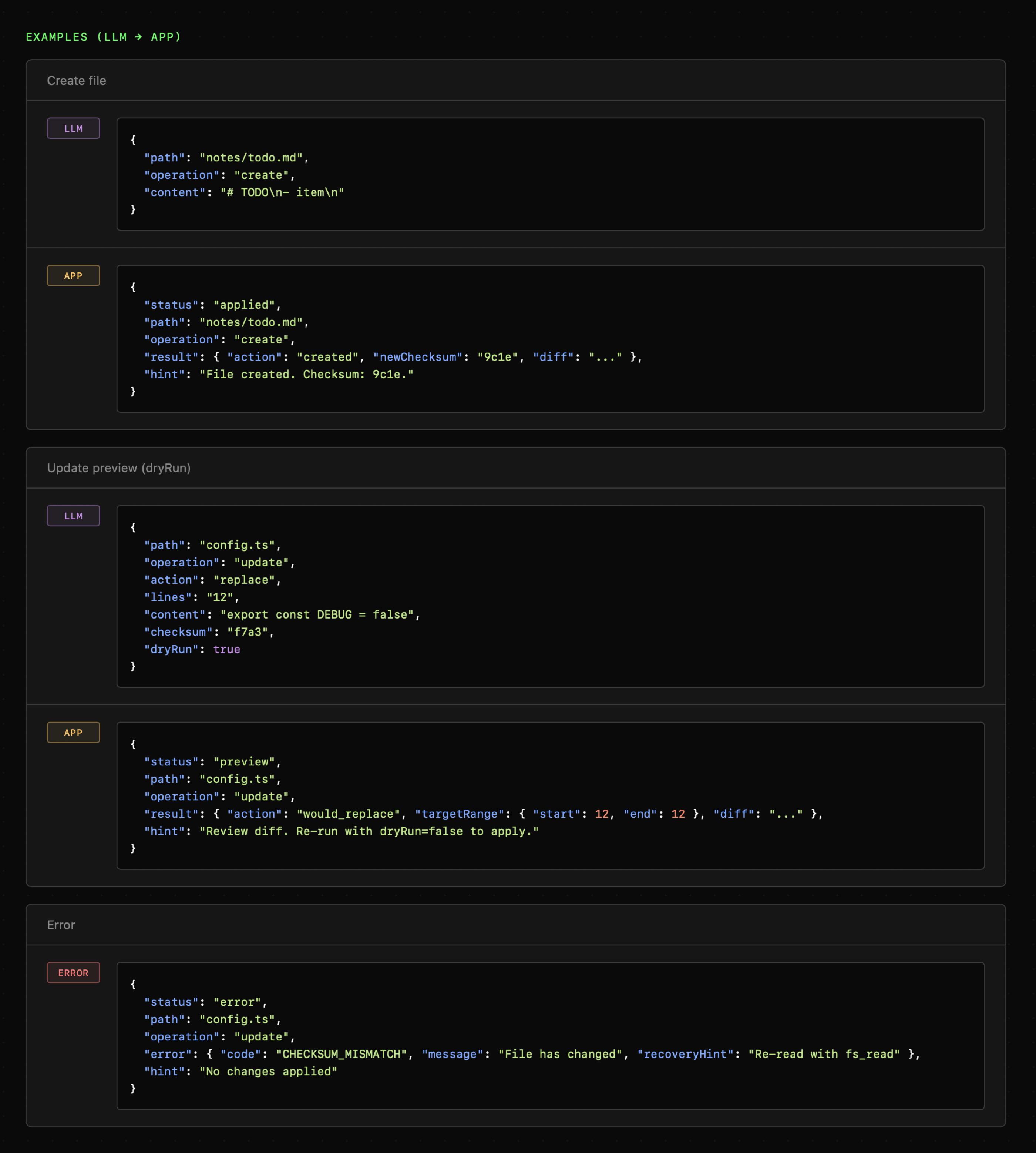
W przypadku akcji „stratnych”, takich jak zapisywanie czy edycja, warto zadbać o możliwość przywrócenia błędnych modyfikacji. Powinno się to odbywać bez angażowania modelu, na przykład poprzez przechowywanie historii wprowadzanych zmian.
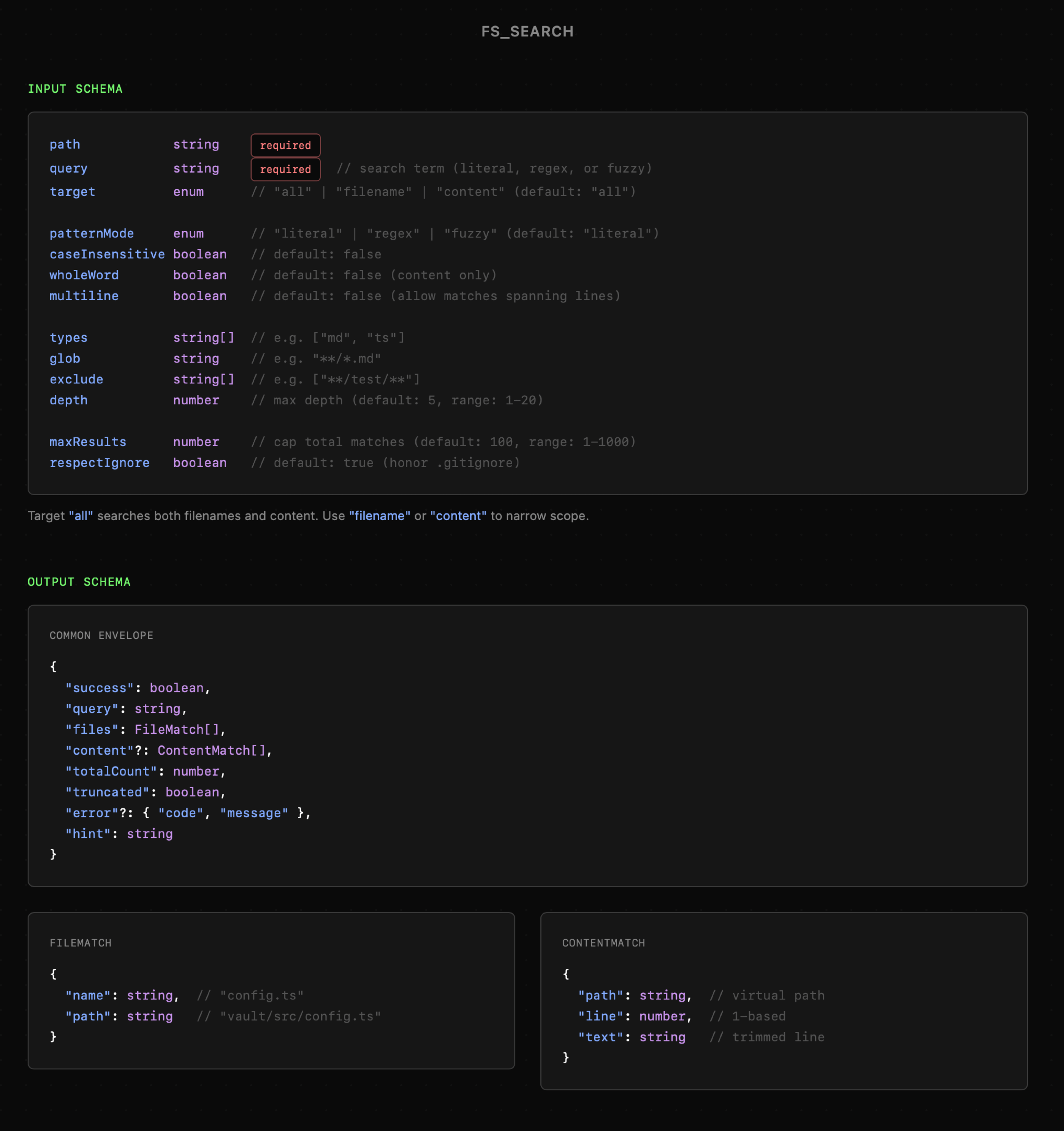
Narzędzia fs_search i fs_manage budowane są według tych samych zasad. Dołączam jednak ich schematy do wglądu na poniższych grafikach, bo warto zwrócić uwagę szczególnie na nazwy właściwości, ich domyślne ustawienia oraz opcje konfiguracji. W przypadku fs_search mówimy także o możliwości dopasowania zarówno nazw plików, jak i fragmentów treści, co zwiększa elastyczność i potencjalnie skuteczność wyszukiwania.
Na koniec mamy jeszcze fs_manage, w którego przypadku możemy nawet usuwać pliki. Warto się zastanowić czy w ogóle chcemy dawać agentowi taką możliwość, ale w tym przypadku i tak została ona ograniczona do pojedynczego pliku oraz wyłącznie pustych katalogów. W niektórych aplikacjach możemy tu jeszcze rozważyć koncepcję "kosza" bądź rodzaju archiwum, co pozwoli na łatwe przywrócenie usuniętych treści.
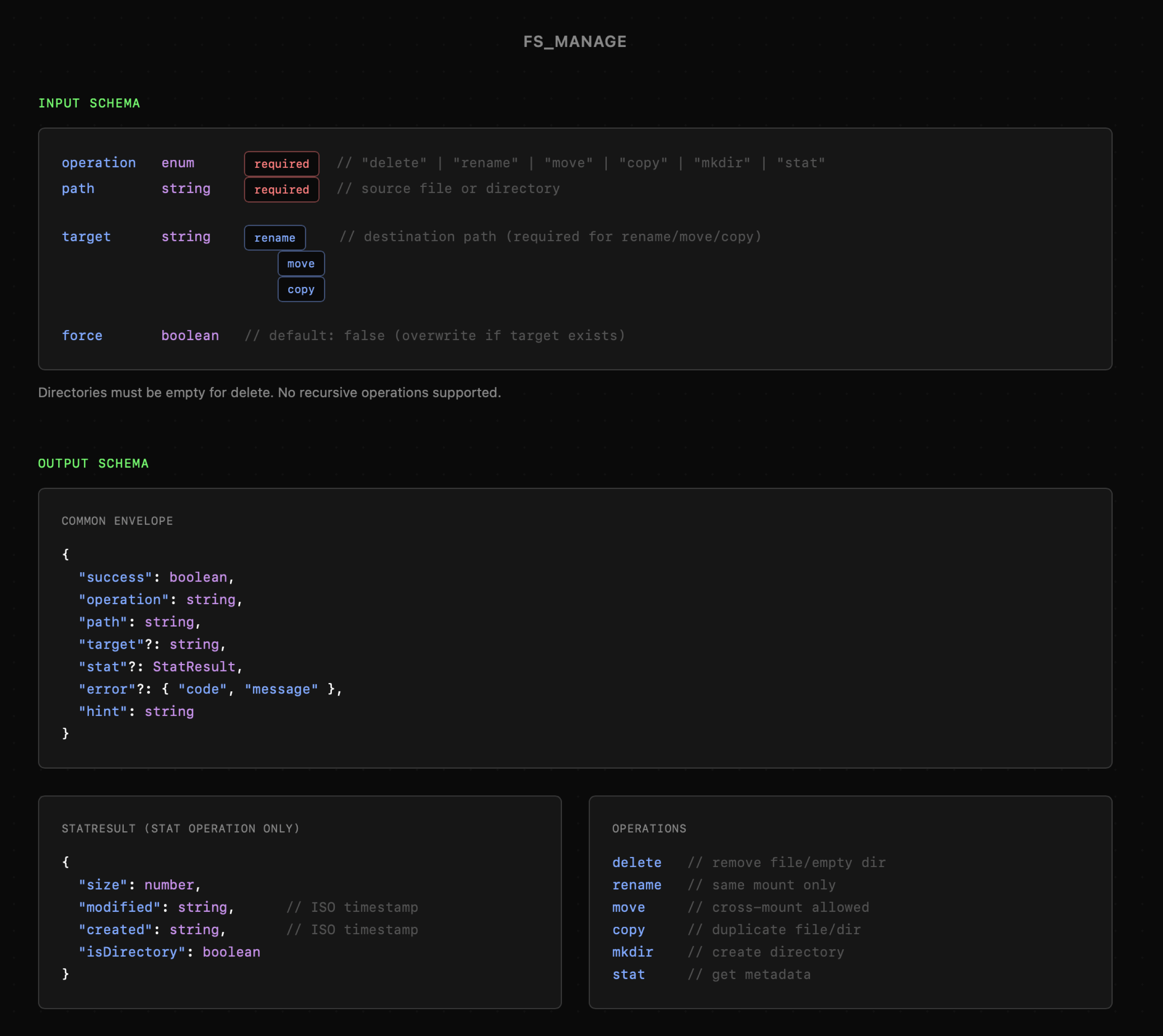
Powyższe przykłady oddają zasady, którymi możemy kierować się przy projektowaniu narzędzi dla dowolnych integracji. Z powodzeniem można je także wykorzystać przy projektowaniu API, aby ułatwić późniejszą integrację z modelami językowymi.
Projektowanie dynamicznych odpowiedzi sukcesu oraz błędów
Niemal w każdej akcji dodaję pole hints bądź recoveryHints, których treść jest zaprojektowana dla modelu w celu ułatwienia kolejnych działań. Choć dobre praktyki projektowania API mówią o tym, abyśmy informowali użytkownika o błędach, tak tutaj warto wspierać model również wtedy, gdy wszystko idzie zgodnie z planem.
Można pomyśleć, że przy obecnym rozwoju modeli, taka praktyka przestanie mieć sens i do pewnego stopnia jest to prawda. Jednak nawet wtedy część z tych wiadomości będzie użyteczna ze względu na kontekst, który nie zależy bezpośrednio od poziomu inteligencji modelu, lecz informacji z otoczenia. Mowa na przykład o wiedzy na temat ograniczeń uprawnień, które ujawniają się dopiero w wyniku podjęcia działań, jak chociażby duża liczba plików w przeszukiwanym katalogu.
Całość układa nam się w następujące zasady:
- Błąd operacji powinien mówić nie tylko o tym, co się stało, ale też o tym, co można z tym zrobić. Na przykład "Treść pliku została zaktualizowana. Przeczytaj go ponownie."
- Status zasobu wymagający szczególnych ustawień, powinien zostać zakomunikowany. Np. wyszukanie dokumentu może zawierać informację: "Dokument istnieje, ale jest chroniony przed zapisem przez ustawienia użytkownika."
