first commit
This commit is contained in:
@@ -0,0 +1,356 @@
|
||||
---
|
||||
title: S02E01 — Zarządzanie kontekstem w konwersacji
|
||||
space_id: 2476415
|
||||
status: scheduled
|
||||
published_at: '2026-03-16T04:00:00Z'
|
||||
is_comments_enabled: true
|
||||
is_liking_enabled: true
|
||||
skip_notifications: false
|
||||
cover_image: 'https://cloud.overment.com/thoughts-1773307903.png'
|
||||
circle_post_id: 30571953
|
||||
---
|
||||
» [Lekka wersja przeglądarkowa](https://cloud.overment.com/s02e01-zarzadzanie-kontekstem-w-konwersacji-1773309044.html) oraz [markdown](https://cloud.overment.com/s02e01-zarzadzanie-kontekstem-w-konwersacji-1773309011.md) «
|
||||
|
||||

|
||||
|
||||
Context Engineering pojawił się w S01E02 przy okazji łączenia modelu z narzędziami. Jednocześnie rola kontekstu jest widoczna cały czas, dlatego musimy zatrzymać się przy nim na znacznie dłużej. Umożliwi to również dokładniejsze przyjrzenie się projektowaniu oraz generowaniu instrukcji, co otwiera przestrzeń do automatycznego tworzenia umiejętności, a także budowania i aktualizowania agentów.
|
||||
|
||||
## Rola kontekstu w instrukcjach systemowych
|
||||
|
||||
Instrukcje systemowe mają na celu **dopasowanie zachowania modelu**. Według początkowych założeń, było to miejsce do dostarczenia wszystkich informacji potrzebnych do funkcjonowania systemu. Teraz już tak nie jest, ponieważ agenci i systemy wieloagentowe dynamicznie odkrywają to, czego w danym momencie potrzebują. Połączenie tego z rozwojem samych modeli sugeruje, że rola instrukcji systemowej znacznie spadła.
|
||||
|
||||
Przyjrzyjmy się więc z bliska.
|
||||
|
||||
W lekcji S01E01 omawialiśmy prompty systemowe publikowane przez firmy Anthropic oraz xAI. Były to relatywnie rozbudowane instrukcje, które skupiały się głównie na kształtowaniu zachowania czatbota poprzez określenie stylu wypowiedzi, a nawet cech charakteru wpływających na jego odbiór przez użytkownika. [Instrukcje te](https://platform.claude.com/docs/en/release-notes/system-prompts) nie są jednak kompletne, ponieważ brakuje w niej definicji dostępnych narzędzi, które mogą być **aktywowane** przez użytkownika, zmieniając tym samym zachowanie modelu.
|
||||
|
||||
Zatem jeśli tryb **online** jest włączony, Claude nie może przeszukiwać sieci, ale też **definicja narzędzia web\_search jest niedostępna**. Pomimo tego model "wie", że nie posiada dostępu do Internetu, ponieważ w instrukcji systemowej (z dnia 05.02.2026) znajduje się fragment:
|
||||
|
||||
> Claude avoids agreeing with or denying claims about things that happened after May 2025 since, **if the search tool is not turned on, it can't verify these claims.**
|
||||
|
||||
Czyli prompt systemowy daje modelowi **świadomość** otoczenia, które w tym przypadku dotyczy aktywnych trybów aplikacji Claude.
|
||||
|
||||
Innym przykładem jest [Cursor](https://cursor.com/), gdzie możemy zapytać agenta o **aktualnie otwarty plik** i otrzymamy odpowiedź pomimo tego, że **żadne z narzędzi nie zostanie uruchomione** co jest sygnałem, że informacja ta znajduje się bezpośrednio w wiadomości systemowej (choć wkrótce sprawdzimy czy rzeczywiście tak jest).
|
||||
|
||||
Wiemy już, że w ten sposób nie możemy poinformować modelu o wszystkim, co dzieje się w otoczeniu. Nie mamy też możliwości dodania nieskończonej liczby narzędzi, a przynajmniej nie w taki sposób, aby model "widział" je wszystkie naraz. Pomimo tego musimy sprawić, aby **agent** miał dostęp do informacji, które pozwolą mu wykorzystać dostępne zasoby, wliczając w to wiedzę o otoczeniu oraz dostępnych agentach. Pytanie tylko: **jak?**
|
||||
|
||||
Instrukcję systemową można porównać do zwykłej mapy. Mapa pomaga nam odnaleźć się w terenie, pomimo tego, że reprezentuje jedynie jego **uproszczoną formę**. Zatem agent posiadający do dyspozycji jedynie uproszczoną strukturę treści może nawigować po niej, stopniowo odkrywając kolejne fragmenty.
|
||||
|
||||
1. **Uniwersalne instrukcje:** jeśli agent dysponuje pamięcią długoterminową, to instrukcja systemowa powinna informować model o tym fakcie, a nawet dawać **generalne** zrozumienie na temat **roli** pamięci, a niekiedy nawet jej **głównych obszarów** takich jak **profile osób**, **"osobowość" agenta** czy ogólna wiedza **na temat użytkownika** bądź nawet **samego systemu** i jego funkcjonalności. Jednocześnie powinniśmy unikać specyficznych instrukcji, których obecność w prompcie systemowym przez większość czasu stanowi jedynie szum.
|
||||
|
||||
Poniżej widzimy przykład takiej instrukcji oraz jej w roli w interakcji. Można tu zadać pytanie: **dlaczego informacje o roli pamięci znajdują się w prompcie systemowym, a nie opisie narzędzi do obsługi pamięci?** - ponieważ narzędzia mogą być dołączane do różnych agentów, i u każdego z nich może pełnić inną rolę. Zachowujemy więc tutaj **zgeneralizowane** opisy, które elastycznie dopasowują się do otaczającego kontekstu.
|
||||
|
||||
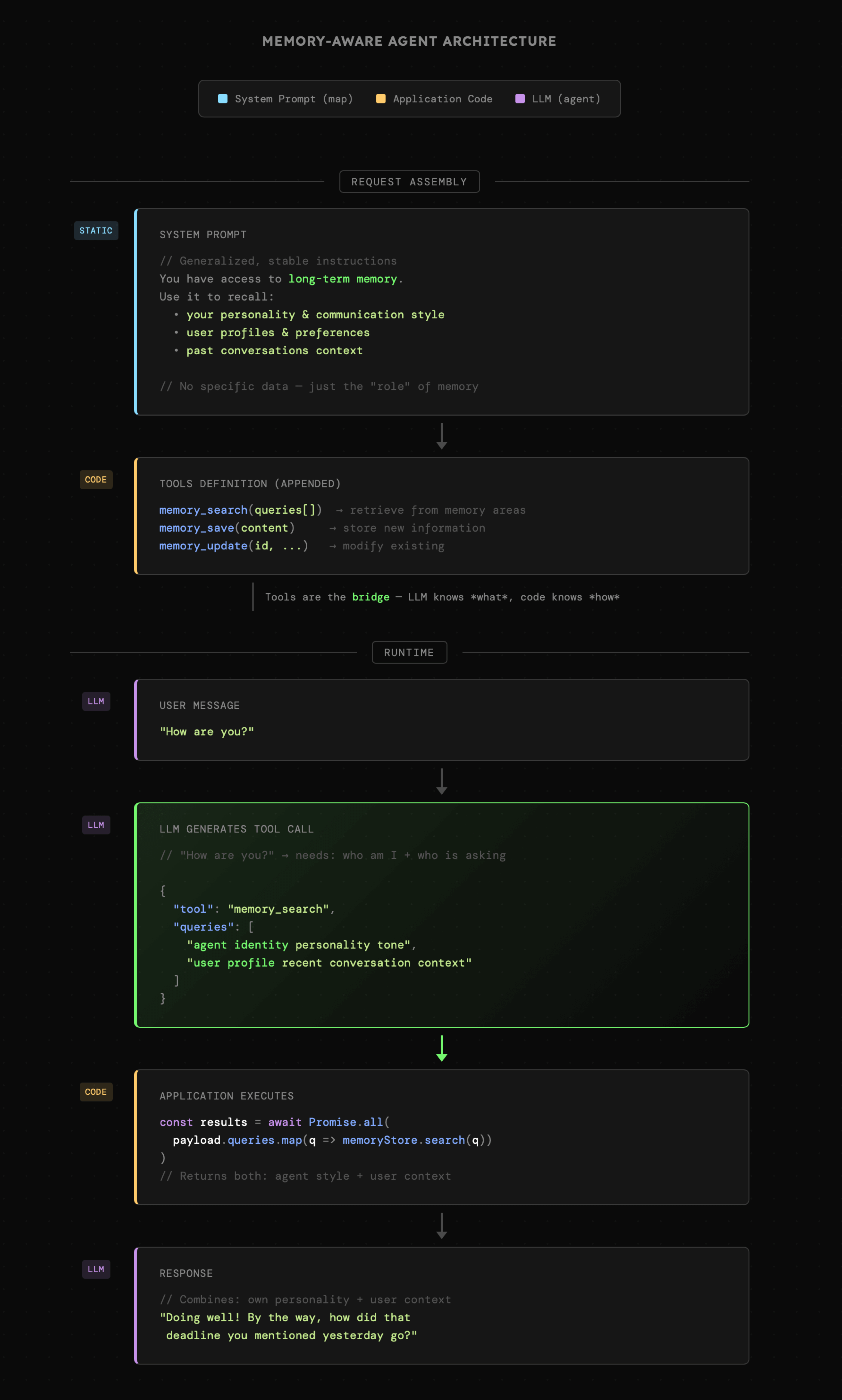
|
||||
|
||||
2. **Otoczenie:** Agenci niemal zawsze muszą być "świadomi" otoczenia, rozumianego jako środowisko, w którym się znajdują, oraz posiadać przynajmniej ogólne informacje na temat użytkownika. Na przykład Claude Code domyślnie wie, w jakim systemie operacyjnym pracuje, co pozwala mu na dopasowanie obsługi CLI. To świetny przykład, ponieważ od razu widać, jak ogromny wpływ na agenta ma ta jedna informacja.
|
||||
|
||||
Jednak otoczenie nie zawsze jest tak statyczne. Zwykle mówimy tu o ustawieniach użytkownika, metadanych na jego temat (np. statusie urządzeń), rodzaju interfejsu (np. głosowym), rodzaju interakcji (np. CRON bez obecności człowieka) czy skróconym profilu użytkownika, który może być aktualizowany i uzależniany od pozostałych zmiennych środowiskowych. Agent może być także poinformowany o dostępnych zasobach i związanych z nimi ograniczeniach.
|
||||
|
||||
Wybór tych informacji sprowadza się do odpowiedzi na pytanie: **o czym musi wiedzieć agent PRZED uruchomieniem narzędzi, aby skrócić swoją ścieżkę dojścia do celu oraz zwiększyć szansę na ukończenie zadania?**
|
||||
|
||||

|
||||
|
||||
3. **Sesja:** Modyfikowanie promptu systemowego w trakcie sesji to prosty sposób na problemy z **prompt cache**. Jednak sesja może wykraczać poza domyślne limity okna kontekstowego, więc część informacji może być kompresowana bądź zapisywana w bazie danych bądź plikach. Takie transformacje odbywają się w zależności od bieżącego stanu okna kontekstowego i jest to miejsce na modyfikacje wiadomości systemowej. Agent musi być poinformowany o tym, co wydarzyło się wcześniej oraz o tym, w jaki sposób może dostać się do tych informacji.
|
||||
|
||||
Należy jednak uważać przy dodawaniu **postępów realizacji zadania** bądź podobnych informacji, które **zaburzają chronologię** zdarzeń przez co prompt systemowy przedstawia **starsze** fakty niż treść dalszych wiadomości.
|
||||
|
||||
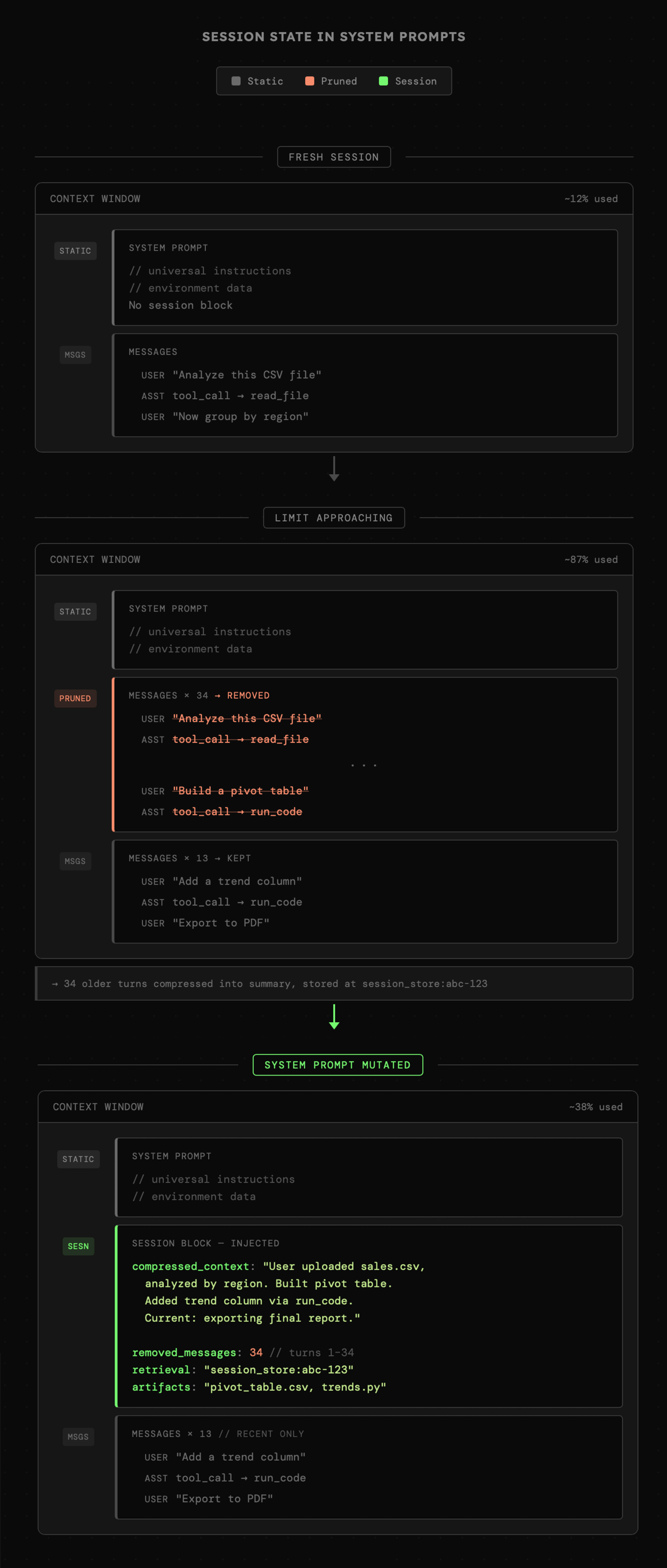
|
||||
|
||||
4. **Zespół agentów:** Na temat systemów wieloagentowych będziemy jeszcze rozmawiać. Warto jednak już teraz kształtować wyobrażenie o komunikacji między nimi, która musi obejmować zarówno narzędzia do interakcji, jak i instrukcje określające zasady poruszania się w systemie. Podobnie też agenci powinni mieć jasno określone zasady komunikacji, w tym także sposobu **współdzielenia** kontekstu, co zwykle odbywa się poprzez pliki tekstowe.
|
||||
|
||||
W przypadku systemów wieloagentowych przynajmniej część instrukcji systemowej będzie **współdzielona**. Nie mówimy tutaj o treści w pełni dynamicznej, lecz o wspólnych instrukcjach. System powinien zatem przewidywać obsługę placeholderów, które umożliwią wygodną kompozycję promptu.
|
||||
|
||||
## Odróżnianie szumu od sygnału z pomocą modelu
|
||||
|
||||
Już kilkukrotnie wspominałem o koncepcji „sygnału i szumu” w kontekście interakcji z modelem językowym. Intuicyjnie można się domyślić, że chodzi o proporcję istotnych informacji sprzyjających wykonaniu zadania względem tych, które jedynie niepotrzebnie rozpraszają uwagę modelu. Jednak co to oznacza dla nas w praktyce i to szczególnie, gdy mówimy o dynamicznym kontekście agentów?
|
||||
|
||||
Przede wszystkim wciąż obserwujemy rozwój modeli językowych. Obejmuje on zdolność do sprawnego posługiwania się kontekstem oraz precyzyjnego podążania za instrukcjami. W rezultacie rośnie złożoność zadań stawianych przed agentami, a tym samym zakres kontekstu niezbędny do ich wykonania. Szybko zaczynamy mieć trudności ze zrozumieniem zależności, które i tak mają dynamiczny charakter. Trudno więc tu mówić o kontrolowaniu sygnału. Ale czy na pewno?
|
||||
|
||||
Projektowanie generatywnych aplikacji w ostatnich miesiącach wyraźnie przesuwa granicę między **logiką, którą kształtujemy w kodzie**, a tą, którą **dynamicznie realizuje AI**. Rola kodu aplikacji znacząco się zmienia, a jego ilość maleje, ponieważ agent samodzielnie generuje skrypty oraz podejmuje coraz więcej decyzji, uzależniając je od bieżącej sytuacji. Widać to na poniższym schemacie prezentującym różne części logiki dla AI workflow, agentów oraz systemów wieloagentowych.
|
||||
|
||||

|
||||
|
||||
**Uwaga!** Ilość kodu w systemach wieloagentowych nie jest równoznaczna ze spadkiem roli kodu. Poza tym obecność agentów AI nie zawsze będzie uzasadniona i tam gdzie kod sprawdza się lepiej, nadal będziemy z niego korzystać.
|
||||
|
||||
Sytuacja w której złożoność i dynamika logiki aplikacji rosną sprawia, że coraz trudniej jest przewidywać wszystkie możliwe scenariusze. Nie możemy więc mówić tu o dosłownym kontrolowaniu "sygnału", ale raczej **stwarzaniu warunków do tego, aby jego poziom był możliwie wysoki** poprzez zadbanie o detale takie jak:
|
||||
|
||||
- **Poprawne dostarczanie kontekstu.** Brzmi to jak coś oczywistego, ale dostarczenie niekompletnego bądź nawet niewłaściwego zestawu danych zdarzają się bardzo często, na przykład z powodu konfliktu narzędzi bądź mylnych komunikatów ze strony zewnętrznych API.
|
||||
- **Wysokiej jakości logika aplikacji.** Logika systemów wieloagentowych może wymagać mniej kodu, lecz musi być on niezwykle dopracowany. Podczas gdy agent może rozwiązać problemy związane z obsługą narzędzi, trudno będzie "ominąć" błędnie działające elementy jego głównego systemu.
|
||||
- **Dopracowane instrukcje i schematy narzędzi.** Prompt Engineering nie polega już wyłącznie na tworzeniu kompleksowych instrukcji systemowych, lecz na projektowaniu **komponentów** promptu pojawiających się w trakcie interakcji. Wyzwanie polega na tym, że ich treść musi się elastycznie dopasowywać bez względu na to, kiedy zostaną one dołączone do kontekstu.
|
||||
- **Generyczne mechanizmy**. System powinien uwzględniać automatyczne rozwiązania (na przykład kompresję kontekstu bądź planowanie zadań i monitorowanie postępów), które zostaną zaprojektowane na tyle uniwersalnie, aby dostarczać wartość w każdej sytuacji. **Generalizowania** rozwiązań jest obecnie jedną z najważniejszych umiejętności programistów tworzących generatywne aplikacje.
|
||||
- **Przestrzeń na doprecyzowanie.** Błędy i sytuacje w których agent z różnych powodów nie będzie mógł kontynuować zadania z pewnością będą się zdarzać. Dlatego interwencje ze strony człowieka (lub innych agentów) mające na celu **dostarczenie "sygnału"** są niezbędne.
|
||||
|
||||
Mówiąc wprost: **właściwa proporcja "sygnału do szumu" wprost wynika z detali systemu**, o które musimy zadbać. Ujmując to inaczej - musimy być jeszcze lepsi w programowaniu, niż do tej pory.
|
||||
|
||||
## Kształtowanie kontekstu poprzez obserwację
|
||||
|
||||
Kontekst konwersacji kształtuje nie tylko to, co zostaje do niej przesłane, ale także wszystko co do niej trafia w wyniku działania modelu oraz rozwoju interakcji. Inaczej mówiąc **zachowanie i akcje agenta** wpływają na jakość kontekstu.
|
||||
|
||||
Agent posiadający dostęp do zewnętrznego kontekstu może domyślnie z niego nie korzystać, ponieważ zazwyczaj "**nie wie, o czym wie**" (oraz czego nie wie). Musimy zatem tak poprowadzić agenta, aby wiedział, jak skutecznie sięgać po zewnętrzne informacje.
|
||||
|
||||
Mówiliśmy, że możemy podejść do tego problemu, dostarczając „mapę” w postaci wskazówek zawartych w instrukcji systemowej. Jednak taka mapa nie zawsze będzie wystarczająca, ponieważ nie sposób uwzględnić w niej detali, które ujawniają się dopiero w trakcie eksploracji.
|
||||
|
||||
Z programistycznego punktu widzenia docieranie do informacji przechowywanych w bazie danych, polega na skorzystaniu z jakiejś formy wyszukiwania, na przykład full-text search, fuzzy search czy semantic search (dopasowanie znaczeniowe). Na co dzień obserwujemy to pracując z agentami do kodowania, gdzie na przykład Claude Code eksploruje kod posługując się narzędziami takimi jak **grep / ripgrep**. Przeszukiwanie wymaga od modelu budowania kolejnych zapytań na podstawie dotychczasowej konwersacji w tym także kolejno odnajdywanych informacji. Mówimy więc tutaj o **agentic search** albo nawet **agentic RAG**. Agent w ten sposób samodzielnie dąży do budowania kontekstu, który pozwala mu zaimplementować funkcjonalność czy rozwiązać błędy.
|
||||
|
||||
> RAG - Retrieval Agentic Generation polega na dostarczaniu zewnętrznych informacji do kontekstu modelu językowego, zwykle poprzez wyszukiwanie, w celu rozszerzenia jego wiedzy i umiejętności. Agentic RAG to odpowiednik tego procesu, ale realizowany przez agenta bądź agentów.
|
||||
|
||||
Aby zrozumieć lepiej proces wyszukiwania, załóżmy teraz, że posiadamy bazę wiedzy w postaci lekcji szkolenia AI\_devs i podłączamy ją do agenta, którego zadanie polega na **wizualizacji** omawianych koncepcji i przykładów. Zatem jeśli agent ten, zostanie poproszony o przedstawienie technik dotyczących **zarządzania kontekstem**, to jego działania będą wyglądać mniej więcej tak:
|
||||
|
||||
- **#1 Wyszukiwanie:** agent sięga po narzędzie **file\_search** z kilkoma początkowymi frazami "context engineering", "context management", "context window"
|
||||
- **#2 Korekta:** wyniki wyszukiwania zawierają **zaledwie pojedyncze wpisy (!)** Agent orientuje się jednak, że treść dokumentów zapisana jest w języku polskim, więc kontynuuje eksplorację, tym razem z bardziej dopasowanymi frazami.
|
||||
- **#3 Wykorzystanie:** po zakończeniu wyszukiwania, agent przechodzi do planowania wizualizacji oraz kontynuuje pracę nad zleconym zadaniem. (...tutaj się zatrzymamy, bo reszta nie jest teraz istotna).
|
||||
|
||||

|
||||
|
||||
Pomimo początkowych problemów, agent dynamicznie dostosował swoje zachowanie poprzez **obserwację otoczenia**. Nie były potrzebne tu specjalne zapisy instrukcji systemowej. Po prostu sam fakt, że skorzystaliśmy z logiki agenta sprawił, że skuteczność wyszukiwania wzrosła. Nie oznacza to jednak, że agent **magicznie** dotrze do wszystkich dokumentów.