- Sugestie dalszych kroków po poprawnej akcji, mogą pomóc uniknąć agentowi niepotrzebnych kroków. Np. "Znaleziono 3 dokumenty. Przed ich edycją wczytaj wcześniej ich treść."
- Błędnie ustalone wartości powinny sugerować dostępne opcje, np. "Błędny rodzaj etykiety. Dostępne etykiety to: 'X, Y, Z'".
- Informacje o korektach wprowadzonych przez narzędzia, np. "Żądano wczytania zakresu linii 48–70, ale dokument ma tylko 59 linii. Wczytano dostępny zakres 48–59."
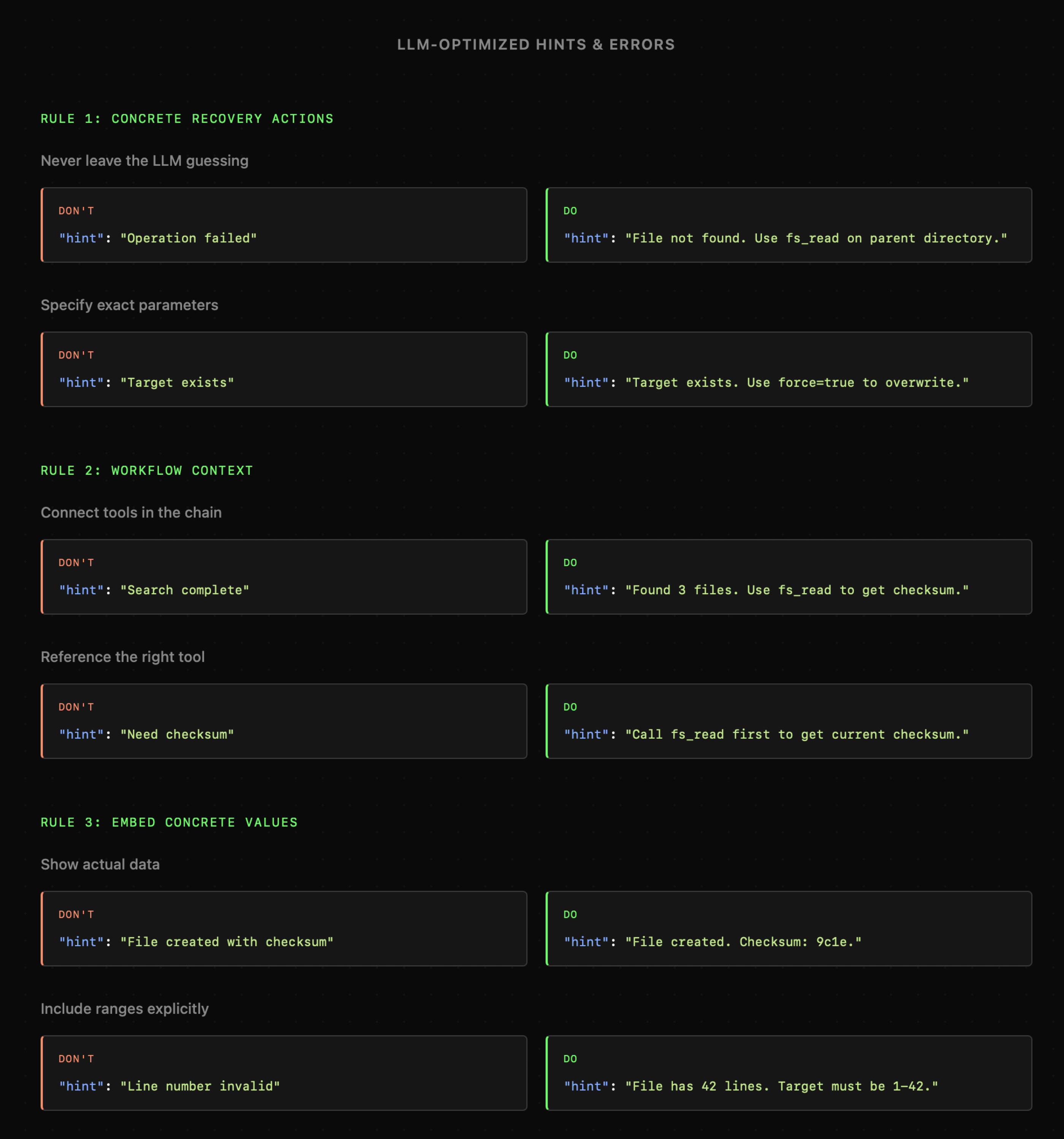
Powyższe dynamiczne komunikaty generowane z pomocą kodu zawsze będą oznaczały jego znacznie większą złożoność. W końcu generyczne komunikaty błędów API nie wynikają z intencji programistów, lecz tego, że wymagają napisania wysokiej jakości kodu, co zwykle zajmowało mnóstwo czasu.
Chociażby rozszerzenie logiki skanowania katalogów o pełne raportowanie nie tylko rezultatów ale też statusów dla poszczególnych rezultatów, zwiększa złożoność aplikacji oraz wymagane zaangażowanie na etapie jej planowania.
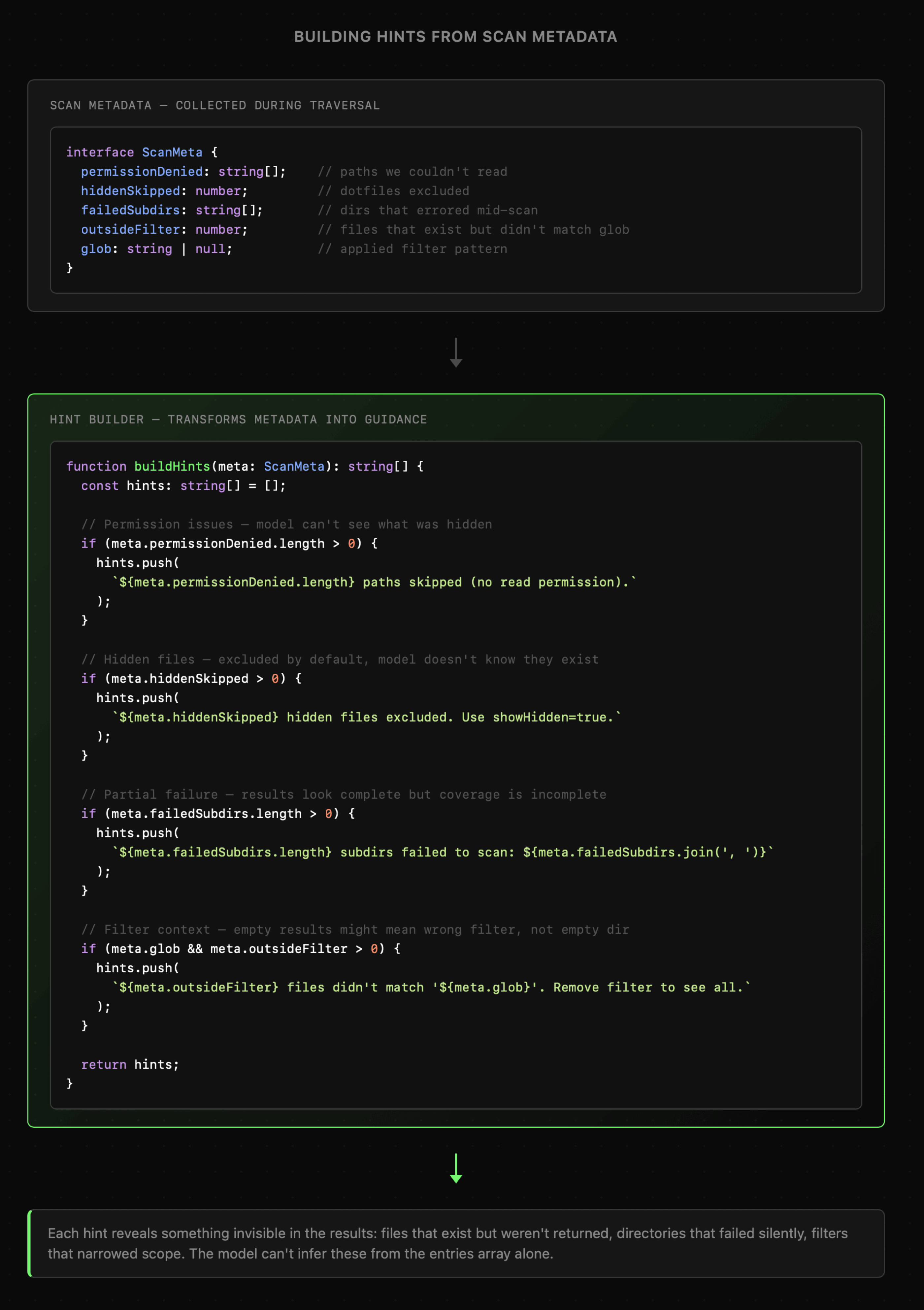
Obecnie jednak nie należy z tego rezygnować bo zarówno etap planowania jak i implementacji może być znacznie ułatwiony przez współpracę z AI. Generowanie przypadków użycia, testów oraz samego kodu, w tym także wielokrotne iterowanie leży w zasięgu nawet pojedynczych developerów i małych zespołów.
Tymczasem kod źródłowy narzędzi do zarządzania systemem plików, które omówiliśmy do tej pory można znaleźć na moim GitHubie w repozytorium files-stdio-mcp-server. Na tym etapie można się zapoznać przede wszystkim z katalogiem src/tools ponieważ reszta dotyczy Model Context Protocol o którym powiemy sobie za chwilę.
Model Context Protocol vs własna implementacja
Model Context Protocol został zaproponowany przez Anthropic w listopadzie 2024, jako odpowiedź na problem łączenia LLM i agentów AI z otoczeniem. Problem ten polega na konieczności tworzenia od podstaw integracji i narzędzi Function Calling / Tool Use, czyli dokładnie tego o czym do tej pory rozmawialiśmy w lekcjach.
Choć Function Calling jest dostępny u każdego providera, tak formaty API różnią się od siebie. Podobnie też obsługa narzędzi jest inaczej implementowana w Claude Code, Claude, ChatGPT czy Cursor. Zatem jeśli chcemy sprawić by agenci AI mieli dostęp do naszego serwisu, musielibyśmy tworzyć dedykowane rozwiązania dla każdego z klientów. Natomiast dzięki MCP sprawiamy, że raz stworzoną integrację można łatwo podłączyć niemal wszędzie.
Model Context Protocol wymaga, aby nasza aplikacja stała się hostem umożliwiającym tworzenie połączeń (tzw. client) z zewnętrznym procesem lub aplikacją określaną jako server. Wszystkie trzy koncepcje (host/client/server) stanowią fundament protokołu.
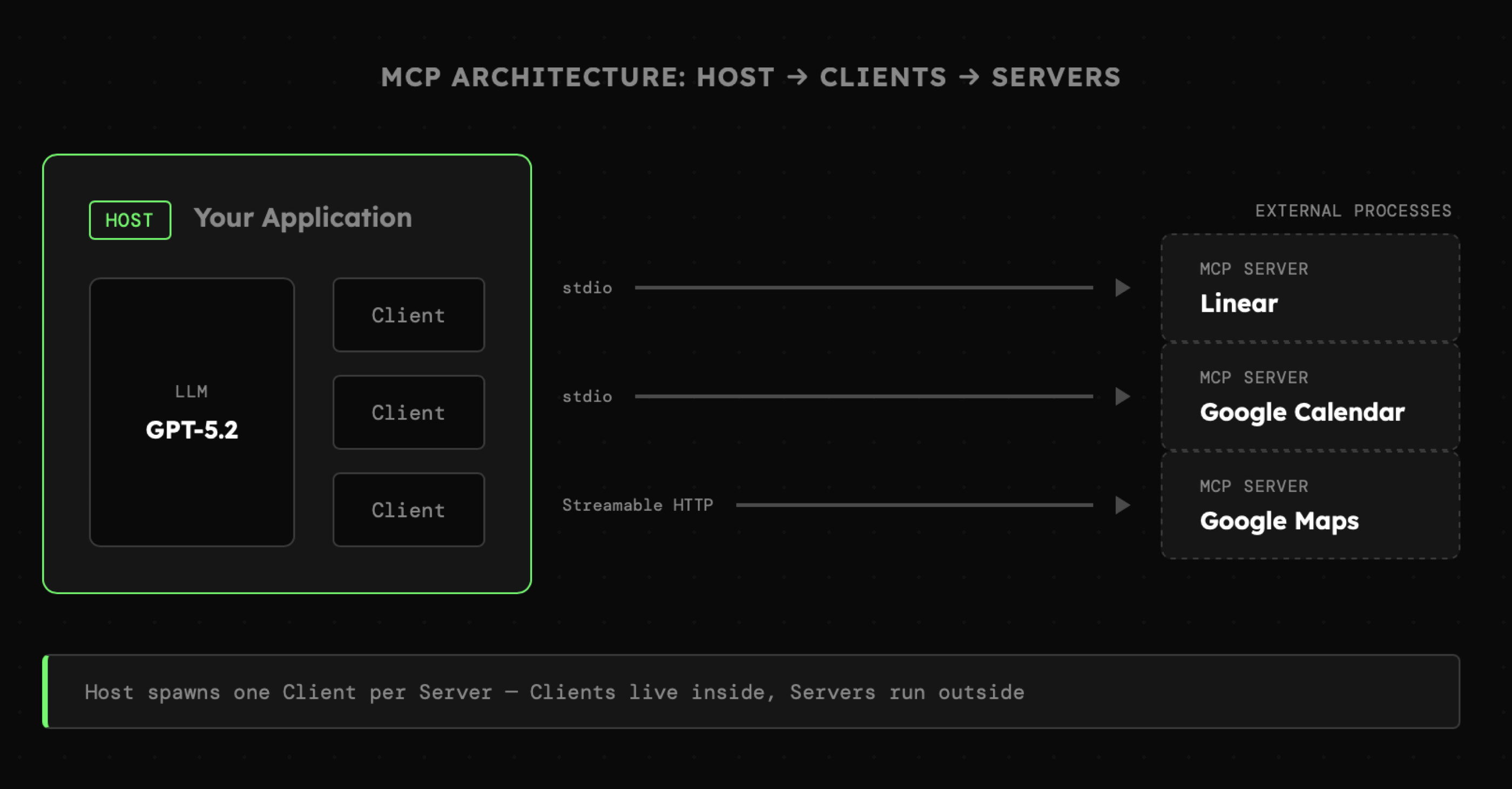
Aby to lepiej zrozumieć, spójrzmy na przykład 01_03_mcp_native. Jest to prosta aplikacja spełniająca definicję hosta, ponieważ pozwala na tworzenie połączeń za które odpowiada client. Jedynie fizycznie server znajduje się w tym samym katalogu, natomiast równie dobrze może być przeniesiony w inne miejsce.