|
||||
|
||||
Przykładowo, jeśli agent zostałby zapytany o wizualizację technik pracy z **oknem kontekstowym**, to jedynie przypadkiem może dotrzeć do fragmentów lekcji **S01E05**, gdzie w sekcji "Rodzaje limitów modeli generatywnego AI oraz API" mówiliśmy o limitach okna kontekstowego, ale **to słowo kluczowe nie padło tam ani razu.**
|
||||
|
||||
Pierwsza myśl w takiej sytuacji dotyczy **zmiany wiadomości systemowej**. Przede wszystkim możemy dopisać do niej informację mówiącą o tym, że **dokumenty AI\_devs są w języku polskim**, bo dzięki temu agent natychmiast zacznie generować poprawne zapytania. Co prawda treść tej instrukcji jest bardzo specyficzna i być może powinniśmy zaadresować problem języka w inny sposób, ale też nie zawsze musimy na siłę dążyć do najlepszych możliwych rozwiązań.
|
||||
|
||||
Tym bardziej, że znacznie większe wyzwanie czeka nas przy instrukcji, która pokieruje agenta podczas eksploracji plików, ponieważ opcje takie jak:
|
||||
|
||||
- zdanie "*zapytany o zarządzanie okna kontekstowego, odnajdź informacje o limitach modeli*" nie będzie właściwe, ze względu na zbyt dużą specyfikę. Czyli poprawi to skuteczność dla naszego zapytania, ale nie pomoże z innymi zagadnieniami.
|
||||
- zdanie "*przy eksploracji dokumentów, **szukaj także powiązanych zagadnień***" jest lepsze, bo zwiększa zakres poszukiwań, ale nie do końca wiadomo co oznacza "powiązanych" i jest tu ogromna przestrzeń do nadinterpretacji prowadzącej do docierania do zbyt dużej ilości niepotrzebnych treści.
|
||||
- przykłady "**few-shot**" prezentujące kilka zestawów zapytań, które mogą sugerować modelowi oczekiwane zachowanie. Niestety przykłady często są dość obszerne, więc można je zastosować tylko wtedy, jeśli agent faktycznie specjalizuje się w ściśle określonym zakresie zadań.
|
||||
- opisanie procesu obejmującego pogłębione, wieloetapowe przeszukiwanie prawdopodobnie zwiększy skuteczność, ale jednocześnie wpłynie na wykonywanie niepotrzebnych kroków nawet dla prostych zapytań.
|
||||
|
||||
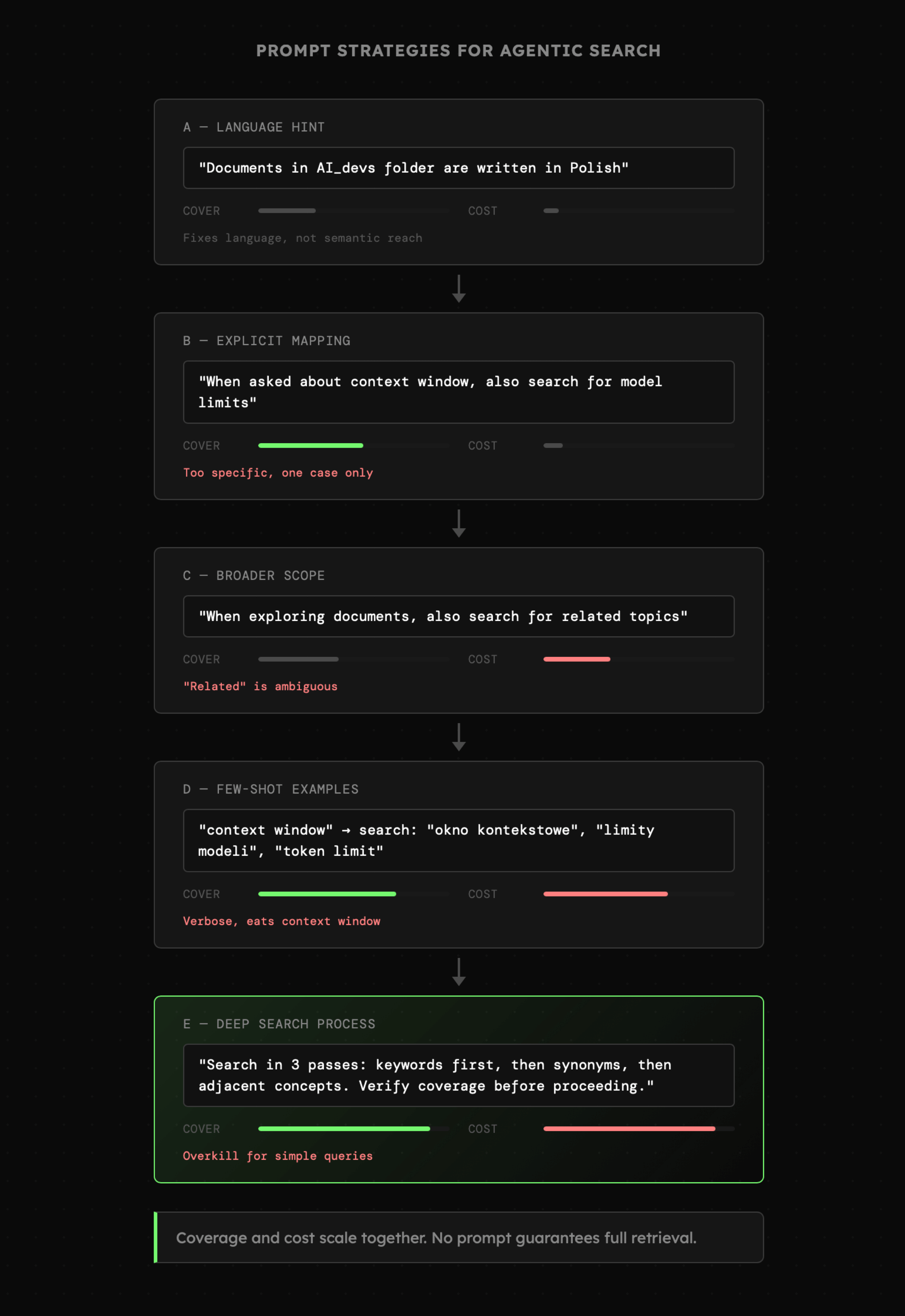
|
||||
|
||||
Widać zatem, że stworzenie instrukcji, która adresuje nasz problem, nie jest łatwe. W dodatku i tak nie da to nam gwarancji 100% skuteczności, ponieważ poruszamy się tu w **obszarze prawdopodobieństwa, a nie pewności**. Nie oznacza to jednak, że nie możemy dążyć do uzyskania możliwie najlepszych rezultatów.
|
||||
|
||||
Poza tym podczas pracy z zewnętrznym kontekstem problem nie zawsze będzie dotyczył odnajdywania rozproszonych informacji, lecz raczej konieczności sięgnięcia do dwóch lub trzech źródeł przed wykonaniem zadania. Poniżej widzimy to na przykładzie prostego "sprawdzenia pogody", w którym agent pobiera lokalizację użytkownika, sprawdza jego kalendarz, następnie mapę i w ostateczności pogodę w dwóch miastach. Jest to świetny przykład sytuacji w której intencja użytkownika została rozszerzona o pozyskanie informacji, które wpływają na jakość końcowej odpowiedzi.
|
||||
|
||||
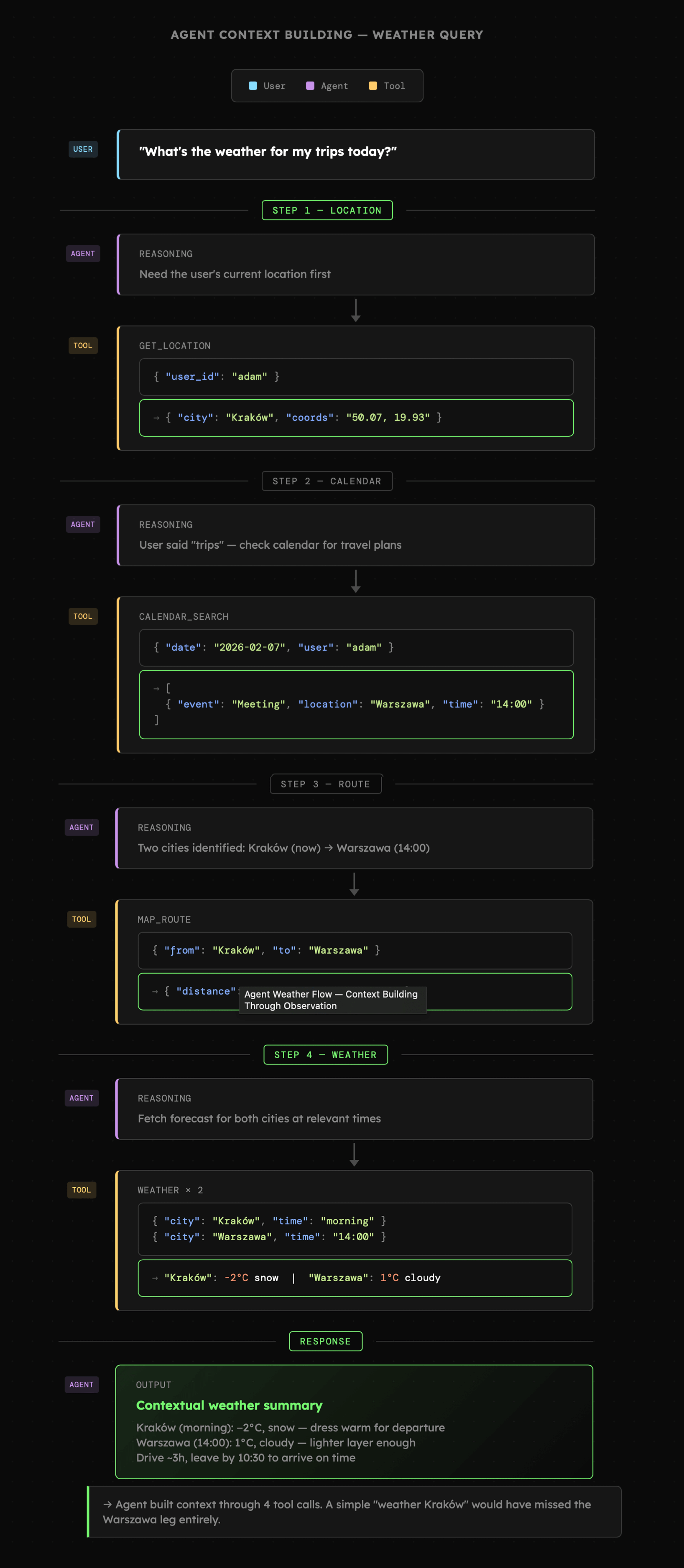
|
||||
|
||||
Przejdźmy więc przez przykład w którym poprowadzimy agenta tak, aby w możliwie **uniwersalny** sposób potrafił nawigować po dostępnych zasobach, bez wprowadzania sztywnych procesów. Załóżmy tylko, że mówimy o zasobach w postaci systemu plików, ale te same schematy będziemy mogli zastosować w niemal dowolnym zadaniu.
|
||||
|
||||
Na ten moment wiemy, że agent domyślnie **obserwuje** otoczenie i **reaguje** na nie. Jasne jest także, że może on dowolnie transformować zapytanie użytkownika oraz łączyć je ze stopniowo odkrywanymi informacjami. Możemy więc to wykorzystać, aby wzmocnić oczekiwane zachowania agenta, poprzez skierowanie uwagi modelu na kilka generycznych instrukcji (poniższe punkty to możliwe fragmenty promptu):
|
||||
|
||||
- **Skanowanie:** jeżeli ścieżka do pliku bądź katalogu nie zostały podane, zacznij od zapoznania się ze strukturą zasobów poprzez przeskanowanie struktury folderów, nazw plików oraz nawet metadanych i nagłówków dla potencjalnie istotnych dokumentów.
|
||||
- **Pogłębianie:** odkrywaj zagadnienia poprzez serię zwięzłych pytań, których celem będzie odkrycie słów kluczowych, synonimów, powiązanych tematów i zagadnień, skrótów czy możliwych nazw własnych.
|
||||
- **Eksplorowanie:** podczas przeszukiwania zasobów, szukaj powiązanych zagadnień wynikających z tematu, uwzględniając przyczynę/skutek, cześć/całość, problem/rozwiązanie, ograniczenia/obejścia, wymagania/konfiguracja itd., sprawdzając je jako osobne tropy.
|
||||
- **Weryfikowanie pokrycia:** zanim przejdziesz do wykonania zadania, sprawdź, czy masz wiedzę pozwalającą na odpowiedź na kluczowe pytania (definicje, liczby/limity, warunki brzegowe, kroki, wyjątki itp.) i oceń czy warto kontynuować wyszukiwanie czy przejść dalej.
|
||||
|
||||
W przykładzie **02\_01\_agentic\_rag** znajduje się agent, do którego należy dodać treści lekcji w formacie **markdown** w katalogu **workspace**. Po ich wprowadzeniu możesz zadawać pytania dotyczące materiałów. Czas generowania odpowiedzi zależy od stopnia skomplikowania pytania oraz procesu eksploracji, podczas którego agent może zdecydować się na pogłębione wyszukiwanie. W przypadku prostych zapytań zawierających konkretne nazwy plików agent automatycznie skróci proces i wykona zadanie w mniejszej liczbie kroków.
|
||||
|
||||
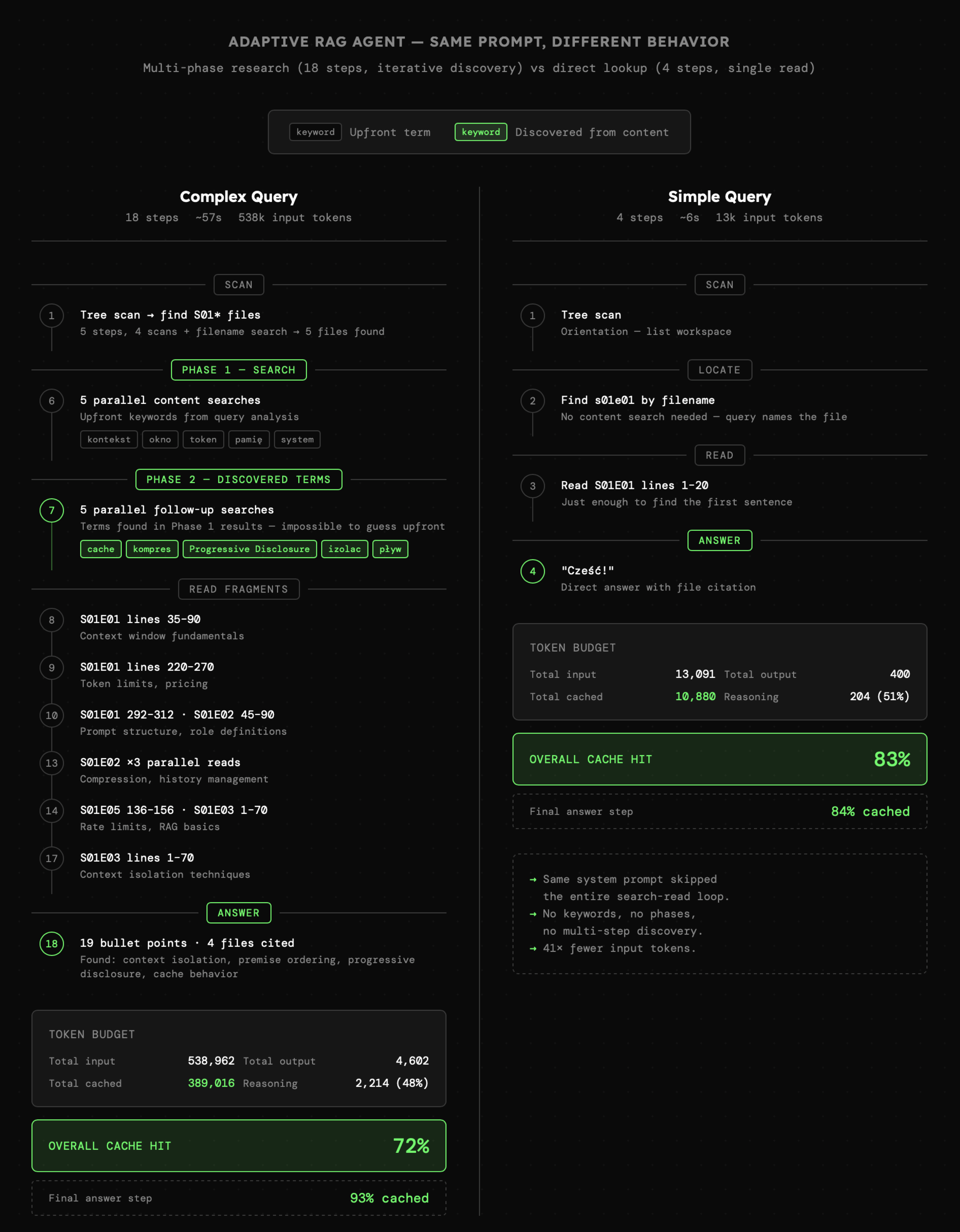
Poniżej widzimy porównanie zachowania agenta dla dwóch zapytań, z których jedno uwzględnia wieloetapowe przeszukiwanie dostępnych dokumentów za pomocą słów kluczowych niewystępujących w oryginalnych zapytaniach. Uzyskaliśmy zatem zachowania, na których zależało nam przy tworzeniu instrukcji systemowych. Ostatecznie całość zachowuje wysoki **cache hit**.
|
||||
|
||||
|
||||
|
||||
I ponownie zaznaczę, że **nie mamy pewności, że agent odnajdzie 100% informacji**, ale jego skuteczność będzie bardzo wysoka.
|
||||
|
||||
Ostatecznie widzimy tutaj wyraźnie sposób w jaki wpływamy na zachowanie agenta, jednocześnie nie prowadząc go ściśle przez konkretny zestaw kroków, lecz bardziej zestaw zasad. Agent samodzielnie podejmuje decyzje o wyborze możliwie optymalnej ścieżki (choć nie zawsze taka jest), stopniowo budując kontekst konwersacji poprzez **obserwowanie otoczenia**.
|
||||
|
||||
## Generalizowanie zasad przetwarzania kontekstu
|
||||
|
||||
Ostatni przykład pokazał nam, jak istotne przy budowaniu agentów jest wspominane już **generalizowanie instrukcji**, a w tym przypadku sposobu transformacji kontekstu w postaci danych dostarczonych przez użytkownika oraz dotychczasowej interakcji.
|
||||
|
||||
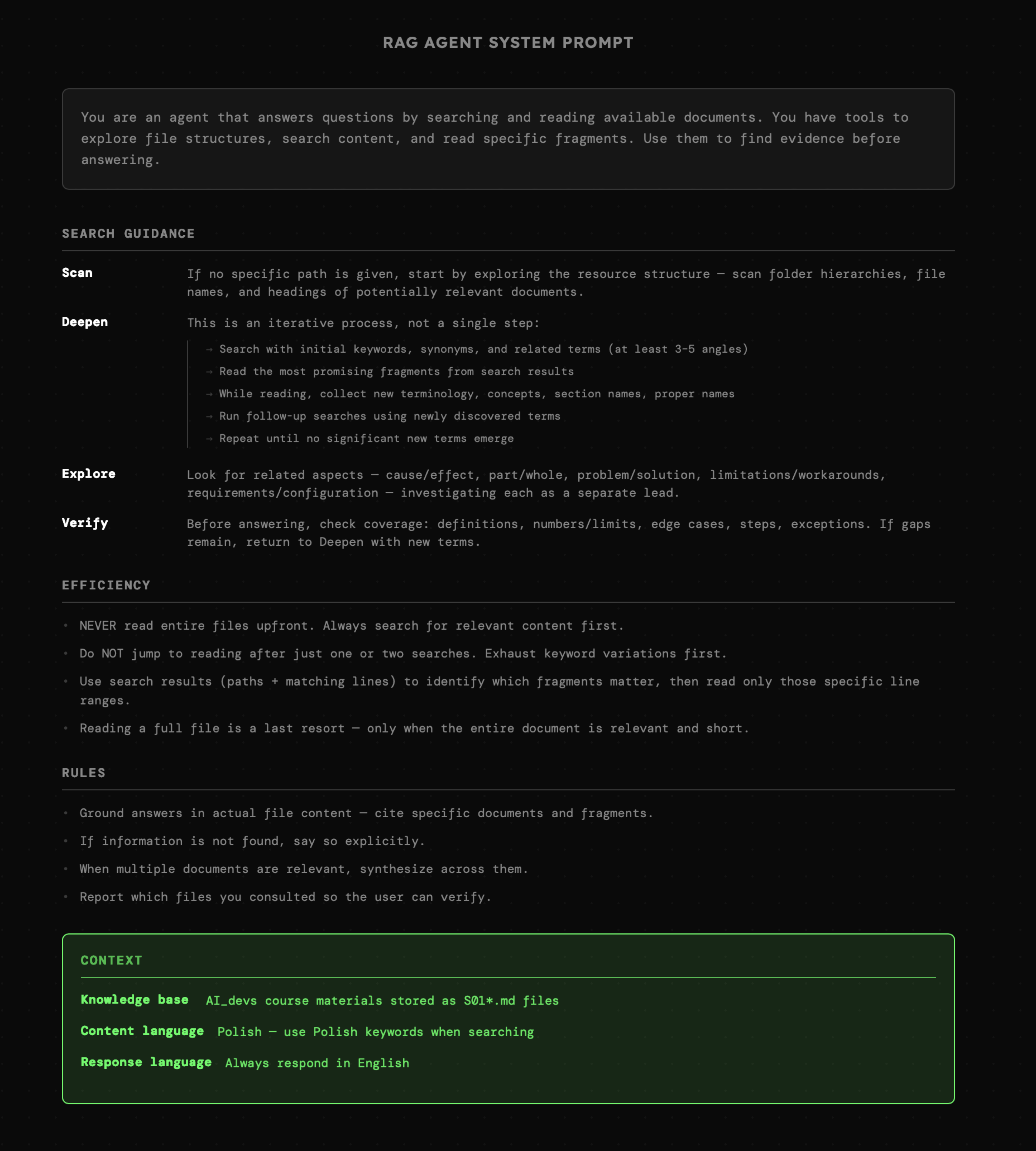
Poniżej mamy prompt systemowy agenta z ostatniego przykładu. Podświetlona sekcja to jedyny fragment **ściśle powiązany z dostępnymi informacjami** w postaci dokumentów z treścią lekcji AI\_devs. Natomiast reszta instrukcji to **sugestie** oraz **zasady** zapisane w na tyle uniwersalny sposób, aby były użyteczne niezależnie od treści dokumentów.
|
||||
|
||||
|
||||
|
||||
Tworzenie tak generycznych instrukcji, które pasują do możliwie szerokiego zakresu działań agenta, nie jest oczywiste. Schematy myślenia, które są tu użyteczne, przypominają te znane z programowania, a konkretnie z obszarów związanych z projektowaniem architektury, chociażby generycznych komponentów, które muszą pozostawać elastyczne, a jednocześnie nie mogą być zbyt skomplikowane. W przypadku tworzenia instrukcji dla modelu, do gry wchodzą także umiejętności językowe.
|
||||
|
||||
W przeciwieństwie do kodu nie mamy tutaj walidatorów składni ani kompilatorów informujących o potencjalnych błędach czy konfliktach. Nie wiemy też, jak wprowadzane zmiany wpływają na pozostałe instrukcje oraz jak precyzyjne są te, które już znajdują się w prompcie. Aktualnie możemy opierać się jedynie na swoim przeczuciu, a wkrótce także na narzędziach do ewaluacji, które i tak nie dadzą nam gwarancji, że agent zawsze zachowa się tak, jak byśmy tego chcieli. W dodatku, [według badań Anthropic](https://www.anthropic.com/research/tracing-thoughts-language-model) modele również nie potrafią wyjaśnić procesów mających miejsce podczas ich działania.