Tymczasem nasz host składa się z następujących elementów:
- Natywne narzędzia: czyli schematy i definicje dla Function Calling. Nie mają one nic wspólnego z MCP, ale celowo umieszczam je w przykładzie, aby pokazać, że korzystanie z MCP nie jest konieczne, a protokół nie musi stanowić alternatywy, lecz funkcjonować wspólnie z wbudowanymi narzędziami.
- Narzędzia MCP: z technicznego punktu widzenia są one takie same, jak natywne narzędzia. Po prostu w tym przypadku nie są one częścią kodu źródłowego aplikacji (Hosta), lecz są dostarczone przez połączenie (Client) bezpośrednio z Serwera MCP.
- Połączenie schematów z obu źródeł: skoro zarówno natywne narzędzia, jak i narzędzia udostępnione przez MCP są tym samym, to możemy połączyć je w jedną listę.
- Połączenie handler'ów z obu źródeł: podobnie jak ze schematami, handler'y również mogą trafić na tę samą listę.
- Dostarczenie schematów Function Calling: dzięki połączeniu schematów narzędzi, do modelu trafiają one dokładnie w tej samej formie.
- Wywołanie handler'ów: gdy agent zdecyduje o uruchomieniu danego narzędzia, to łatwo możemy je odnaleźć.
Całość prezentuje się następująco:
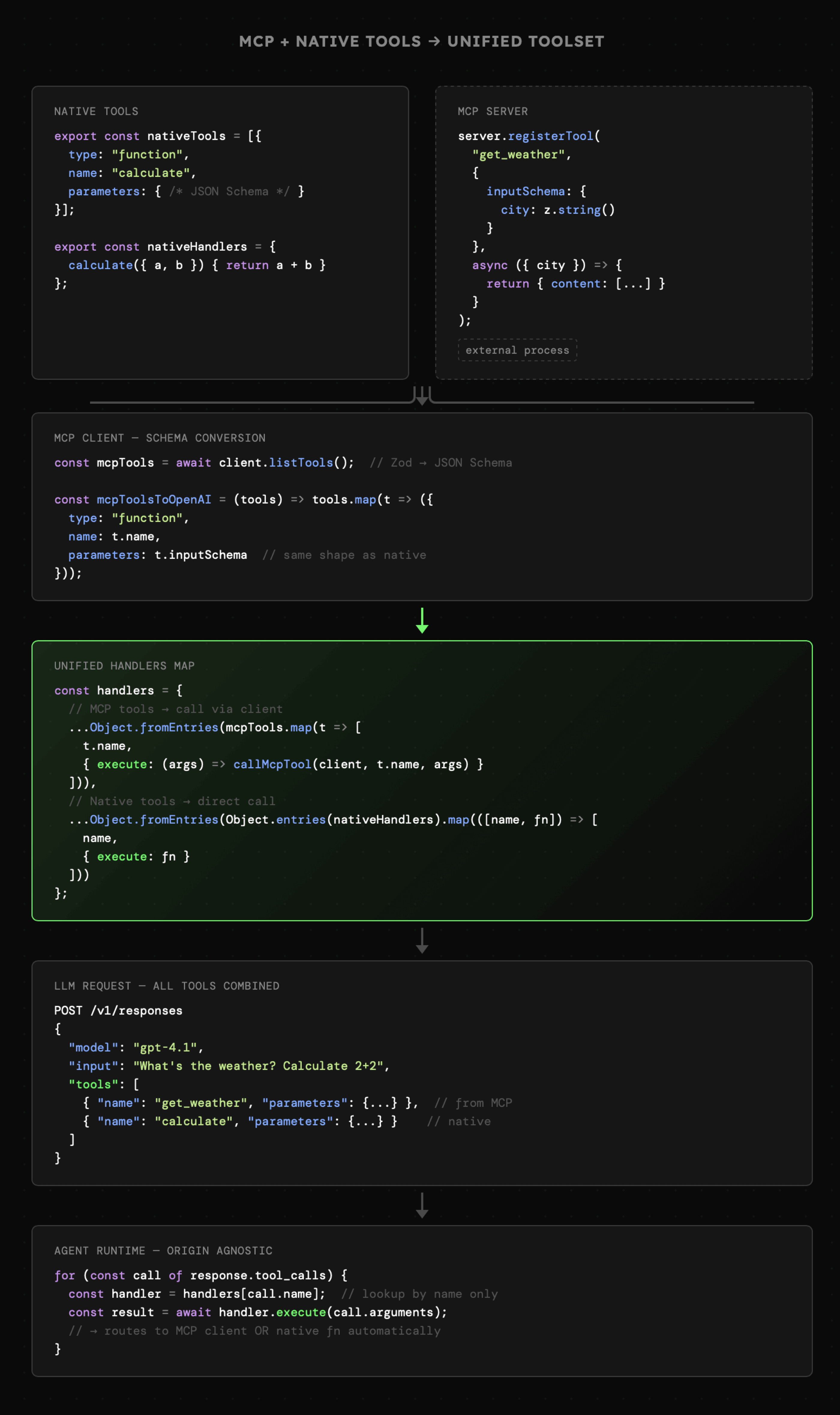
Przekładając to na interakcję widzimy, że z perspektywy agenta źródło pochodzenia narzędzi nie ma znaczenia. Czyli z tej perspektywy Model Context Protocol dotyczy sposobu przechowywania i dostarczania narzędzi w spójnej formie*, dzięki czemu możemy łatwo podłączać serwery MCP do różnych Hostów, np. Claude Code, Cursor czy ChatGPT.
Nim przejdziemy dalej, dodam tylko, że narzędzia nie są jedynym elementem serwerów MCP. Resztą zajmiemy się niebawem.
Główne komponenty MCP dla STDIO i Streamable HTTP
Model Context Protocol to nie tylko narzędzia dla agentów, ale także:
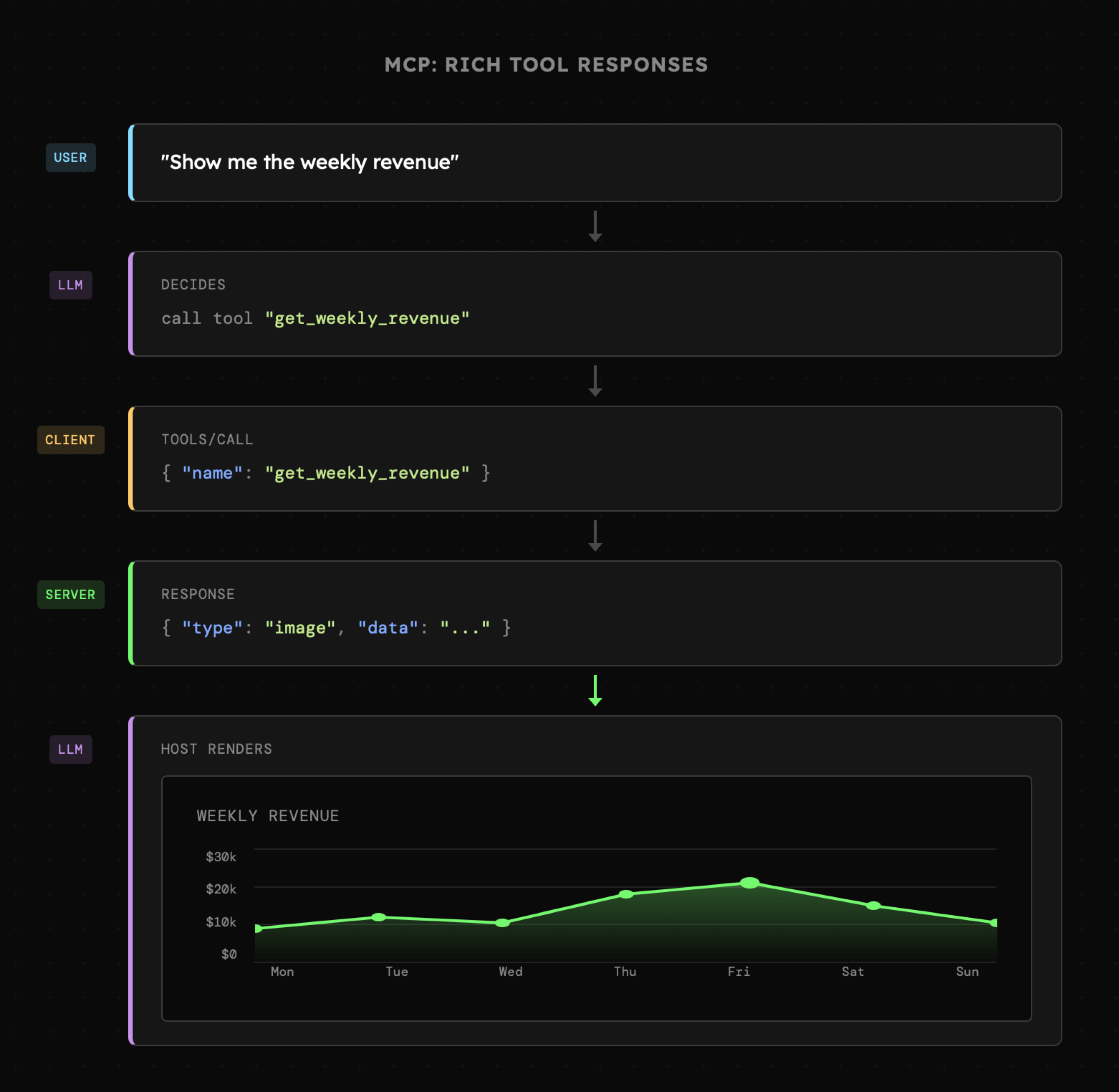
- Apps: czyli interaktywne interfejsy zwracane w odpowiedzi agenta, obejmujące nie tylko wyświetlanie danych, ale także możliwość wykonywania akcji bez opuszczania aplikacji klienta.
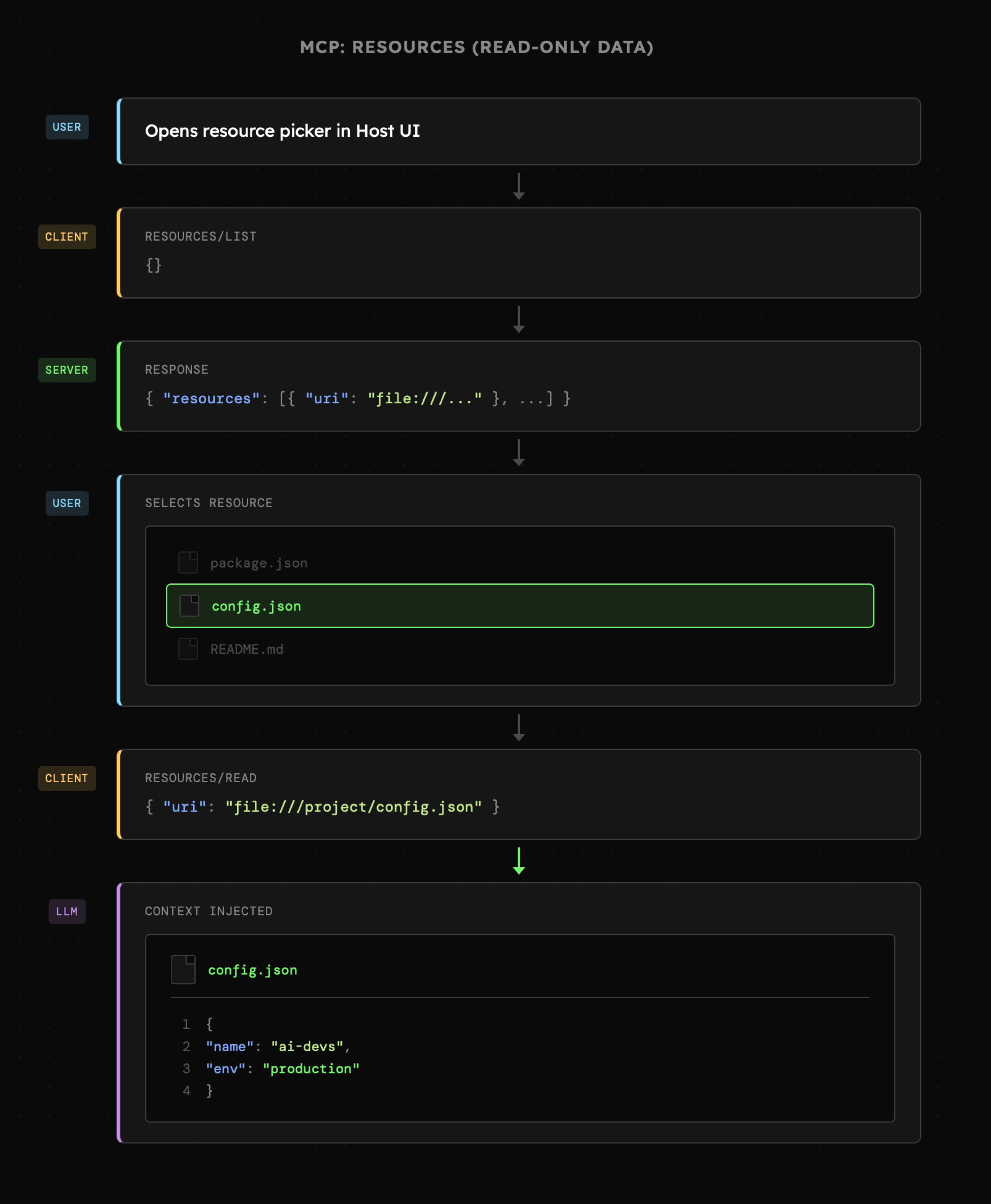
- Resources: Statyczne bądź dynamiczne dane do odczytu, np. pliki tekstowe, obrazy czy listy zasobów (np. /users). Ich sposób aktywacji podczas interakcji nie jest zdefiniowany i może być uzależniony zarówno od interfejsu użytkownika, jak i od decyzji agenta.