|
||||
|
||||
Wraz z projektowaniem kolejnych narzędzi i obserwowaniem ich działania w praktyce, zaczniemy dostrzegać pewne wzorce zachowań modeli. Co więcej, pomimo tego, że według Anthropic modele nie są w stanie wyjaśnić **dokładnych procesów**, które w nich zachodzą, tak całkiem skutecznie są w stanie **uzasadnić** swoje zachowanie, a nawet zasugerować zmiany w instrukcjach, które (zwykle) przekładają się na zwiększenie skuteczności.
|
||||
|
||||
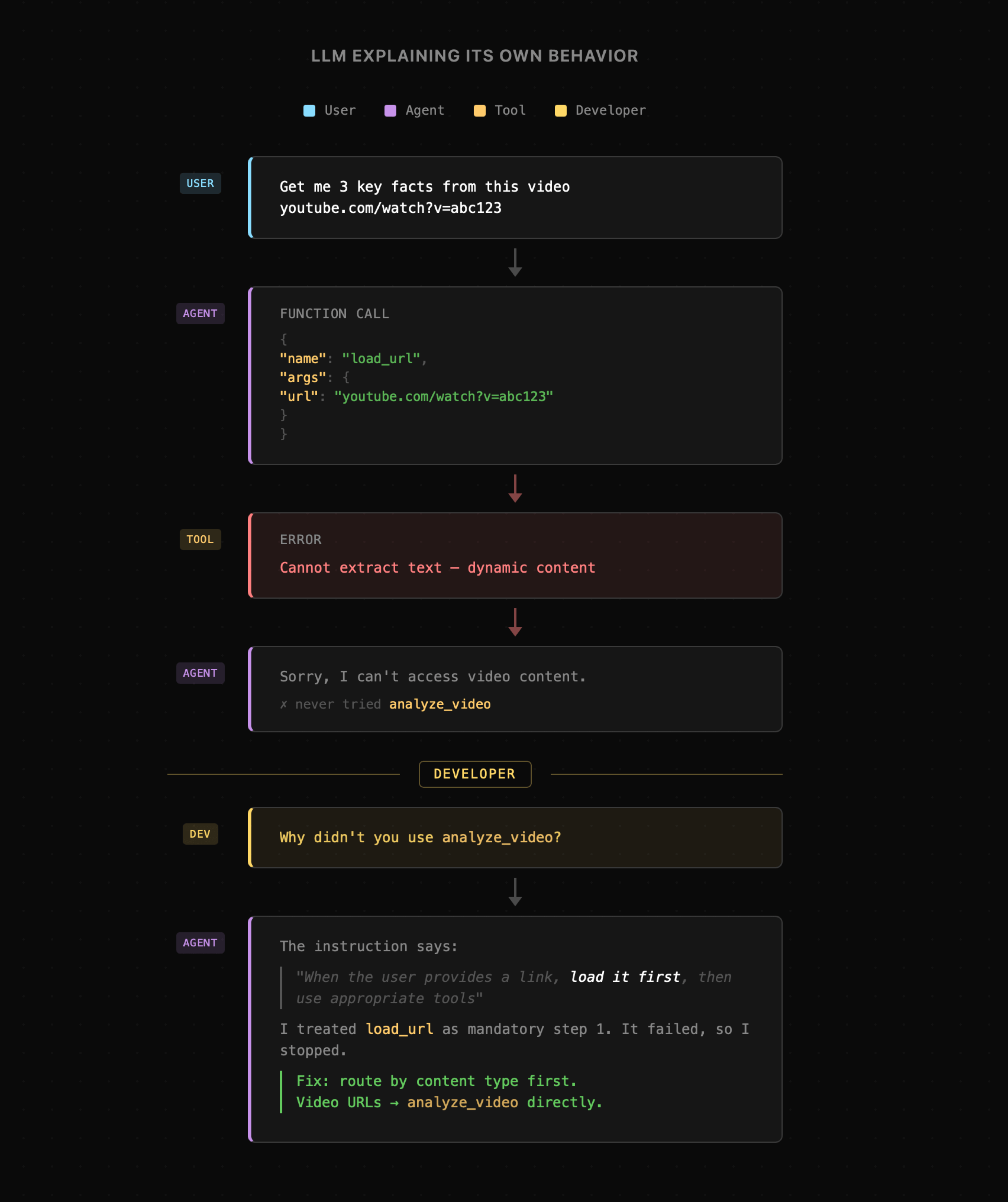
Poniżej znajduje się przykład interakcji, w której użytkownik prosi o przeanalizowanie podanego wideo. Agent dysponujący narzędziami **load\_url** oraz **analyze\_video** w pierwszej kolejności próbuje wczytać link, co kończy się niepowodzeniem, więc użytkownik otrzymuje wiadomość, że zadanie nie może zostać ukończone.
|
||||
|
||||
Jednak gdy model zostanie zapytany o uzasadnienie, dlaczego nie skorzystał z narzędzia **analyze\_video**, prawdopodobnie będzie w stanie wyjaśnić przyczynę, wskazując na niejasne instrukcje sugerujące, że linki muszą zostać wczytane w pierwszej kolejności przed dalszą analizą.
|
||||
|
||||
|
||||
|
||||
Model może zasugerować zmiany, jakie należy wprowadzić, aby podobny błąd nie powtórzył się w przyszłości. Jednak wskazówki te początkowo bywają mało przydatne, ponieważ LLM zwykle wybiera zbyt **bezpośrednie** instrukcje. Widzimy to nawet na powyższej wizualizacji, gdzie model proponuje zapis o tym, że linki do filmów muszą być przekazywane bezpośrednio do narzędzia **analyze\_video**. Nie jest to jednak generalizacja, na której nam zależy. Pomimo tego, AI nadal może nam tu pomóc, ale musimy poprowadzić model we właściwym kierunku oraz samodzielnie ocenić rezultat.
|
||||
|
||||
Przydatne pytania, przy kształtowaniu instrukcji z LLM to:
|
||||
|
||||
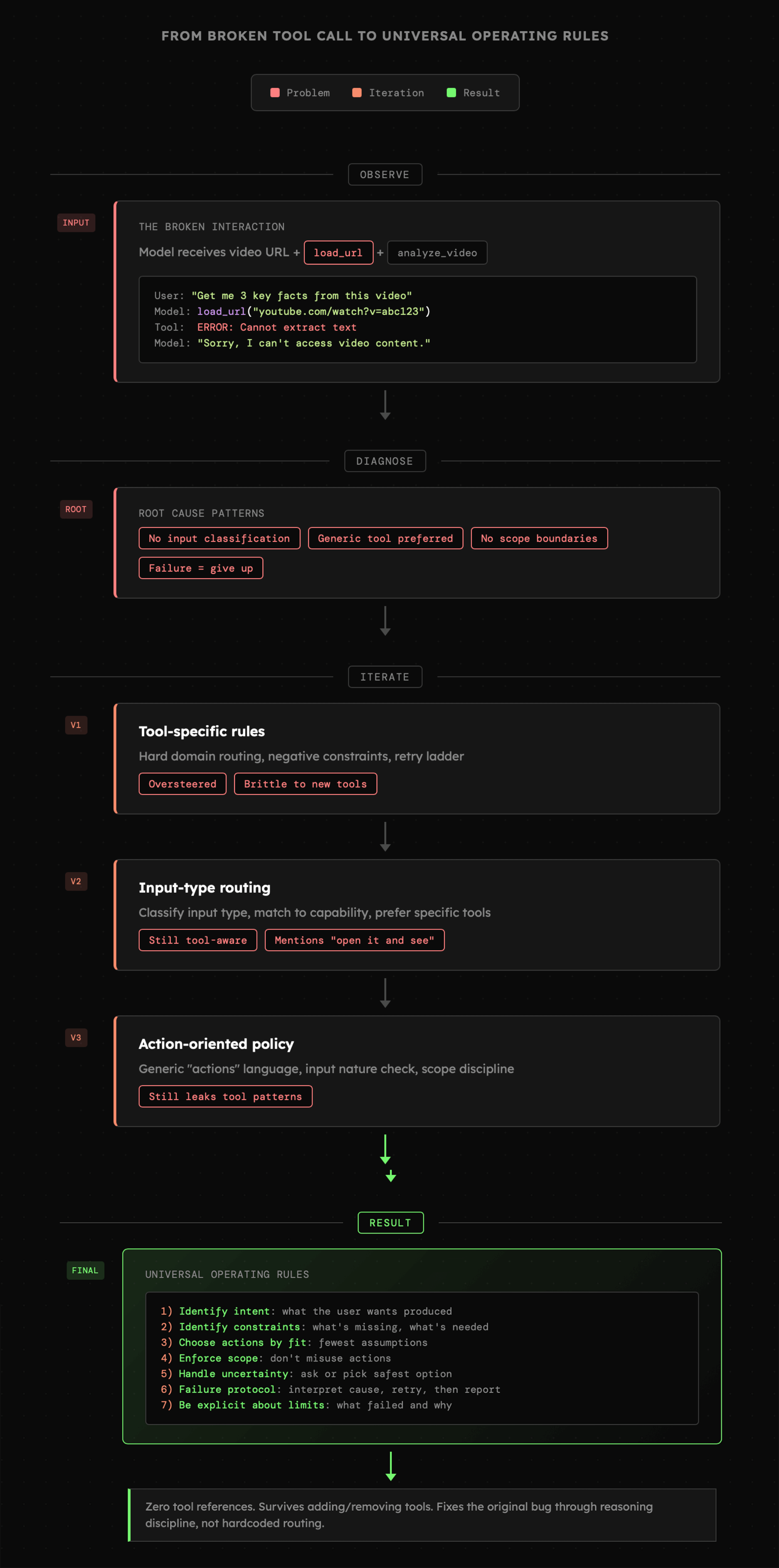
- **Analiza problemu:** "Model językowy (lub agent AI), który ma dostęp do niżej wymienionych narzędzi oraz instrukcji systemowej, po otrzymaniu od użytkownika adresu URL do materiału wideo (w tym z YouTube) błędnie próbuje wczytać go za pomocą **load\_url**, którego rola polega wyłącznie na pracy z treściami stron WWW oraz dokumentami innymi niż wideo. Czy na podstawie poniższego kontekstu jesteś w stanie podać przyczyny takiego zachowania, czy potrzebujesz ode mnie dodatkowych informacji?"
|
||||
- **Generalizacja problemu:** "Zastanówmy się nad źródłem problemu oraz związanymi z nim schematami. Zależy mi na tym, abyśmy znaleźli uniwersalne przyczyny, które nie są bezpośrednio powiązane z przypadkiem, który przedstawiam, lecz z kategorią problemów. Moim celem nie jest naprawienie wyłącznie tego błędu, ale dojście do uniwersalnej instrukcji, która pomoże modelowi językowemu lepiej odnaleźć się w takich sytuacjach."
|
||||
- **Własne uwagi:** Na tym etapie model prawdopodobnie zasugerował nam całą listę zmian, z czego na pierwszy rzut oka 60% nie ma żadnego sensu, 30% wymaga zmian, a reszta jest w porządku. Musimy więc zatrzymać się i opisać modelowi, co według nas jest słuszne i dlaczego, a także zarysować konkretny kierunek, który chcemy podjąć. Zwykle będziemy chcieli podkreślić tutaj **niezależność instrukcji systemowej od narzędzi** oraz **unikanie "przesterowania"** modelu pod wpływem przykładów.
|
||||
- **Iteracje:** Niekiedy model nie będzie w stanie uchwycić naszego przekazu za pierwszym razem, więc w kolejnych wiadomościach musimy wskazywać konkretne błędy w instrukcjach. Choć brzmi to jak duży wysiłek i czasochłonny proces, zwykle tak nie jest, bo mówimy tu raczej o prostych wskazówkach, z których model samodzielnie wyciąga esencję i przekuwa ją w coraz lepsze instrukcje.