- Prompts: to predefiniowane instrukcje, mogące zawierać dynamiczne elementy. Ich aktywacja jest uzależniona od użytkownika, który może wybrać je np. z listy dostępnych komend.
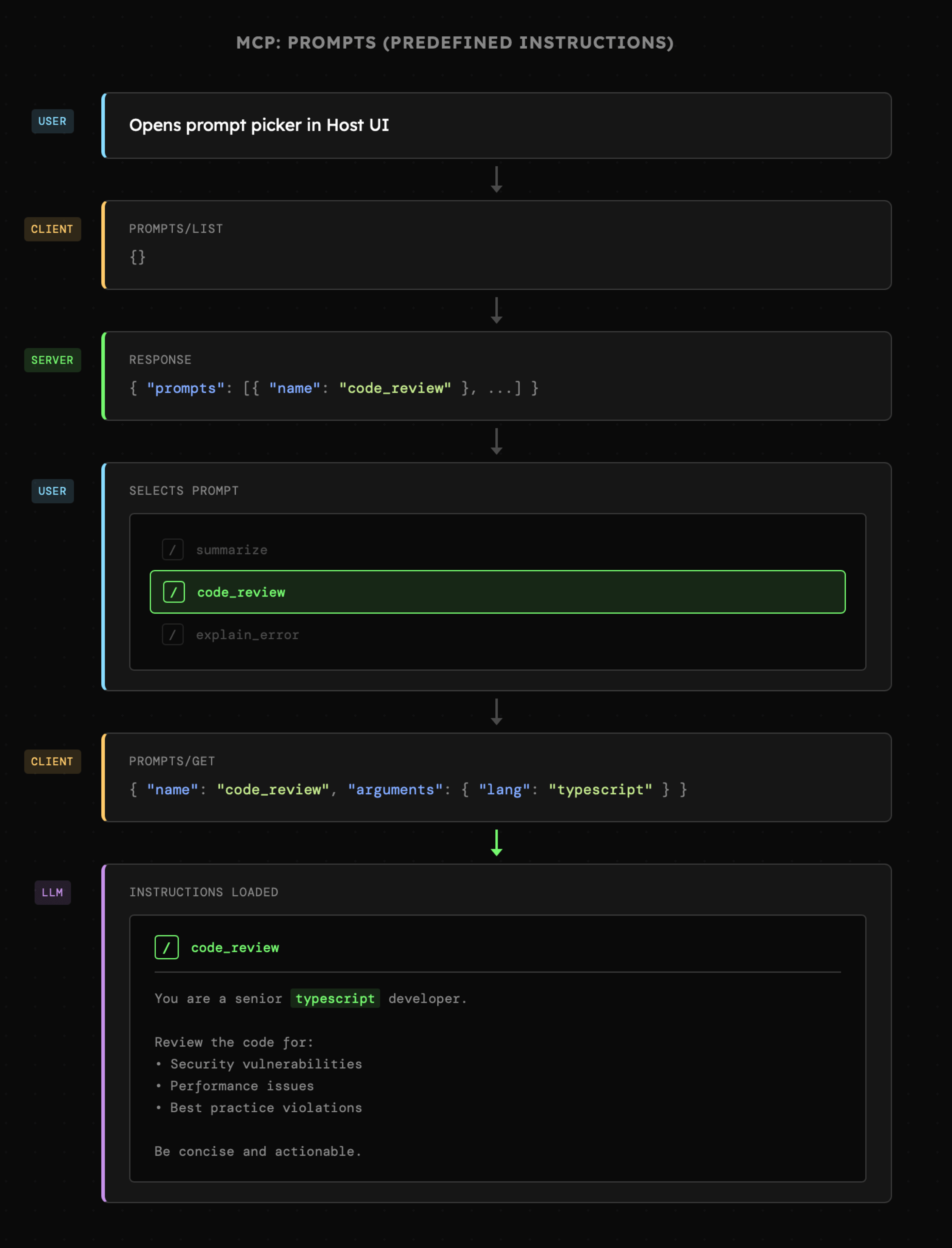
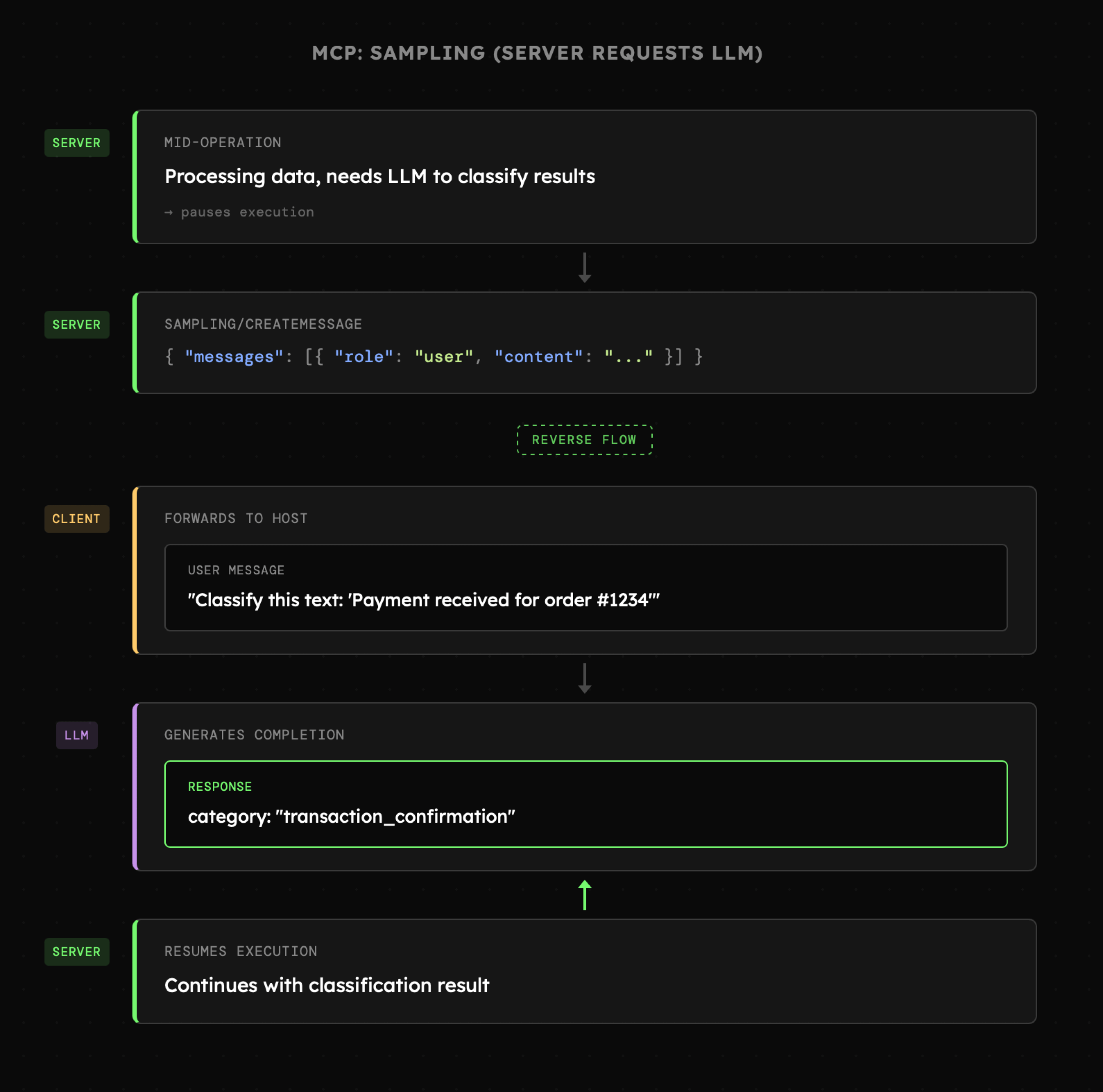
- Sampling: to możliwość odwróconej interakcji w której to Serwer MCP przesyła żądanie, które ma zostać przesłane do modelu. Interakcja ta wymaga bezwzględnej akceptacji ze strony użytkownika.
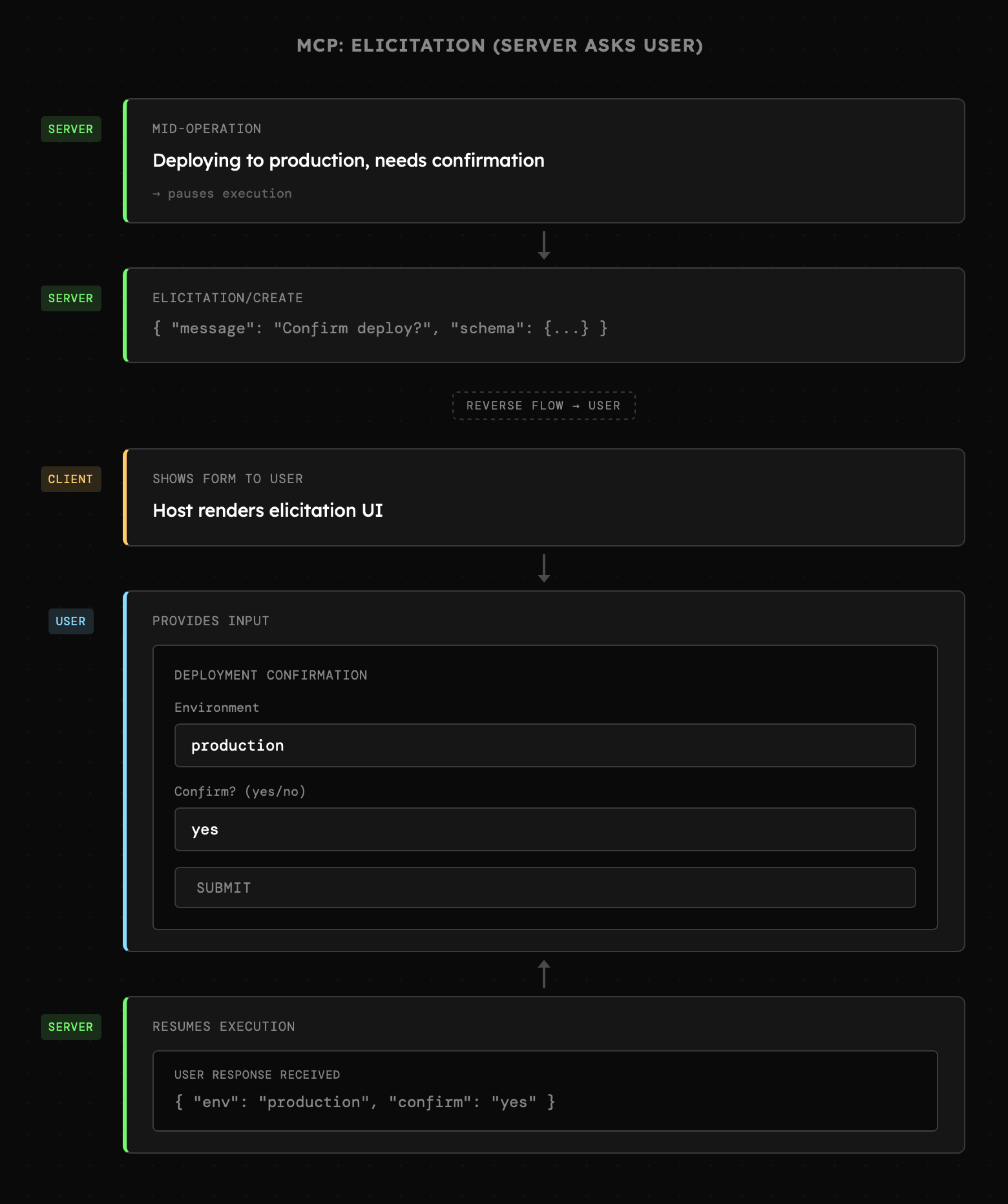
- Elicitation: podobnie jak sampling, to możliwość odwróconej komunikacji, ale w tym przypadku kierowanej do użytkownika, np. uzupełnienie formularza bądź wykonania zewnętrznej akcji w przeglądarce.
Obecnie większość serwerów MCP w ogóle nie wykorzystuje powyższych możliwości. Wsparcie po stronie klientów również bywa zazwyczaj ograniczone, lecz ostatnio pojawia się coraz więcej aplikacji oferujących pełną obsługę całego protokołu. Zauważalne są także przykłady serwerów MCP, które wykraczają poza udostępnianie wyłącznie narzędzi.
W przykładzie S01E03_mcp_core znajduje się serwer MCP, który można podłączyć pod MCP Inspector, czyli narzędzie do testowania serwerów MCP. Wystarczy w ustawieniach połączenia wskazać Transport Type na STDIO, Command na node oraz Arguments na ścieżkę do pliku /01_03_mcp_core/src/mcp/server.js. Alternatywnie przykład można uruchomić także poleceniem npm start.
Poza głównymi komponentami protokołu MCP ważne są także sposoby komunikacji client - server. Jest to albo STDIO dla procesów lokalnych albo Streamable HTTP dla serwerów zdalnych. Różnica pomiędzy nimi jest taka, że:
- STDIO: wykorzystamy tam, gdzie zależy nam na interakcji z lokalnym systemem plików bądź narzędziami dostępnymi na maszynie, na której uruchomiony jest dany serwer MCP, np. ffmpeg. STDIO sprawdza się zatem najlepiej w aplikacjach desktopowych, w których serwer obsługuje tylko jednego użytkownika (ponieważ każde połączenie oznacza, konieczność utworzenia nowego procesu).
- Streamable HTTP: powinien być wybierany domyślnie przy budowie serwerów MCP. Dzięki temu możemy uruchomić je na VPS czy Cloudflare Workers oraz obsługiwać sesje użytkowników, wliczając w to także OAuth 2.1.
Projekt klienta oraz serwera MCP na back-endzie
Host MCP utożsamiany jest z aplikacją webową bądź desktopową, np. Claude. Natomiast Model Context Protocol może być zintegrowany na back-endzie, bez jakiegokolwiek graficznego interfejsu. Już nawet przykład 01_03_mcp_core pokazuje nam, że jest to możliwe, ale teraz przejdziemy przez nieco bardziej rozbudowaną aplikację wykorzystującą Files MCP o którym rozmawialiśmy wcześniej.