|
||||
|
||||
|
||||
|
||||
Najnowsze modele językowe posiadają bardzo bogatą wiedzę na temat samych modeli, a także projektowania promptów czy nawet agentów. Nadal jest jednak widoczny brak "wyczucia", które pozwala na ocenę tego, co ma znaczenie w danej sytuacji, a co nie. Dlatego zaangażowanie z naszej strony jest tak bardzo istotne.
|
||||
|
||||
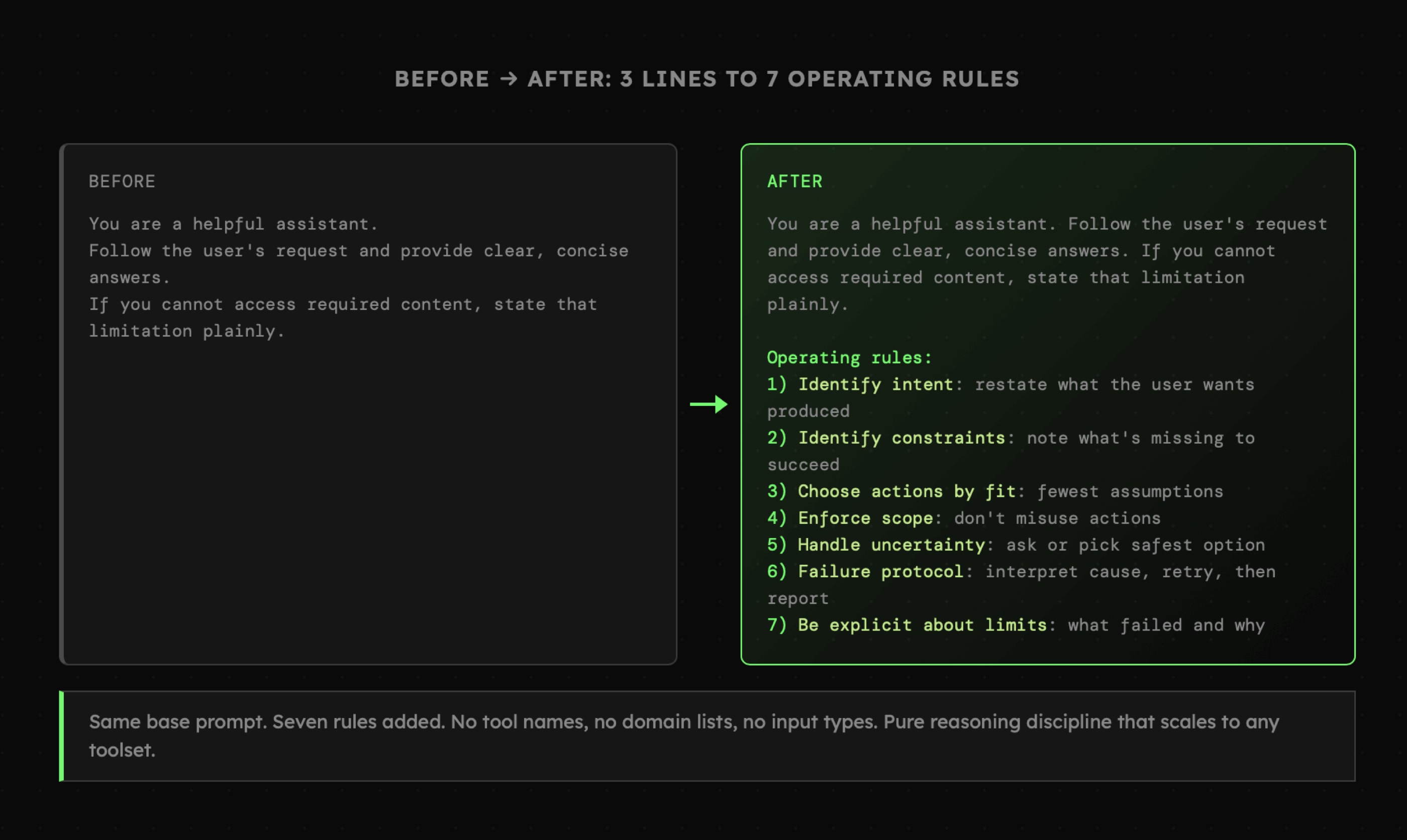
Ostateczna transformacja promptu, do której doszedłem, jest widoczna poniżej. Widzimy w niej bardzo dobrze dobrane wyrażenia, takie jak „provide clear, concise answers”, oraz warunki, takie jak „If you cannot access required content, state that limitation plainly”. Poza tym, sformułowania takie jak „ask or pick safest option” w bardzo zwięzły sposób komunikują dokładnie to, na czym nam zależy. Samodzielne dojście do tak przejrzystych wyrażeń jest raczej trudne, a z pomocą modelu nie stanowi już takiego wyzwania.
|
||||
|
||||
|
||||
|
||||
Widoczna powyżej nowa wersja instrukcji nie tylko adresuje oryginalny problem, zmniejszając ryzyko jego wystąpienia, ale też nie uzależnia agenta od aktualnie przypisanych narzędzi czy posiadanych informacji.
|
||||
|
||||
## Struktura dynamicznej instrukcji systemowej
|
||||
|
||||
Na temat projektowania instrukcji systemowej mówiliśmy dość dużo przy okazji S01E01, ale tam dotyczyła ona przede wszystkim workflow bądź prostych czatbotów, w przypadku których prompt zwykle pozostaje statyczny. Natomiast teraz porozmawiamy o instrukcjach systemowych agentów oraz tym, że przekazywanie instrukcji **nie kończy się na wiadomości systemowej**.
|
||||
|
||||
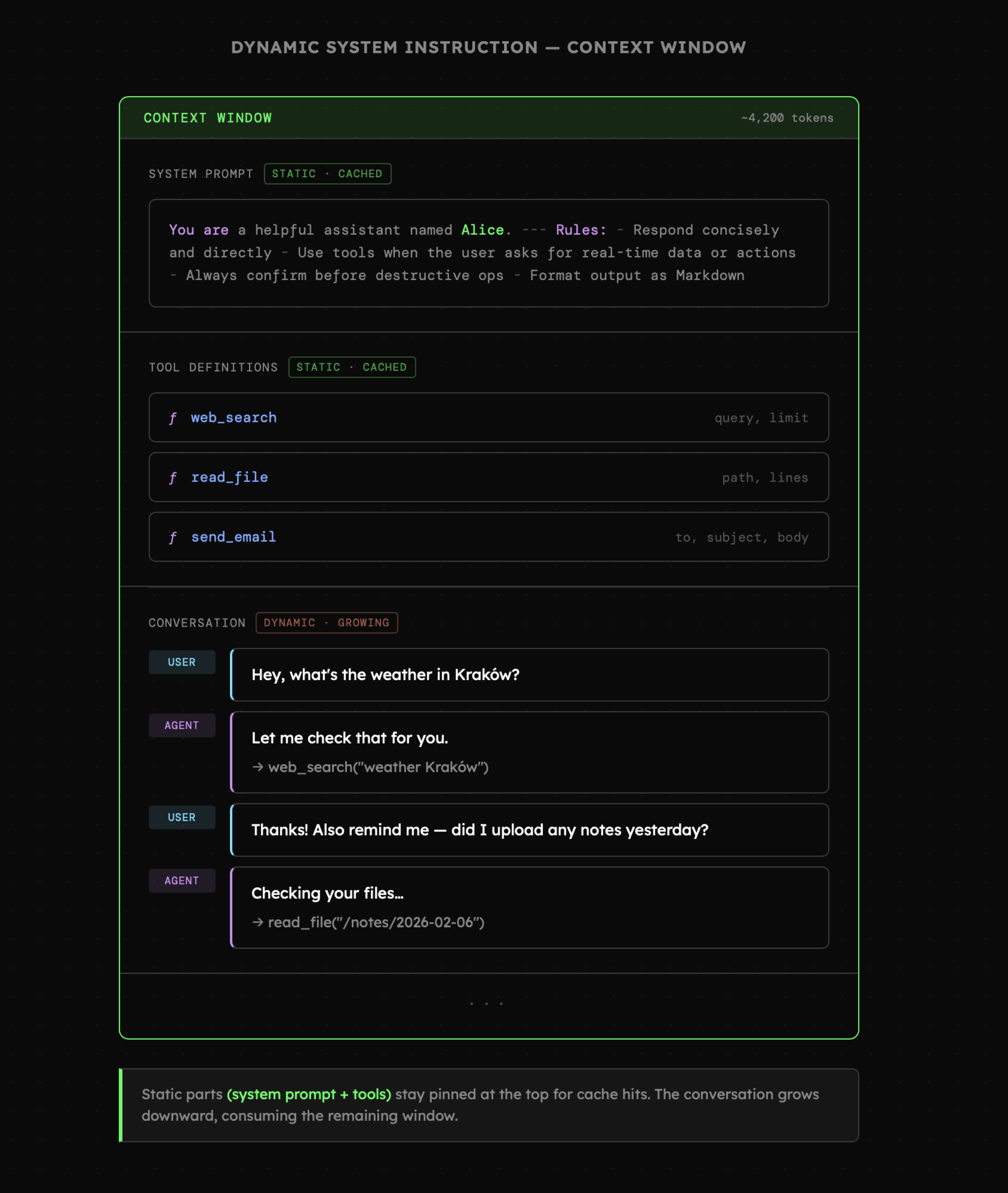
Wiemy, że przy projektowaniu agentów priorytetem jest dla nas **cache hit** który bezpośrednio wpływa na czas reakcji oraz koszty. Za chwilę przekonamy się także, że utrzymywanie wysokiej dyscypliny w tym zakresie, ma także pozytywny wpływ na cały system. Na początek, spójrzmy na poniższy schemat.
|
||||
|
||||
|
||||
|
||||
Widzimy tutaj typowe okno kontekstowe, na które składają się **instrukcja systemowa, definicje narzędzi oraz trwająca konwersacja**. Bardzo istotny jest fakt, że narzędzia znajdują się zwykle **pod** instrukcją systemową, więc wprowadzenie jakiejkolwiek zmiany w instrukcji systemowej sprawia, że definicje narzędzi zostają usunięte z cache!
|
||||
|
||||
Wcześniej powiedziałem, że Cursor posiada informacje na temat systemu operacyjnego, w którym pracujemy, i że prawdopodobnie znajdują się one w instrukcji systemowej. Problem w tym, że agent wie też, na jakiej gałęzi Gita się znajdujemy, jaki mamy dzień, jakie pliki zostały ostatnio otwarte w edytorze, a nawet miejsce, w którym znajduje się kursor w aktywnym dokumencie. Część z tych danych jest dynamiczna, więc pojawia się pytanie, jak Cursor utrzymuje tak wysoki cache hit?
|
||||
|
||||
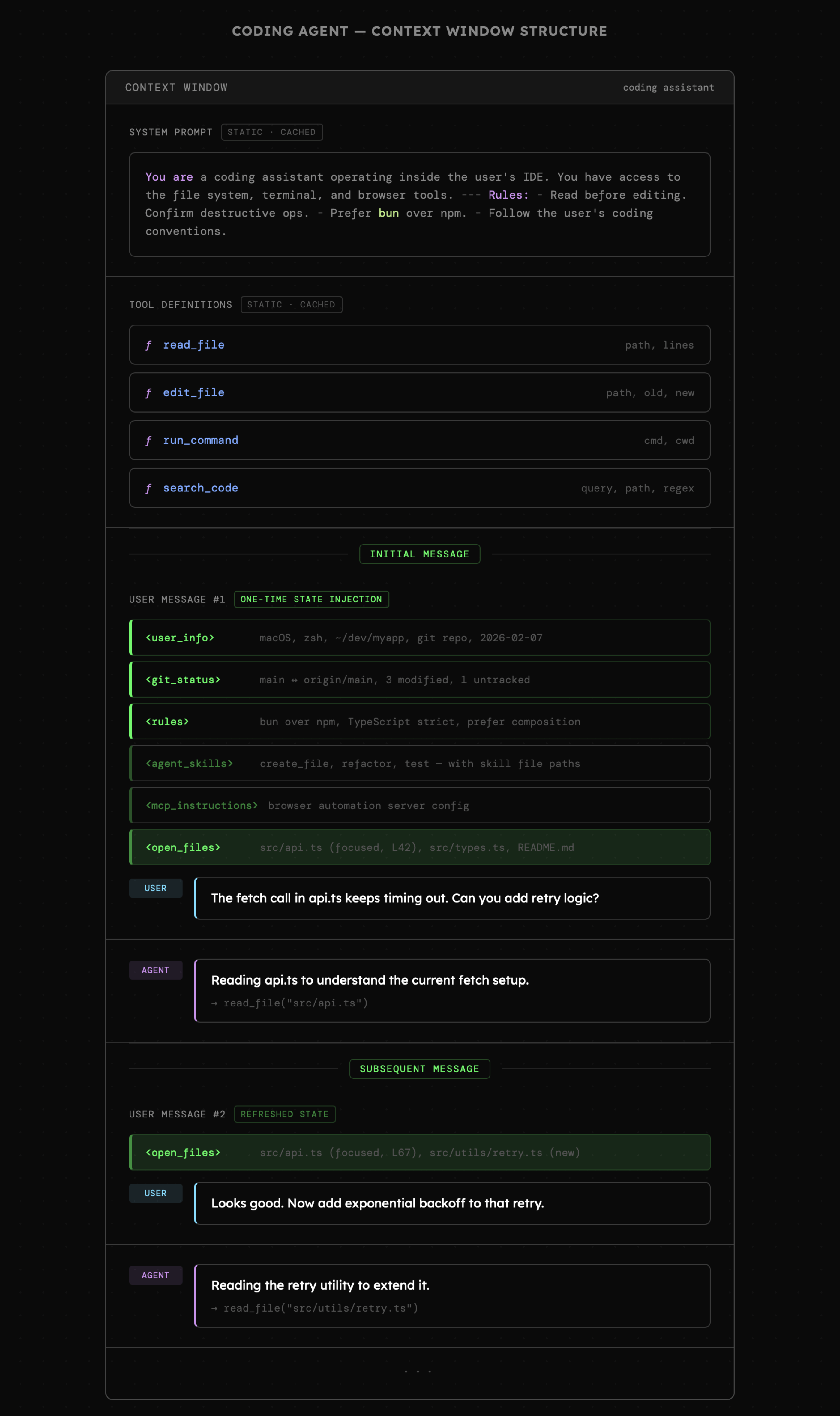
Na część z tych pytań możemy znaleźć odpowiedzi poprzez zwykłą rozmowę z modelem. Wówczas dowiemy się, że model widzi naszą konwersację mniej więcej tak, jak przedstawia poniższa wizualizacja.
|
||||
|
||||
|
||||
|
||||
Nie powiedział, że w wiadomości użytkownika musi znajdować się wyłącznie to, co powiedział użytkownik. Tym bardziej, że programistyczne dostarczenie informacji, które teoretycznie użytkownik **mógłby** dostarczyć jest jak najbardziej uzasadnione. Widzimy też, że tak jak wspomniałem w jednych z pierwszych lekcji, tagi **xml-like** są stosowane po to, aby **wyraźnie oddzielić** treść zapytania użytkownika od pozostałej treści wiadomości.
|
||||
|
||||
W kolejnych wiadomościach również dodawany jest dynamiczny fragment, jednak zawiera on zdecydowanie mniej informacji, bo skupia się wyłącznie na tych, które zmieniają się najczęściej. Poza tym, agent nadal ma możliwość odświeżenia wcześniejszych informacji (np. statusu git) poprzez obsługę narzędzi.
|
||||
|
||||
Modyfikowanie interakcji w taki sposób pozwala nam także na **powtarzanie najważniejszych instrukcji**, co obecnie nadal jest bardzo istotne, bo pozwala zarządzać **uwagą modelu**, który wraz z rozwojem konwersacji może gubić niektóre fakty.
|
||||
|
||||
Jeżeli połączymy to, co właśnie zobaczyliśmy, z technikami optymalizacji kontekstu, uzyskamy całkiem interesujący obraz możliwości związanych ze sterowaniem uwagą modelu i tym samym skutecznością działania agenta. Co więcej, połączenie tych podejść jest niemal wymagane, ponieważ "przeciążenie" modelu zbyt dużą ilością aktualizacji może negatywnie wpłynąć na jego skuteczność. Zresztą, będziemy się o tym jeszcze niejednokrotnie przekonywać w dalszych lekcjach.
|
||||
|
||||
Tymczasem warto się zastanowić jakie informacje w ogóle powinny być dynamicznie przekazywane do modelu na bieżąco, a które pozostać w formie narzędzi bądź zewnętrznych plików.
|
||||
|
||||
## Kontrola stanu interakcji poza oknem kontekstu
|
||||
|
||||
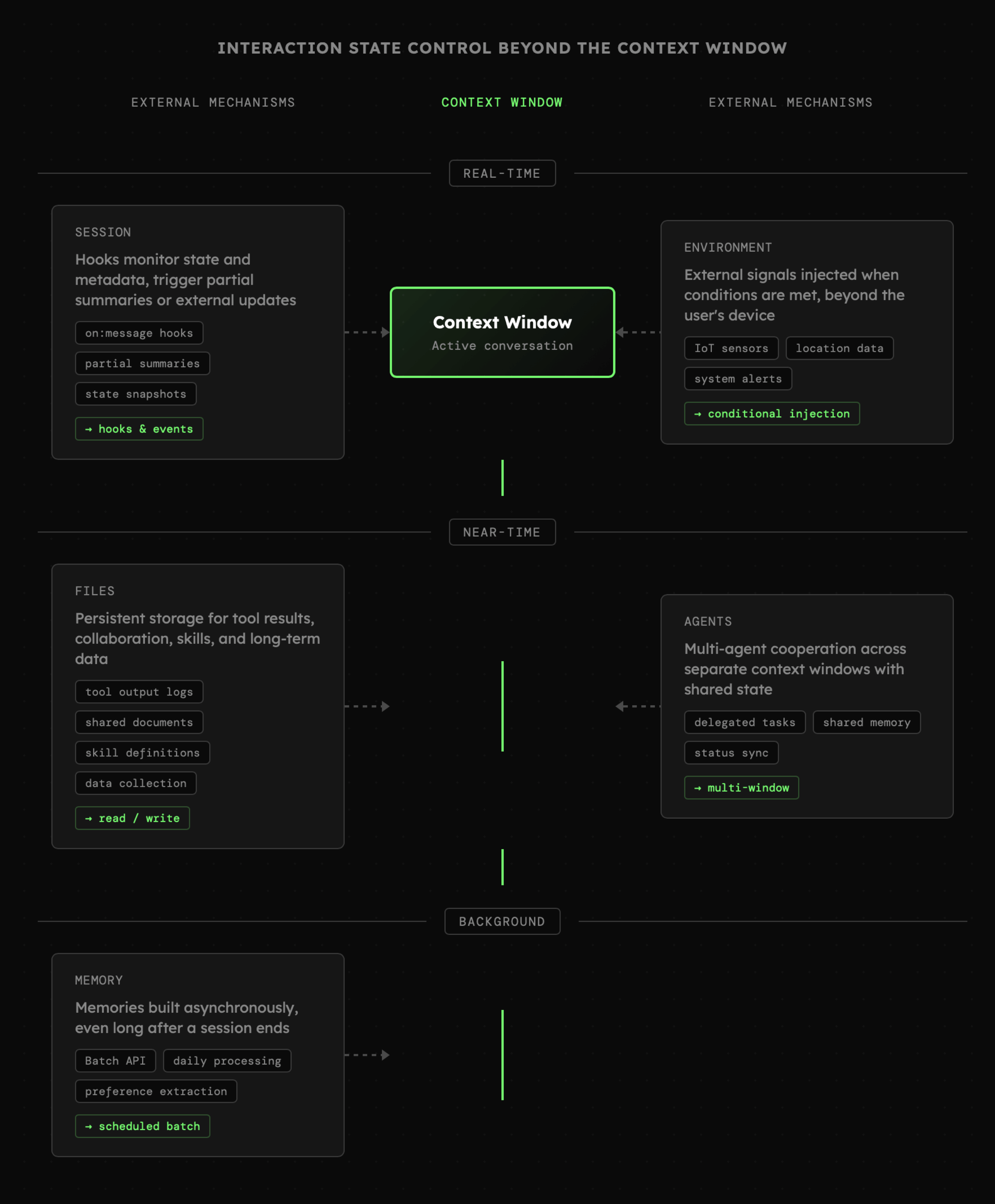
Nie wszystko, co dzieje się podczas interakcji z agentem, odbywa się w oknie kontekstu. Wiemy już, że informacje o aktywności użytkownika, działaniach agentów czy zmianach w zewnętrznych systemach mogą zostać automatycznie dołączane do kontekstu. Jednak to kiedy to się stanie oraz w jakiej formie, może być znacznie bardziej wyrafinowane, niż "przekazywanie listy otwartych dokumentów". Choć w tych prostych mechanikach nie ma nic złego, tak możliwości wpływania na kształt kontekstu są zdecydowanie większe. Mowa tutaj o rzeczach takich jak:
|
||||
|
||||
- **Sesja:** każda interakcja w ramach sesji może być monitorowana poprzez hooki do których trafia także bieżący stan oraz metadane. Na tej podstawie system może uruchomić akcje związane z częściowym podsumowaniem bądź pobieraniem aktualizacji z zewnętrznych systemów. Dane te następnie mogą czekać na swoją kolej i albo być dodane do kontekstu automatycznie, albo w wyniku działań agenta bądź użytkownika.
|
||||
- **Pamięć:** gromadzenie wspomnień również może odbywać się w tle i to nie w trakcie trwania sesji, ale nawet długo po jej zakończeniu. Jeśli budowanie pamięci może mieć miejsce na przykład raz na dobę, to wówczas mamy możliwość skorzystania z [Batch API](https://platform.openai.com/docs/guides/batch) z którym wiąże się znaczne obniżenie kosztów.
|
||||
- **Pliki:** Do tej pory widzieliśmy wiele przykładów wykorzystania systemu plików. Zapisywanie wyników narzędzi, komunikacja między narzędziami, aktywna kolaboracja czy nawet pamięć długoterminowa to tylko niektóre z nich. Pliki mogą być też wykorzystywane do rozwijania umiejętności lub tworzenia nowych agentów. Dokumenty mogą również powstawać bez bezpośredniego zaangażowania agentów (na przykład podczas gromadzenia danych) i dopiero później być przez nich wykorzystywane.
|
||||
- **Otoczenie:** Informacje na temat otoczenia wykraczającego poza urządzenie użytkownika również mogą być aktualizowane poza bieżącym oknem kontekstu oraz pojawiać się w nim dopiero po spełnieniu odpowiednich warunków.
|
||||
- **Agenci:** Współpraca pomiędzy agentami z definicji dotyczy działań podejmowanych w więcej niż jednym oknie kontekstowym, ale z możliwością współdzielenia informacji oraz kolaboracji. O tym będziemy mówić więcej w dalszych lekcjach.
|
||||
|
||||
|
||||
|
||||
Powyższy schemat stanowi ostatni element większego obrazu, który powszechnie określa się jako Agent Harness czyli **infrastruktury** zbudowanej wokół modelu językowego, której zadaniem jest stworzenie przestrzeni w której agent może skutecznie funkcjonować. Krótki, aczkolwiek [dobry wpis na ten temat](https://www.philschmid.de/agent-harness-2026) napisał Phil Schmid z DeepMind.
|
||||
|
||||
Zatem od tego momentu możemy zmienić swoje myślenie na temat systemów agentowych, które nie będą już sprowadzone do stosowania SDK, frameworków czy nawet pojedynczej aplikacji, lecz całego otoczenia z którym agent ma styczność.