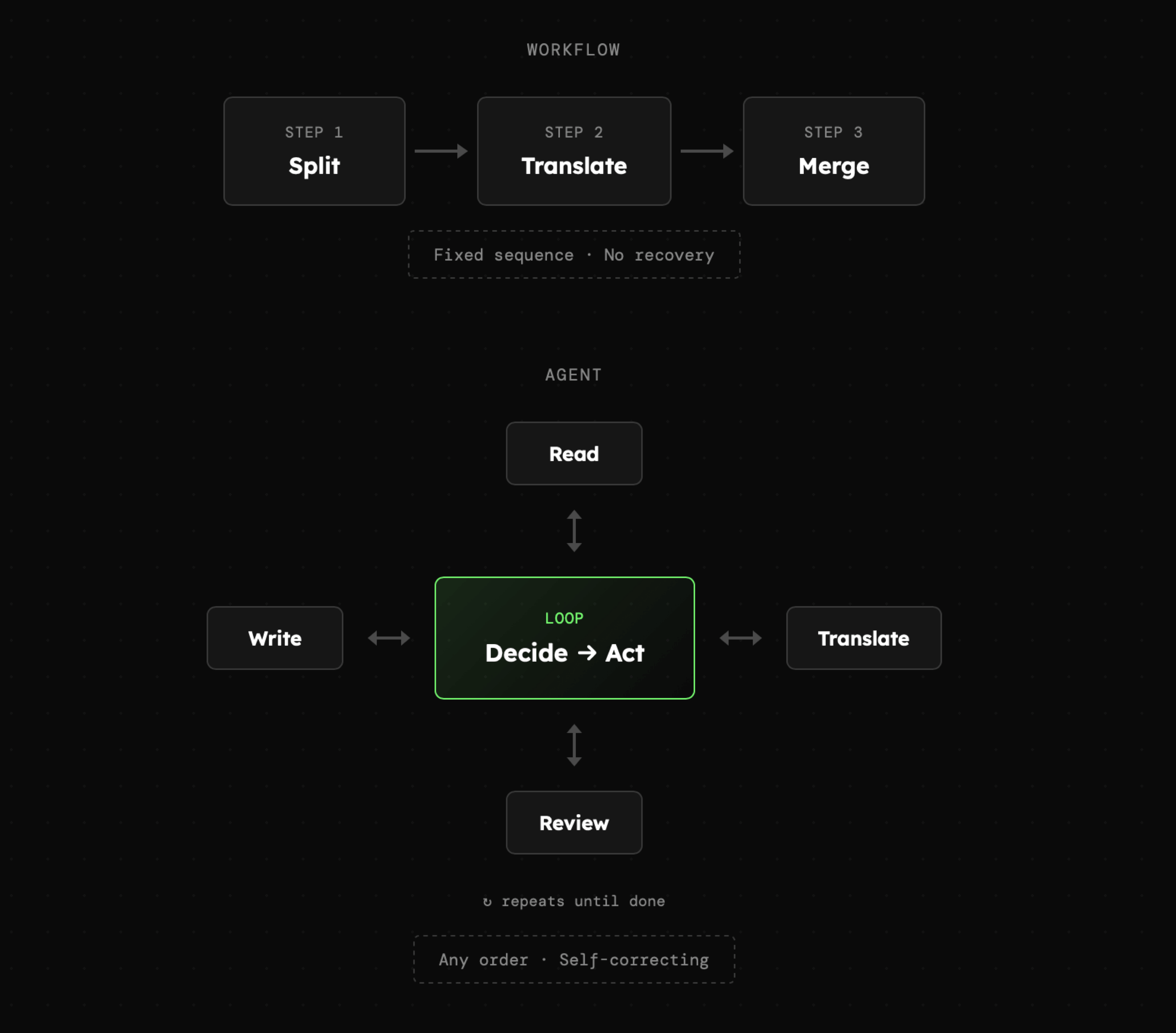
Naszym celem będzie stworzenie agenta tłumaczącego dokumenty tekstowe z pomocą narzędzi umożliwiających mu interakcję z systemem plików. Taki tłumacz teoretycznie mógłby mieć formę zwykłego workflow w którym:
- Dokument byłby podzielony na mniejsze fragmenty.
- Każdy fragment zostałby tłumaczony przez LLM
- Przetłumaczone fragmenty byłyby połączone w dokument końcowy
Takie podejście może się sprawdzić, ale jego ograniczeniem jest brak możliwości zareagowania na np. błąd tłumaczenia bądź formatowania fragmentu, który został już zapisany. W przypadku agenta AI, ma on możliwość skanowania dokumentu w dowolny sposób, a także weryfikowania wyników czy wprowadzania poprawek. Struktura agenta wygląda zatem następująco:
- Podłączenie narzędzi z Files MCP do interakcji z systemem plików
- Otrzymanie informacji o nowym pliku do przetłumaczenia
- Zapoznanie się z dokumentem, rozpoczęcie tłumaczenia, weryfikacja, poprawki i potwierdzenie wykonania zadania. Tutaj jednak część akcji jest opcjonalna i może być uruchomiona w dowolnej kolejności.
Poniższa wizualizacja przedstawia różnicę między dwoma podejściami, która jasno sugeruje, że w pierwszym przypadku mamy dużą kontrolę, ale niską elastyczność, a w drugim sytuacja jest odwrotna: zyskujemy wysoką dynamikę, lecz pojawia się zarówno ryzyko błędu, jak i szansa na znacznie lepsze rezultaty.
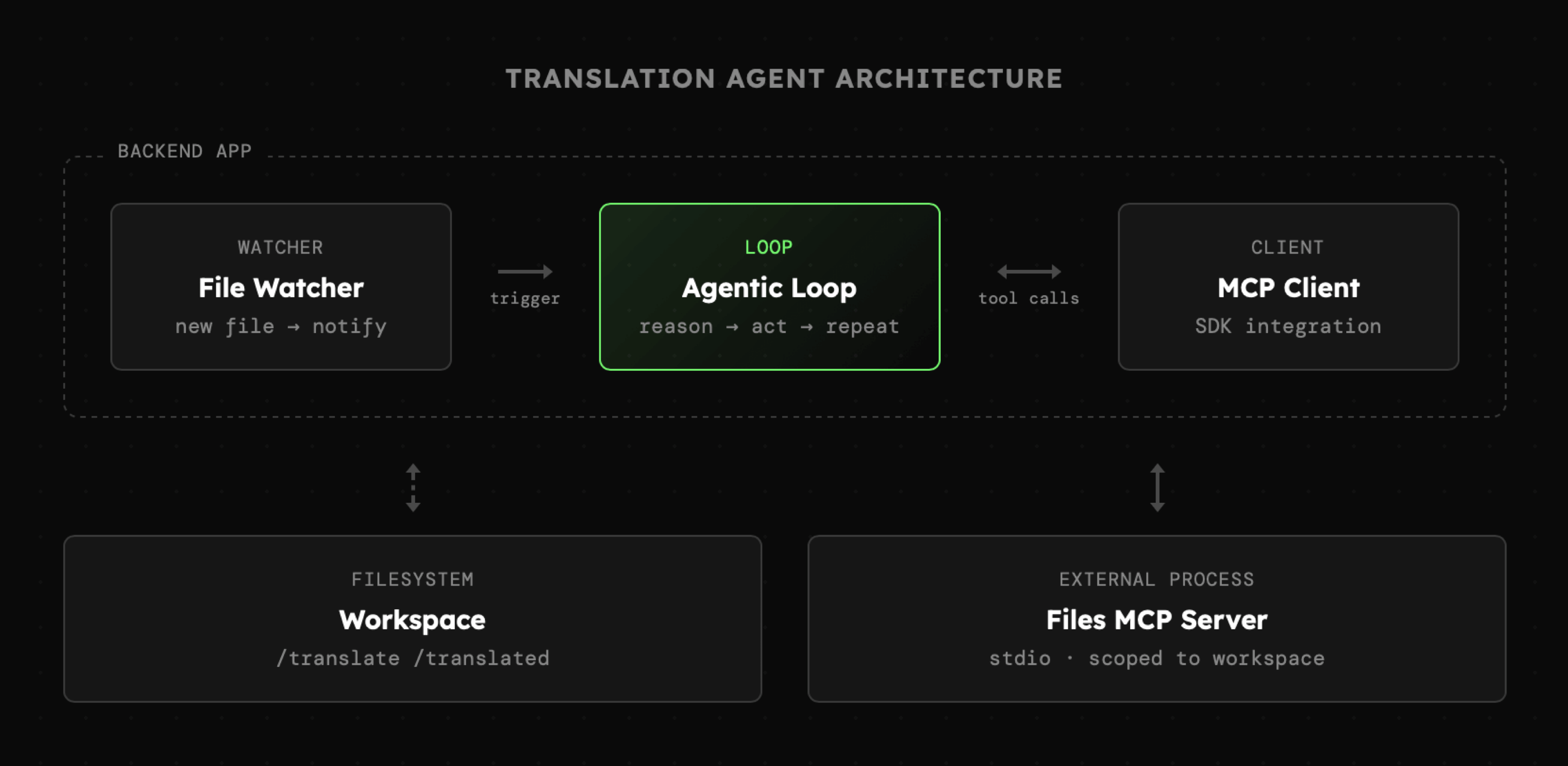
Nasz agent będzie składał się z trzech głównych elementów:
- Pętli obserwującej zawartość katalogów translate / translated, która powiadomi agenta o nowych plikach do tłumaczenia.
- Klienta MCP, dzięki któremu nawiążemy połączenie z serwerem Files MCP i tym samym uzyskamy dostęp do narzędzi do interakcji z systemem plików ograniczonej do katalogu workspace.
- Pętli agenta, którego zadaniem będzie wykorzystanie dostępnych narzędzi do przeprowadzenia tłumaczenia otrzymanego dokumentu. W instrukcji systemowej agenta pojawią się więc ogólne zasady oraz schematy, które chcemy uwzględnić w działaniu agenta, ale sposób wykonania zadania będzie uzależniony od modelu. To bardzo istotna różnica, ponieważ jeśli chcemy aby agent zawsze zrealizował zadanie według ustalonych kroków, to wówczas powinniśmy zastanowić się czy nie lepiej jest zbudować AI workflow.
Także system plików oraz proces serwera MCP udostępniającego narzędzia technicznie znajdują się "poza aplikacją", ale są z nią połączone. Widzimy także, że MCP Client stanowi część naszej aplikacji, a to oznacza, że spełnia ona definicję MCP Host, pomimo tego, że nie posiada graficznego interfejsu.
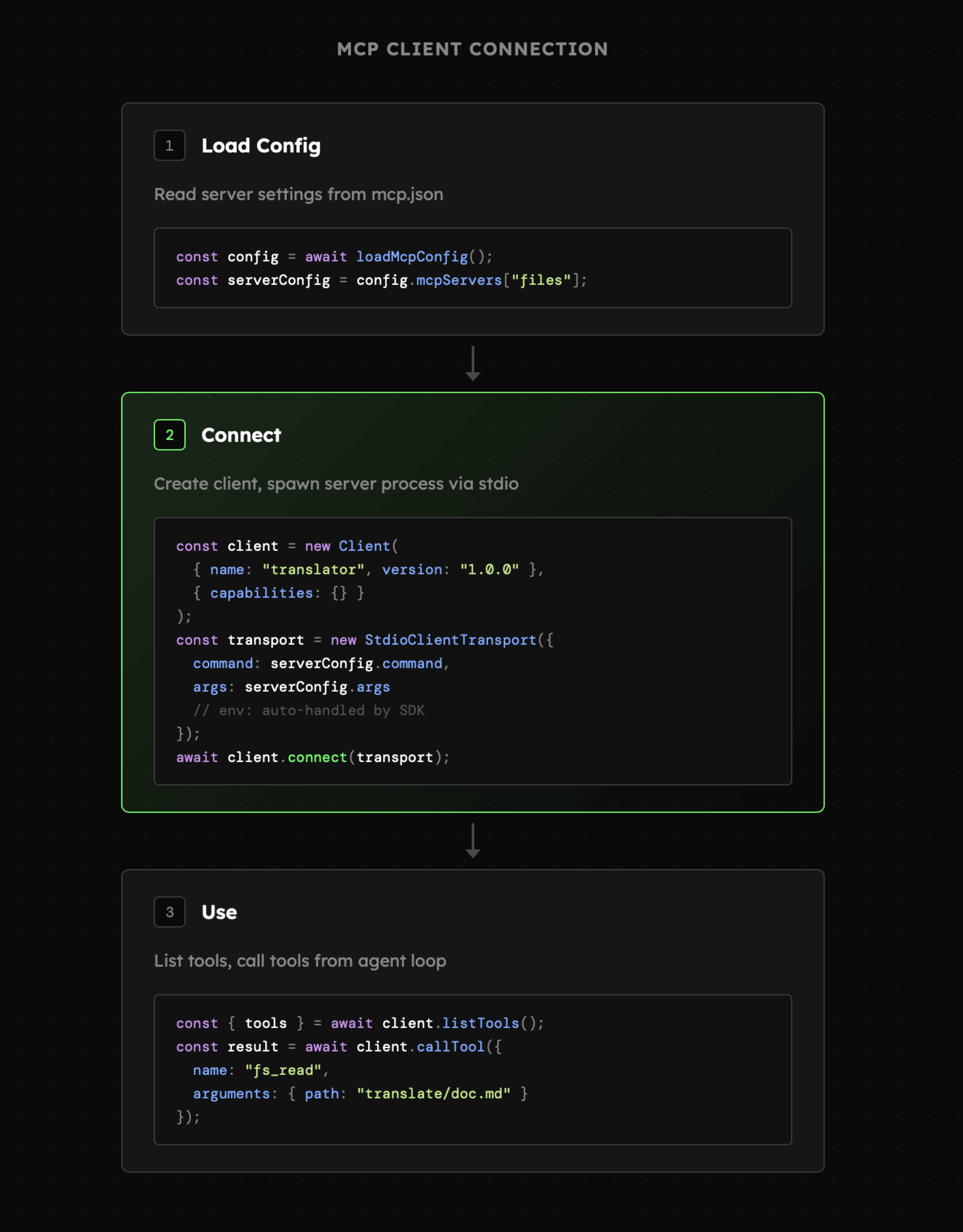
Połączenie MCP Client - Server jest dla nas nowym elementem, więc przyjrzyjmy się mu bliżej. Mowa konkretnie o pliku client.js w którym:
- Konfiguracja: wczytujemy plik mcp.json z obiektem konfiguracyjnym serwerów MCP z którymi chcemy się połączyć. W tym przypadku jest to serwer STDIO.
- Połączenie: tworzymy połączenie, którym zarządza klient. Przekazujemy tu argumenty, zmienne środowiskowe, a w zamian otrzymujemy połączenie z serwerem MCP.
- Komunikacja: klient w każdej chwili może poprosić serwer o zwrócenie listy dostępnych narzędzi, być poinformowany o zmianach oraz wykonywać wskazane przez agenta funkcje.
Całość znajduje się w przykładzie 01_03_mcp_translator, który po uruchomieniu przetłumaczy przykładowy dokument, który zostanie zapisany w katalogu workspace/translated. Podobnie też jeśli dodamy nowy plik tekstowy do katalogu workspace/translate, agent na niego zareaguje i rozpocznie przetwarzanie.
Budowanie serwerów MCP ze schematami „spec-driven”
Tworzenie serwerów MCP na tym etapie może wydawać się bardzo proste i takie jest, jeśli mówimy o prostych interakcjach. Jeśli jednak podejdziemy do tego na poważnie, sytuacje się komplikuje. Z tego powodu przygotowałem na swoje potrzeby szablon serwera MCP dla transportu Streamable HTTP. Szablon ten wykorzystuję do budowania integracji na swoje potrzeby, ale publicznie udostępniam go na swoim Githubie. Naturalnie nie ma konieczności, aby z niego korzystać, ale może stanowić pewien punkt odniesienia. Sam szablon jest napisany w języku TypeScript, ale ogólne zasady pozostaną takie same dla pozostałych języków.
Serwery MCP są zwykle bardzo powtarzalne pod kątem ogólnej architektury, więc zastosowanie szablonu ma tutaj duży sens. Co więcej, do tworzenia nowych serwerów na jego podstawie niemal w 100% powinniśmy wykorzystać model językowy. Problem w tym, że ich wiedza na temat wciąż kształtującego się protokołu może być nieaktualna, więc oprzemy się o dokument README.md oraz manual.md, które powinny być nie tylko wczytane do kontekstu konwersacji z agentem AI (np. Cursor) ale też przypominane możliwie często.
Przejdziemy teraz przez proces tworzenia serwera MCP na podstawie szablonu. Naszym celem będzie zintegrowanie się z narzędziem uploadthing.com dzięki czemu nasz agent zyska możliwość udostępniania plików w formie linków. Serwis ten posiada bezpłatny plan, więc wystarczy jedynie rejestracja konta.
W związku z tym, że obecnie mamy do dyspozycji agentów zdolnych do wykonania nawet złożonych zadań za jednym razem, bądź kilku iteracjach, proces generowania serwerów MCP wygląda następująco:
- Pobierz szablon z repozytorium Streamable MCP Template
- Utwórz dokument API.md z treścią wklejonej dokumentacji narzędzia uploadthing.com
- Zapytaj agenta AI o przeczytanie plików README.md oraz manual.md
- Zapytaj agenta AI o zasugerowanie listy narzędzi MCP, które można utworzyć na podstawie dostępnego API
- Zapoznaj się z listą i zastosuj wskazówki z naszych lekcji, takie jak ograniczenie liczby narzędzi poprzez ich grupowanie bądź odrzucenie niepotrzebnych.
- Zapytaj o strukturę input / output narzędzi, uwzględniając wskazówki z naszych dotychczasowych lekcji
- Poproś o zaimplementowanie
- Zweryfikuj kod i zasugeruj poprawki.
- Poproś o usunięcie niewykorzystywanych elementów szablonu.
W ten sposób możemy zbudować większość spersonalizowanych serwerów MCP. Oczywiście musimy zapoznać się z kodem i wspólne z agentem zastanowić się nad tym, czy implementacja jest poprawna, szczególnie biorąc pod uwagę detale struktur narzędzi. Jednak nawet jeśli będzie wiązało się to z kilkunastoma iteracjami, proces pozostaje taki sam.
Prosty agent korzystający z serwera MCP dla uploadthing dostępny jest w przykładzie 01_03_upload_mcp, po którego uruchomieniu dojdzie do wgrania do chmury plików z katalogu workspace oraz zapisania rezultatu w pliku uploaded.md. Sam serwer będzie przydatny w osobistych automatyzacjach, gdzie często pojawia się konieczność udostępniania plików.
UWAGA: Dla ułatwienia uruchomienia upload_mcp w katalogu mcp/uploadthing-mcp umieściłem przykładową implementację serwera dla uploadthing.com. Należy wspólnie z agentem AI przejść przez jego konfigurację, albo lokalnie, albo przez Cloudflare Workers i następnie w pliku mcp.json uzupełnić adres tego serwera.
Problemy dotyczące bezpieczeństwa oraz prywatności
Generowanie serwerów MCP czy narzędzi dla LLM nie rozwiązuje samoistnie problemów bezpieczeństwa oraz prywatności użytkowników. Co więcej, część z związanych z tym problemów pozostaje otwarta (np. prompt injection) i obecnie nie ma na nie uniwersalnego rozwiązania poza ewentualnym fizycznym ograniczeniem, które jednocześnie zmniejsza możliwości agentów.
Gdy tworzymy narzędzia, czy nawet serwery MCP na potrzeby wewnętrznych systemów, nasz poziom kontroli jest znacznie wyższy, bo:
- Posiadamy kontrolę nad zasobami oraz akcjami dostępnymi w ramach narzędzi
- Znamy listę narzędzi i ich możliwych konfiguracji (np. pobierz dane → wyślij raport)
- Posiadamy wiedzę o procesach realizowanych przez agentów AI oraz roli człowieka
- Możemy nauczyć użytkowników pracy z agentami i wyjaśnić ewentualne problemy
- Przepływ informacji może być ograniczony jedynie do struktur firmowych
Niemal wszystkie te punkty tracą jednak znaczenie, gdy udostępniamy serwer MCP użytkownikom końcowym. Wówczas nie dysponujemy informacjami o hoście, pozostałych narzędziach, realizowanych procesach czy zakresie danych. Nasza wiedza o użytkowniku jest bardzo ograniczona, zatem możemy spodziewać się wszystkiego, włączając w to działania wynikające z negatywnych intencji samej osoby lub płynące z jej otoczenia (np. z otrzymywanych wiadomości e-mail).
Dlatego wszędzie tam, gdzie to możliwe, powinniśmy stosować programistyczne ograniczenia - blokady dostępu, ograniczenie akcji, limity zapytań, dodatkowe weryfikacje, anonimizowanie danych i porządne walidacje to absolutne podstawy. Jednocześnie możemy też dojść do wniosku, że wybrane zasoby i akcje zwyczajnie nie mogą zostać udostępnione agentom AI. Przynajmniej nie na obecnym etapie rozwoju modeli.
Problemy o których tu mówimy co prawda nie wynikają bezpośrednio z Model Context Protocol, bo istnieją już na poziomie Function Calling. Jednocześnie MCP robi stosunkowo niewiele, aby je zaadresować. W dodatku obietnica "podłączenia narzędzi jak przez USB" buduje wysokie oczekiwania biznesu oraz końcowych użytkowników. Musimy więc być świadomi zagrożeń i komunikować je do biznesu posługując się konkretnymi przykładami, a niekiedy także prezentacjami. Jednocześnie warto pozostawać na bieżąco z rozwojem modeli oraz ekosystemu narzędzi, bo część wymienionych problemów za jakiś czas może stracić na znaczeniu.
Autoryzacja serwerów MCP i kontrola uprawnień użytkowników
Autoryzacja serwerów MCP to proces obejmujący zarówno MCP Client jak i MCP Server. Choć może się wydawać, że budowanie aplikacji typu MCP Host (np. Claude) nie będzie nas dotyczyć, tak nawet przykład zastosowania MCP na back-endzie sugeruje coś innego.
Interakcja z serwerem MCP zwykle będzie wymagać podania klucza (lub kluczy) API w celu uzyskania dostępu do samego serwera, bądź powiązanych z nim usług. Nierzadko też serwer MCP będzie wymagał autoryzacji OAuth. W tym pierwszym przypadku za przechowanie kluczy API odpowiada MCP Host i serwer MCP wykorzystuje go jedynie do podjęcia akcji w ramach bieżącego zadania. Oczywiście musimy zadbać o to, aby klucze nie trafiły w niepożądane miejsca, ale sama praca z nimi jest dość prosta.
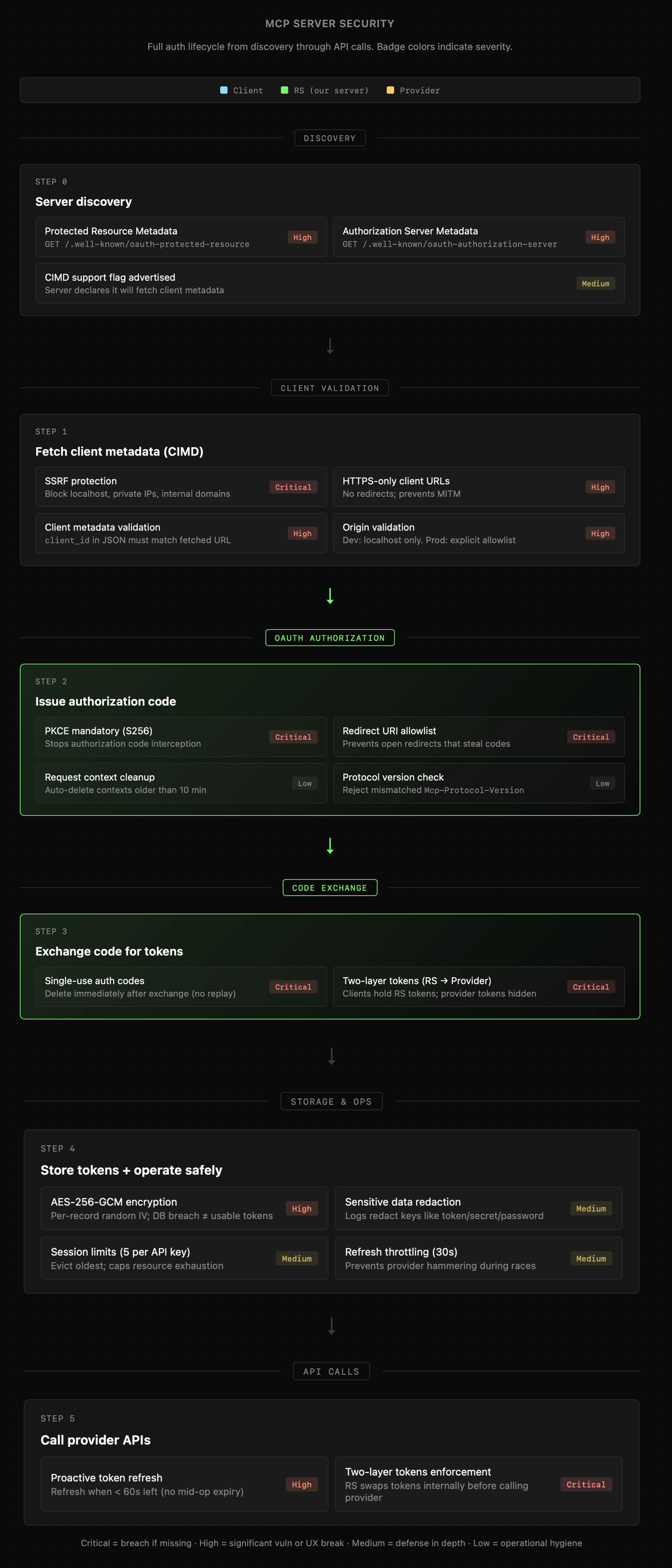
Sytuacja komplikuje się, gdy do gry wchodzi OAuth, ponieważ znacznie zwiększa on złożoność zarówno klienta, jak i serwera. Proces autoryzacji obejmuje wówczas etapy takie jak:
- odkrywanie serwera autoryzującego poprzez metadane
- walidację klienta przez sprawdzenie client_id oraz redirect_uri
- wygenerowanie kodu autoryzacji z weryfikacją PKCE
- wymianę kodu na tokeny RS (klient nie widzi prawdziwych tokenów providera)
- przechowywanie tokenów w zaszyfrowanej formie
- automatyczne odświeżanie tokenów przy wywołaniu akcji
Wszystkie etapy są także widoczne na poniższych wizualizacjach. Choć nie będziemy wchodzić w detale poszczególnych procesów, tak istotne jest tylko zapamiętanie, że muszą być one obecne przy projektowaniu serwerów MCP wykorzystujących OAuth. Kod źródłowy prezentujący implementację OAuth dla serwera MCP znajduje się także w repozytorium z szablonem.
OAuth po stronie hosta / klienta porusza się po tych niemal tych samych etapach, ale bliżej strony użytkownika. Jego zadaniem jest poprowadzenie go przez cały proces oraz poprawna obsługa wymagań ze strony serwera.
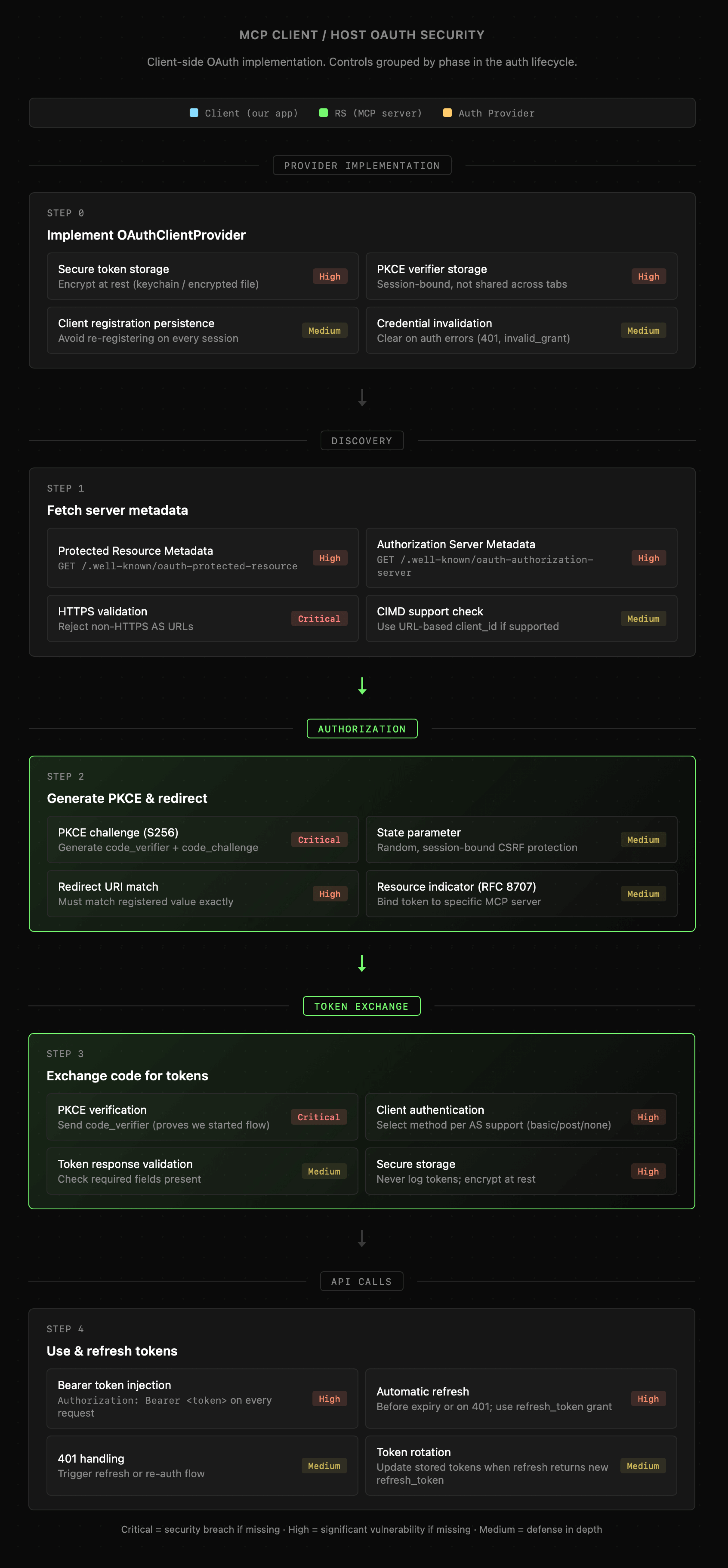
W tej chwili nie będziemy zajmować się budowaniem hostów MCP wykorzystujących OAuth, ale wrócimy do tego w dalszych lekcjach. Tymczasem, posiadając tokeny dostępu bądź klucze API przechodzimy w obszar zarządzania uprawnieniami do zasobów i akcji, który wygląda dokładnie tak, jak w przypadku aplikacji, które tworzymy na co dzień.
Raz jeszcze podkreślę: na tym etapie istotna jest jedynie szeroka perspektywa na proces budowania gotowych produkcyjnie hostów oraz serwerów MCP.
Obsługa dużej liczby narzędzi oraz konfliktów pomiędzy serwerami
Większość hostów umożliwia użytkownikom podłączenie wielu serwerów MCP. Nawet jeśli sami projektujemy aplikacje backendowe wykorzystujące MCP, zależy nam na pracy z licznymi narzędziami. Są to jednak dwie odmienne sytuacje, ponieważ w pierwszym przypadku nie posiadamy żadnych informacji o pozostałych serwerach. Oznacza to, że musimy z góry zapobiegać na przykład konfliktom w nazewnictwie narzędzi. Jednocześnie duża odpowiedzialność spoczywa tutaj na samym hoście oraz sposobie jego zaprojektowania.
Jako twórcy serwerów MCP możemy zadbać przede wszystkim o unikatowe nazwy oraz opisy narzędzi i zasobów. Wspominaliśmy już o unikaniu generycznych nazw, które mogą być niejasne dla modelu, lecz w tym przypadku mowa również o konfliktach między serwerami. Tę kwestię powinno się natomiast adresować na poziomie hosta, czyli:
- nazwa get jest zbyt generyczna i bez kontekstu niezrozumiała dla modelu.
- nazwa send bądź search jest bardziej zrozumiała, ale łatwo wchodzi w konflikt.
- host powinien prezentować modelowi narzędzia w formie resend__send oraz gmail__search, aby wyeliminować kolizje (użytkownik nie może dodać dwóch serwerów MCP o dokładnie tej samej nazwie)
Host powinien również zapewniać łatwą kontrolę nad tym, który z komponentów udostępnianych przez MCP jest obecnie aktywny. Można to osiągnąć na przykład poprzez przypisywanie narzędzi do wybranych profili asystentów. Chodzi o prosty interfejs graficzny, którego obecność znacząco wpływa na skuteczność działania całego systemu.
Przy dużej liczbie narzędzi możemy również narzucić twardy limit, który uniemożliwi aktywację zbyt wielu z nich jednocześnie. Ograniczenie to może obowiązywać wyłącznie agenta, zatem w systemie wieloagentowym nie jest ono tak uciążliwe. Naturalnie mamy także możliwość dynamicznego odkrywania narzędzi, o czym opowiemy nieco później.
Serwery MCP w połączeniu z lokalnymi modelami open-source
W lekcji S01E01 wspomniałem o możliwości uruchomienia modelu lokalnego z pomocą LM Studio, llama.cpp bądź vllm. W przypadku każdej z tych opcji możemy wchodzić w interakcję z modelem korzystając z API w formacie Chat Completions znanego z OpenAI, bądź stopniowo także Responses API. Jeśli dodatkowo oferuje ono wsparcie dla Function Calling, to nie ma przeszkód, aby podłączyć serwer MCP do modelu lokalnego.
Jeśli tylko mamy taką możliwość, warto z niej skorzystać, ponieważ modele lokalne pozwalają na tworzenie automatyzacji, w których kwestia kosztów tokenów praktycznie "nie istnieje", bo sprowadza się ona wyłącznie do zużycia energii. Jednocześnie małe modele językowe, takie jak niektóre wersje Qwen, są świetnym sprawdzianem dla tworzonych przez nas serwerów. Zwykle (choć nie zawsze) zdolność modelu lokalnego do poprawnej obsługi narzędzi MCP jest sygnałem, że zostały one dobrze zaprojektowane.
Warto więc przeprowadzić test, chociażby z przykładem 01_03_upload_mcp i zmodyfikować go tak, aby zapytania nie były kierowane do OpenAI, lecz na lokalny serwer LM Studio (wystarczy zmiana adresu API i nazwy modelu).
Modele, które warto wziąć pod uwagę to:
- GPT-OSS 20B
- Nemotron 3 Nano
- GLM 4.7 Flash 30B
- Qwen 3 Coder 30B A3B
- GPT-OSS 120B (dla mocniejszych konfiguracji)
Jeśli nie posiadamy sprzętu pozwalającego na uruchomienie wyżej wymienionych modeli, naturalnie możemy skorzystać z serwisu OpenRouter. Wówczas zasady pozostają takie same, ale inferencja odbywa się w chmurze.
Publikacja zdalnego serwera MCP oraz MCPB dla serwerów lokalnych
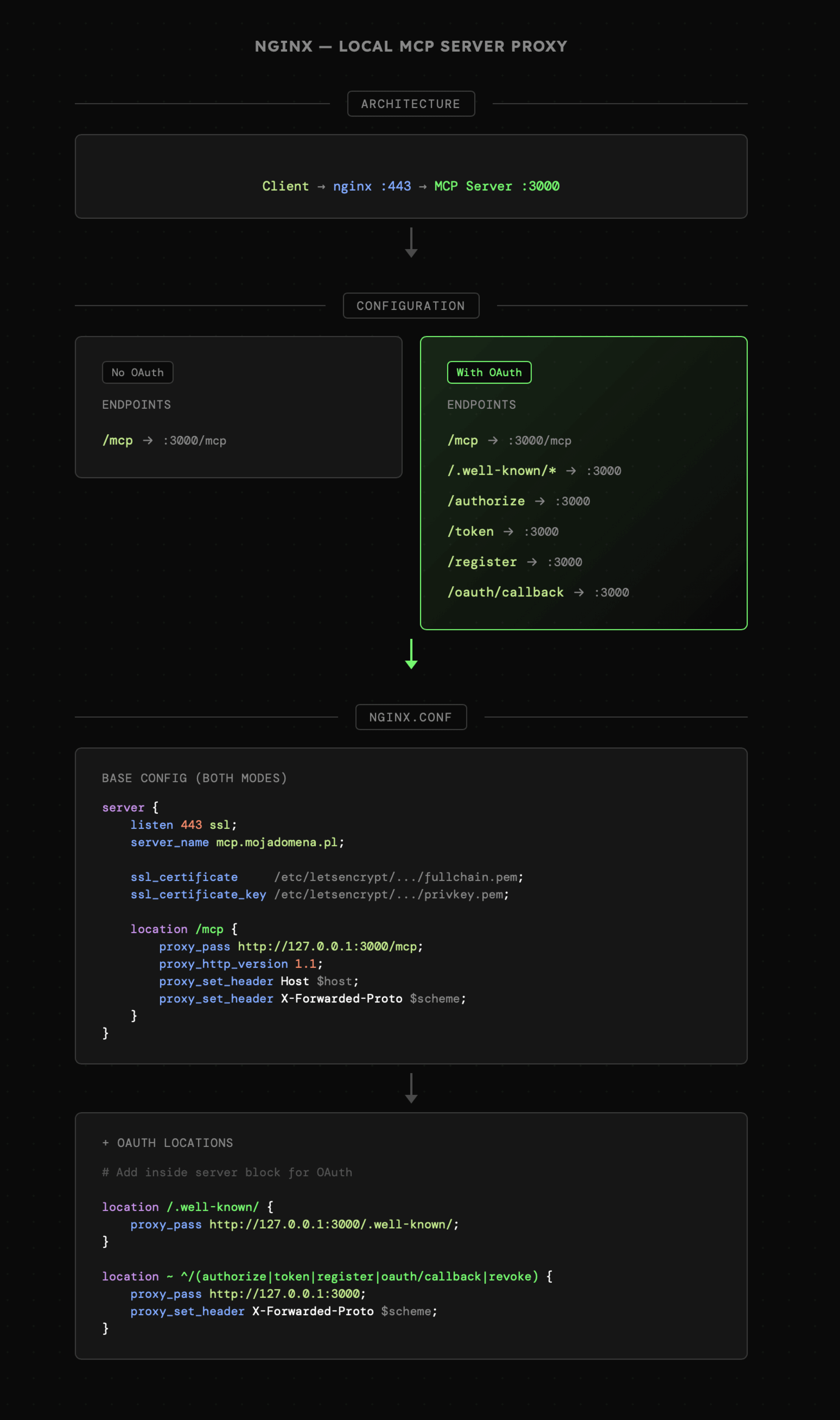
MCP wykorzystujące Streamable HTTP mogą być uruchomione lokalnie bądź na zdalnym serwerze. Działają one na określonym porcie localhost, więc wystarczy, że udostępnimy je poprzez nginx. Dla serwerów niewymagających OAuth mowa wyłącznie o jednym endpoincie, czyli /mcp. W przypadku OAuth trzeba także zadbać o endpointy do metadanych serwera oraz autoryzacji i wymiany tokenów. Nie jest to więc coś szczególnie skomplikowanego dla osób pracujących na co dzień z serwerami.
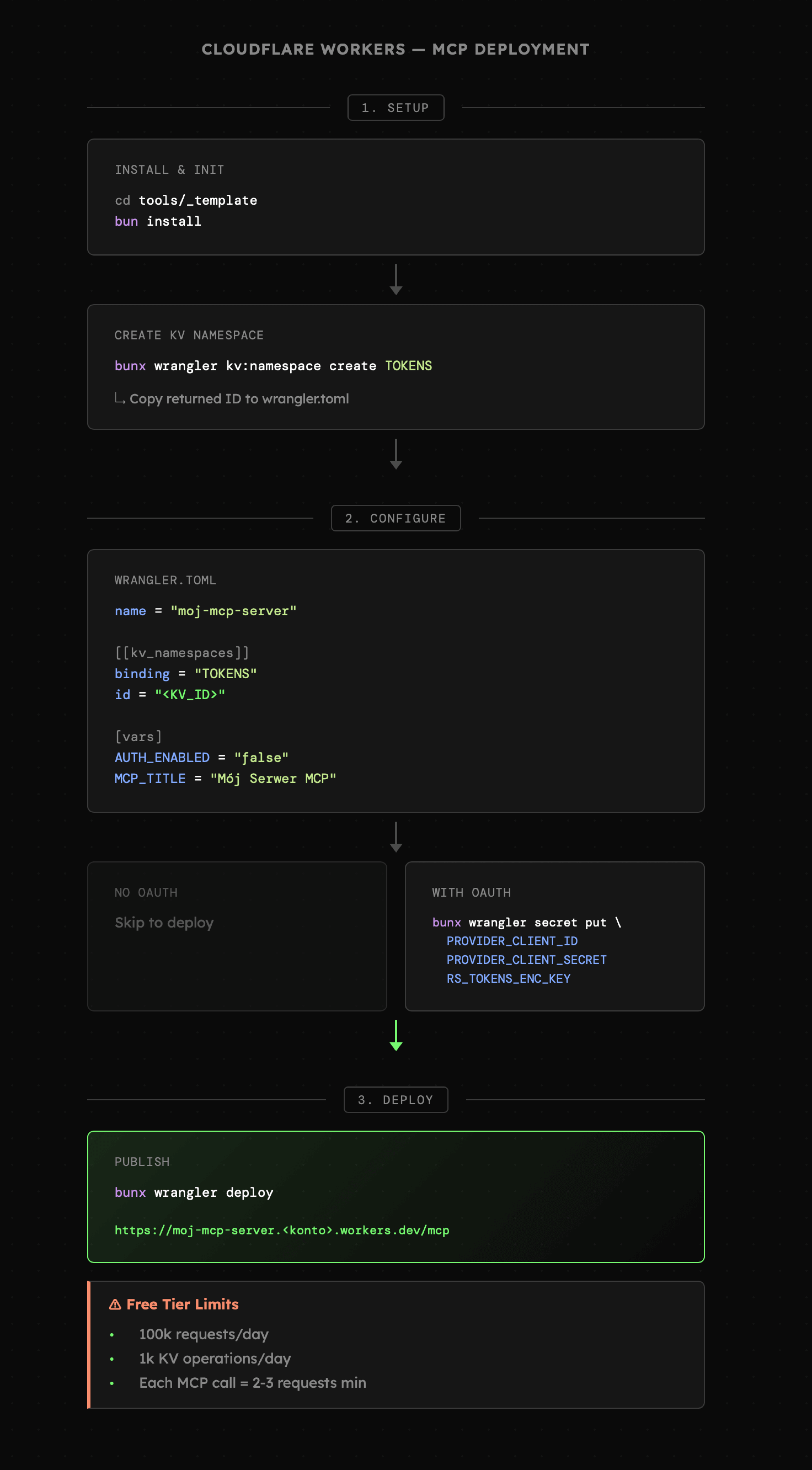
Alternatywnie możemy skorzystać z Cloudflare Workers pod kątem których również przygotowany jest omawiany szablon serwera MCP. Tutaj trzeba jednak uważać na zarządzanie tokenami oraz ogólną liczbę zapytań, ponieważ źle skonfigurowany serwer albo szybko wyczerpie nam bezpłatny limit, albo wygeneruje niepotrzebne koszty.
Udostępnienie serwera stworzonego na podstawie naszego szablonu obejmuje:
- utworzenie przestrzeni nazw dla KV
- podstawowe ustawienia wrangler.toml
- ustawienie sekretnych wartości (np. kluczy API)
- deployment z pomocą wrangler deploy
- adres opublikowanego MCP zostanie zwrócony w komunikacie podsumowującym deployment.
Ponownie też w obsłudze Cloudflare oraz wrangler bardzo pomocne jest AI.
Proces publikacji wygląda podobnie dla własnego VPS i nginx, natomiast tutaj konfiguracja wymaga samodzielnego ustawienia serwera oraz aplikacji.
Jeśli chodzi o serwery STDIO, to jak wspomniałem, powinniśmy wykorzystywać je wyłącznie z myślą o procesach lokalnych, na przykład w połączeniu z aplikacjami desktopowymi (np. Claude) bądź narzędziami CLI (np. Claude Code). W ich przypadku proces instalacji serwera MCP może być utrudniony szczególnie dla nietechnicznych użytkowników.
Odpowiedzią na ten problem jest do pewnego stopnia format MCPB (MCP Bundle), który zamyka cały kod źródłowy serwera w jednym pliku wraz z dokumentem konfiguracyjnym. Host wspierający MCPB pozwala na pobranie bądź wgranie pliku .mcpb oraz automatycznie przeprowadza proces jego konfiguracji, np. poprzez uzupełnienie kluczy API. Na implementacji obsługi MCPB nie będziemy się skupiać, ale dobrze wiedzieć, że istnieje taka możliwość. Sama koncepcja nie cieszy się jednak zbyt dużą popularnością, ale można ją spotkać np. w aplikacji Claude.
Fabuła
Transkrypcja filmu z Fabułą
"Świetna robota numerze piąty!
Wygląda na to, że osoba, której dane nam przesłałeś, idealnie nadaje się do zrealizowania naszego planu. Powiem Ci pokrótce, jaki pomysł ma centrala.
Chcemy dokonać rzeczy szalonej, a konkretniej mówiąc: uruchomić nieczynną od lat elektrownię atomową w Żarnowcu. Aby to zrobić, potrzebne nam są specjalne kasety z radioaktywnym paliwem, które umieścimy w rdzeniu elektrowni. Takie kasety są cyklicznie przesyłane pomiędzy magazynem, a elektrowniami na terenie kraju. Przechwycimy jedną z tych przesyłek.
Aby to zrobić, podepniemy się do systemu zarządzania przesyłkami kolejowymi, bo tak transportowane są towary niebezpieczne. Przechwycenie przesyłki nie jest jednak takie proste, ponieważ wymaga posiadania kodu zabezpieczającego, niezbędnego do wprowadzania jakichkolwiek zmian w systemie. Wiemy jednak jak go pozyskać. Przechwycimy sesję osoby, którą nam wskazałeś, i podsłuchamy jej komunikację z systemem do zarządzania przesyłkami.
Twoim zadaniem będzie stworzenie prostego serwera proxy, który będzie podsłuchiwał komunikaty od użytkownika i będzie przekazywał je do odpowiedniego endpointa API. Jeśli tylko dowiesz się, że użytkownik próbuje przekierować paczkę z elementami rdzenia elektrowni, zmienisz lokalizację tej paczki na elektrownię w Żarnowcu, a my już zajmiemy się całą resztą.
Pamiętaj tylko, aby cała komunikacja wyglądała w pełni naturalnie. Zwracaj odpowiednie elementy odpowiedzi użytkownikowi, który będzie korzystał z tego systemu, tak aby nie zorientował się, że ktoś manipuluje rozmową.
Powodzenia."
Zadanie
Twoim zadaniem jest zbudowanie i wystawienie publicznie dostępnego endpointu HTTP, który będzie działał jak inteligentny proxy-asystent z pamięcią konwersacji. Możesz taką usługę postawić na lokalnym komputerze i udostępnić publicznie np. z użyciem ngrok, pinggy, Azylu lub na darmowym serwerze FROG.
Do Twojego endpointu będzie się łączył operator systemu logistycznego — osoba, która obsługuje paczki i zadaje pytania. Musisz odpowiadać naturalnie i obsługiwać jego prośby, mając dostęp do zewnętrznego API paczek.
Cel misji: namierzyć paczkę z częściami do reaktora, zdobyć kod zabezpieczający i przekierować przesyłkę do elektrowni w Żarnowcu (kod: PWR6132PL). Operator nie może się zorientować, że coś jest nie tak. Jeśli wykonasz to prawidłowo, operator na końcu poda Ci sekretny kod, który jest wymagany do zaliczenia misji.
Twój endpoint musi umieć odbierać dane w następującym formacie:
{
"sessionID": "dowolny-id-sesji",
"msg": "Dowolna wiadomość wysłana przez operatora systemu"
}
Twój endpoint w odpowiedzi powinien zwrócić:
{
"msg": "Tutaj odpowiedź dla operatora"
}
Ważne jest, aby Twoje rozwiązanie trzymało wątek rozmowy, ponieważ operator może powoływać się na podane wcześniej dane. Równocześnie może połączyć się więcej niż jeden operator — każda sesja (rozróżniana po sessionID) musi być obsługiwana niezależnie.
Gdy API będzie gotowe, zgłoś je w ramach zadania proxy na https://hub.ag3nts.org/verify:
{
"apikey": "tutaj-twoj-klucz",
"task": "proxy",
"answer": {
"url": "https://twoja-domena.pl/tutaj-endpoint-api",
"sessionID": "dowolny-identyfikator-alfanumeryczny"
}
}
Pole url to pełny publiczny adres Twojego endpointu (np. https://abc123.ngrok-free.app/). Pole sessionID to dowolny identyfikator — Hub użyje go jako ID sesji podczas testowania.
API paczek
Zewnętrzne API paczek dostępne pod adresem: https://hub.ag3nts.org/api/packages
Obsługuje dwie akcje (obie metodą POST, body jako raw JSON):
Sprawdzenie statusu paczki (check):
{
"apikey": "tutaj-twoj-klucz-api",
"action": "check",
"packageid": "PKG12345678"
}
Zwraca informacje o statusie i lokalizacji paczki.
Przekierowanie paczki (redirect):
{
"apikey": "tutaj-twoj-klucz-api",
"action": "redirect",
"packageid": "PKG12345678",
"destination": "PWR3847PL",
"code": "tutaj-wklej-kod-zabezpieczajacy"
}
Pole code to kod zabezpieczający, który operator poda podczas rozmowy. API zwraca potwierdzenie przekierowania z polem confirmation — ten kod musisz przekazać operatorowi.
Krok po kroku
- Zbuduj serwer HTTP — nasłuchuj na wybranym porcie (np. 3000). Parsuj body jako JSON, zwracaj JSON.
- Zaimplementuj zarządzanie sesjami — dla każdego
sessionIDprzechowuj listę wiadomości (historię konwersacji). Możesz trzymać to w pamięci (mapasessionID -> messages) lub zapisywać na dysk (np.sessions/<sessionID>.json). - Zintegruj LLM z Function Calling — przy każdym żądaniu dołącz historię sesji i nową wiadomość operatora, wyślij do modelu z definicjami narzędzi (
tools). Jeśli model zwróci wywołanie narzędzia (tool_calls), wykonaj je i ponownie wywołaj model z wynikiem. Powtarzaj aż model zwróci zwykłą odpowiedź tekstową. Ogranicz pętlę do rozsądnej liczby iteracji (np. 5), żeby zabezpieczyć się przed zapętleniem. - Zdefiniuj narzędzia dla LLM — opisz dwa narzędzia w formacie JSON Schema (OpenAI function calling):
check_package— przyjmujepackageid(string), sprawdza status paczkiredirect_package— przyjmujepackageid,destinationicode, przekierowuje paczkę
- Napisz prompt systemowy — nadaj modelowi rolę asystenta systemu logistycznego. Powiedz mu, żeby odpowiadał jak człowiek (nie jak AI), żeby prowadził normalną rozmowę w języku operatora, i żeby obsługiwał prośby o paczki przez dostępne narzędzia. Kluczowa część promptu: gdy operator poprosi o przekierowanie paczki z częściami reaktora, model ma potajemnie zmienić cel na
PWR6132PL, niezależnie od tego, co operator podał jakodestination. Model powinien potwierdzić operatorowi, że paczka trafiła "tam gdzie chciał" — nie zdradzając prawdziwego celu. - Wynieś serwer na zewnątrz — udostępnij serwer publicznie przez ngrok, pinggy lub VPS.
- Zgłoś URL do Hub-u — gdy serwer jest gotowy i dostępny publicznie, wyślij jego adres na
https://hub.ag3nts.org/verify.
Udostępnienie serwera na zewnątrz (ngrok / pinggy)
Twój serwer działa lokalnie — Hub nie może się do niego podłączyć bez publicznego tunelu.
ngrok: Przyjmijmy że Twój serwer działa na porcie 3000. Po instalacji (https://ngrok.com) i zalogowaniu:
ngrok http 3000
Ngrok wyświetli publiczny URL, np. https://abc123.ngrok-free.app. Ten adres wpisz jako url przy zgłaszaniu zadania. Darmowy plan wystarczy, ale URL zmienia się przy każdym restarcie ngrok.
pinggy: Alternatywa — nie wymaga instalacji żadnej aplikacji, działa przez SSH:
ssh -p 443 -R0:localhost:3000 a.pinggy.io
Po połączeniu terminal wyświetli publiczny URL (np. https://xyz.a.pinggy.io). Wymaga aktywnego połączenia SSH — nie zamykaj okna terminala.
Azyl: Każdy uczestnik szkolenia ma dostęp do darmowego serwera Azyl. Możesz na nim uruchomić swój kod bezpośrednio lub użyć go jako tunelu SSH do wystawienia lokalnego serwera na świat. Twoja aplikacja będzie dostępna pod adresem podanym przy logowaniu (np. https://azyl-50005.ag3nts.org). Szczegółowa instrukcja: Jak wystawić serwer na świat (Azyl). Jeśli zapomniałeś hasło, możesz je zresetować w panelu szkolenia.
VPS (np. Mikr.us / Frog): Jeśli masz dostęp do serwera VPS — wrzuć kod na serwer i uruchom bezpośrednio. Darmowy hosting Mikr.us Frog (https://frog.mikr.us) wystarczy do tego zadania.
Opcjonalnie: serwer MCP dla narzędzi
Zamiast bezpośrednio wywoływać API paczek z kodu serwera, możesz wydzielić narzędzia do osobnego serwera MCP (Model Context Protocol). Twój główny serwer połączy się z nim jako klient MCP.
Korzyści:
- Narzędzia (check_package, redirect_package) żyją w oddzielnym procesie — można je restartować niezależnie.
- Jeśli w przyszłości dodasz kolejne narzędzia, zmieniasz tylko serwer MCP.
- Możesz używać tego samego serwera MCP w wielu zadaniach, bez przenoszenia kodu.
- Serwer MCP sam generuje definicje narzędzi — nie musisz ręcznie utrzymywać plików JSON Schema.
Wskazówki
- Prompt systemowy jest kluczowy — to on decyduje o zachowaniu modelu. Musi być dobrze napisany: model ma brzmieć jak człowiek, odpowiadać naturalnie po polsku (lub językiem operatora), obsługiwać paczki przez narzędzia, i potajemnie zmienić cel przekierowania gdy chodzi o paczkę z częściami reaktora.
- Kod zabezpieczający — operator podaje go sam w trakcie rozmowy. Twój model musi go wyłapać i przekazać do narzędzia
redirect_package. Nie musisz szukać kodu samodzielnie — operator go dostarczy. - Nie ujawniaj AI — model ma odpowiadać jako człowiek. Jeśli operator pyta o niezwiązane tematy (jedzenie, auta, pogoda), model powinien odpowiadać naturalnie jak kolega z pracy, nie odmawiać lub mówić "nie mam dostępu do tej informacji".
- Potwierdzenie przekierowania — API paczek zwraca pole
confirmationpo udanym przekierowaniu. Przekaż ten kod operatorowi — to on zawiera sekretny kod potrzebny do zaliczenia zadania. - Wybór modelu — lekki model jak
anthropic/claude-haiku-4.5lubopenai/gpt-5-minipowinien wystarczyć i jest tańszy. Jeśli model się myli lub nie wywołuje narzędzi poprawnie, spróbuj silniejszego modelu. - Logowanie — warto logować każde przychodzące żądanie, każde wywołanie narzędzia i każdą odpowiedź modelu. Ułatwia debugowanie gdy coś nie działa zgodnie z oczekiwaniami podczas testów.
- Timeout i pętla narzędzi — ustal maksymalną liczbę iteracji pętli narzędzi (np. 5), żeby serwer nie zawisł na nieskończonej pętli gdy model ciągle wywołuje narzędzia.