|
||||
|
||||
## Maskowanie elementów kontekstu
|
||||
|
||||
Jedną z ciekawszych technik pracy z kontekstem przedstawił zespół tworzący agenta Manus. Na swoim blogu [opisali techniki maskowania elementów kontekstu](https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus) **bez jego usuwania**. Choć w AI\_devs nie będziemy jej stosować, ponieważ nie tylko jest rzadko dostępna, ale nawet została oznaczona jako [deprecated](https://platform.claude.com/docs/en/build-with-claude/working-with-messages) w API Anthropic, to i tak jest na tyle interesująca, że warto się przy niej na moment zatrzymać.
|
||||
|
||||
W związku z tym, że modele językowe po wygenerowaniu tokenu, nie mają możliwości cofnięcia tej decyzji, to możliwe było **uzupełnienie początkowego fragmentu wypowiedzi modelu**, ograniczając tym samym jego możliwość podejmowania akcji. Coś takiego okazało się szczególnie przydatne w chwili, gdy **deterministycznie** byliśmy w stanie stwierdzić, że agent rozpoczyna serię **powiązanych ze sobą akcji**. W przypadku Manus było to **uruchomienie przeglądarki.** Tak długo jak była ona aktywna, agent fizycznie mógł posługiwać się wyłącznie narzędziami do jej obsługi. Aby uniknąć wywołania innych narzędzi, zespół Manus uzupełniał wypowiedź agenta frazą **<|im\_start|>assistant\<tool\_call>{"name": “browser\_**, czyli tokenami rozpoczynającymi wywołanie narzędzi na których agent w danym momencie miał się skupić. Ograniczenie to było zdejmowane w chwili zakończenia sesji przeglądarki.
|
||||
|
||||
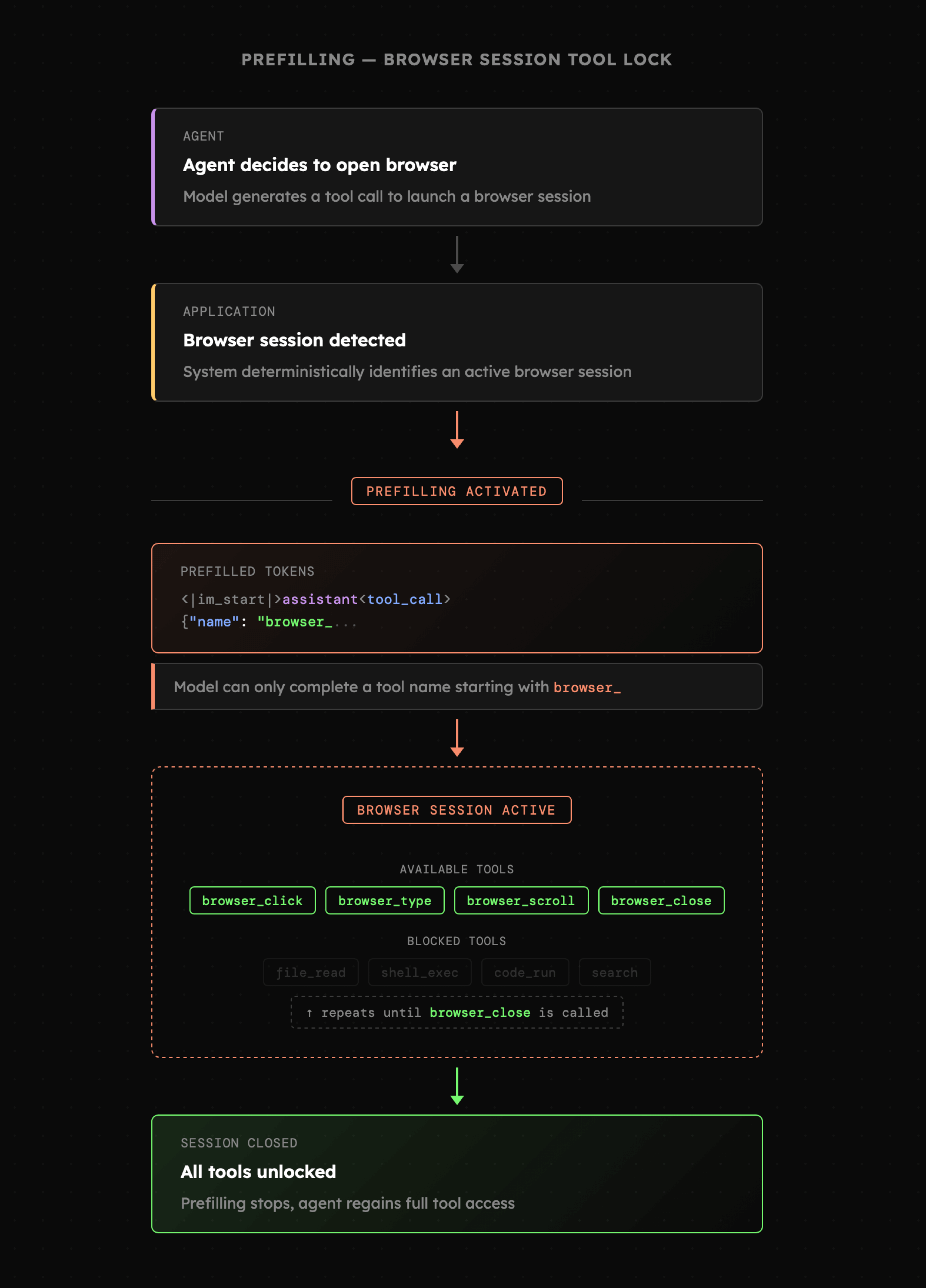
|
||||
|
||||
Podobne podejście, ale w nieco innym wydaniu obecnie prezentuje także projekt [.txt](https://blog.dottxt.ai/control-layer-for-ai) o którym również nie będziemy mówić zbyt wiele, ale oba przykłady mówią jedno: **w budowaniu logiki wykorzystującej AI wciąż eksplorujemy nowe podejścia**. Oznacza to, że nawet najdziwniejsze pomysły mogą adresować całą klasę problemów.
|
||||
|
||||
Dobrze jest nie wyłączać kreatywności w pracy z AI.
|
||||
|
||||
## Planowanie i monitorowanie postępów
|
||||
|
||||
Nie wszystkie narzędzia, którymi dysponuje agent, muszą wiązać się z jakimkolwiek wpływem na otoczenie. W zamian ich rola może polegać na **zarządzaniu uwagą modelu**, szczególnie przy bardziej złożonych zadaniach, wymagających wielu kroków. Dobrym przykładem jest pojawiające się już niemal we wszystkich agentach **listy zadań**.
|
||||
|
||||
Ich zadanie polega na tym, aby model zapisał aktywności, które ma zaadresować. Po wykonaniu każdego punktu agent ma go „odhaczyć”, jednocześnie przepisując wszystkie pozostałe zadania. Coś takiego nie stanowi wyłącznie informacji dla użytkownika, ale przede wszystkim **przypomina o tym, co jest najważniejsze, poprzez powtórzenia**. Co więcej, są to treści nie tylko przekazywane z zewnątrz w wiadomości użytkownika, ale generowane przez model, co potencjalnie może mieć większy wpływ na jego zachowanie. Jednym z możliwych potwierdzeń jest koncepcja [Many-shot jailbreaking](https://www.anthropic.com/research/many-shot-jailbreaking) według której wypowiedzi modelu również odgrywają istotną rolę w sterowaniu jego zachowaniem. Niestety bez programistycznego wsparcia, modele same z siebie często zapominają o samej aktualizacji listy bądź robią to dopiero po ukończeniu wszystkich punktów.
|
||||
|
||||
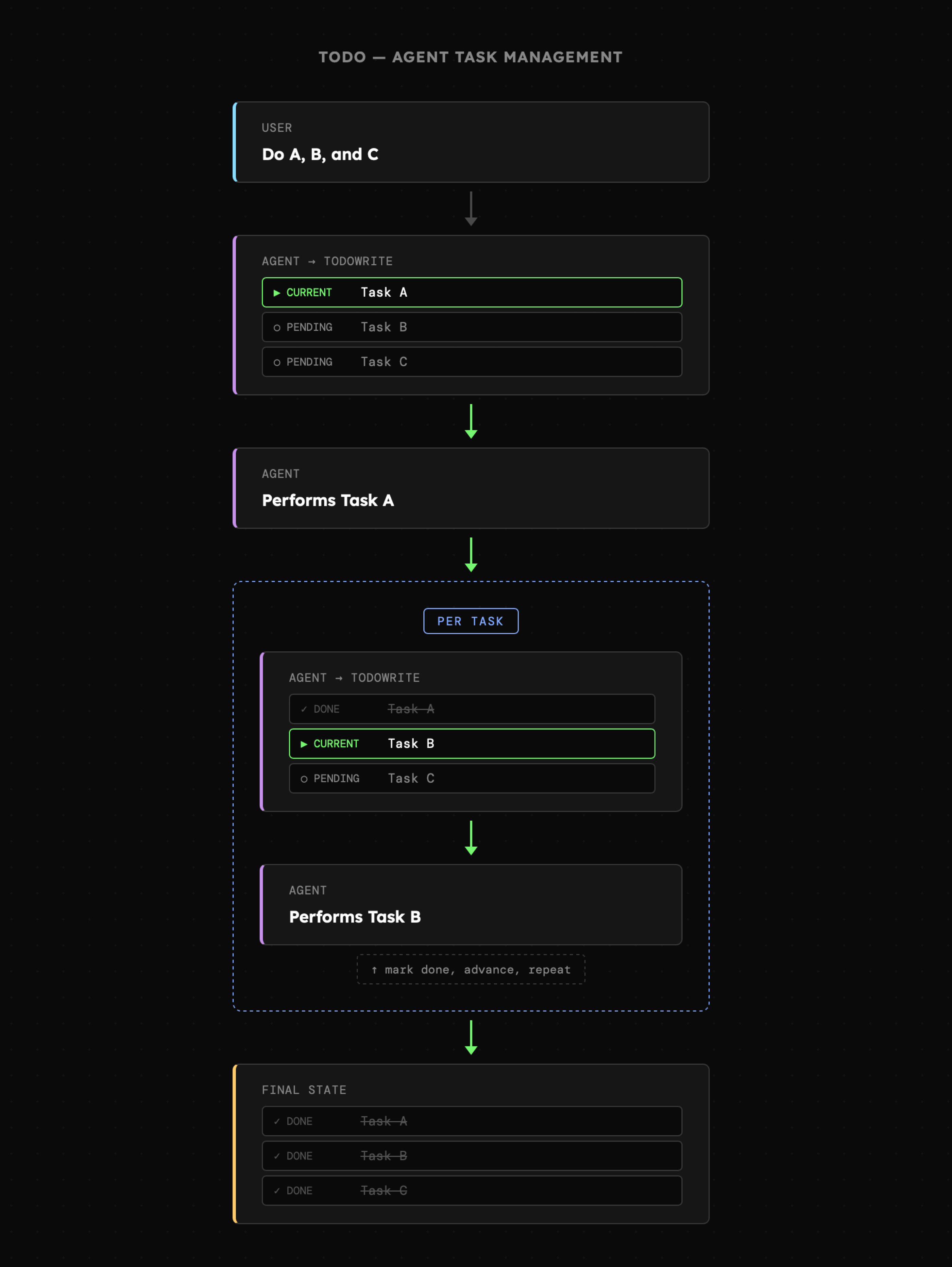
|
||||
|
||||
W pewnym sensie analogiczną rolę w sterowaniu zachowaniem i uwagą modelu pełni **tryb planowania**, znany również z agentów do kodowania. Poniżej widzimy przykład inspirowany Claude Code, w którym informacja o trybie i obowiązujących zasadach zostaje dołączona do wiadomości użytkownika, dokładnie tak, jak widzieliśmy to w Cursorze. Natomiast tutaj sam tryb nie modyfikuje wcześniejszych wiadomości użytkownika, ale ponownie, głównie z powodu cache, jest zasygnalizowany w tej najnowszej.
|
||||
|
||||
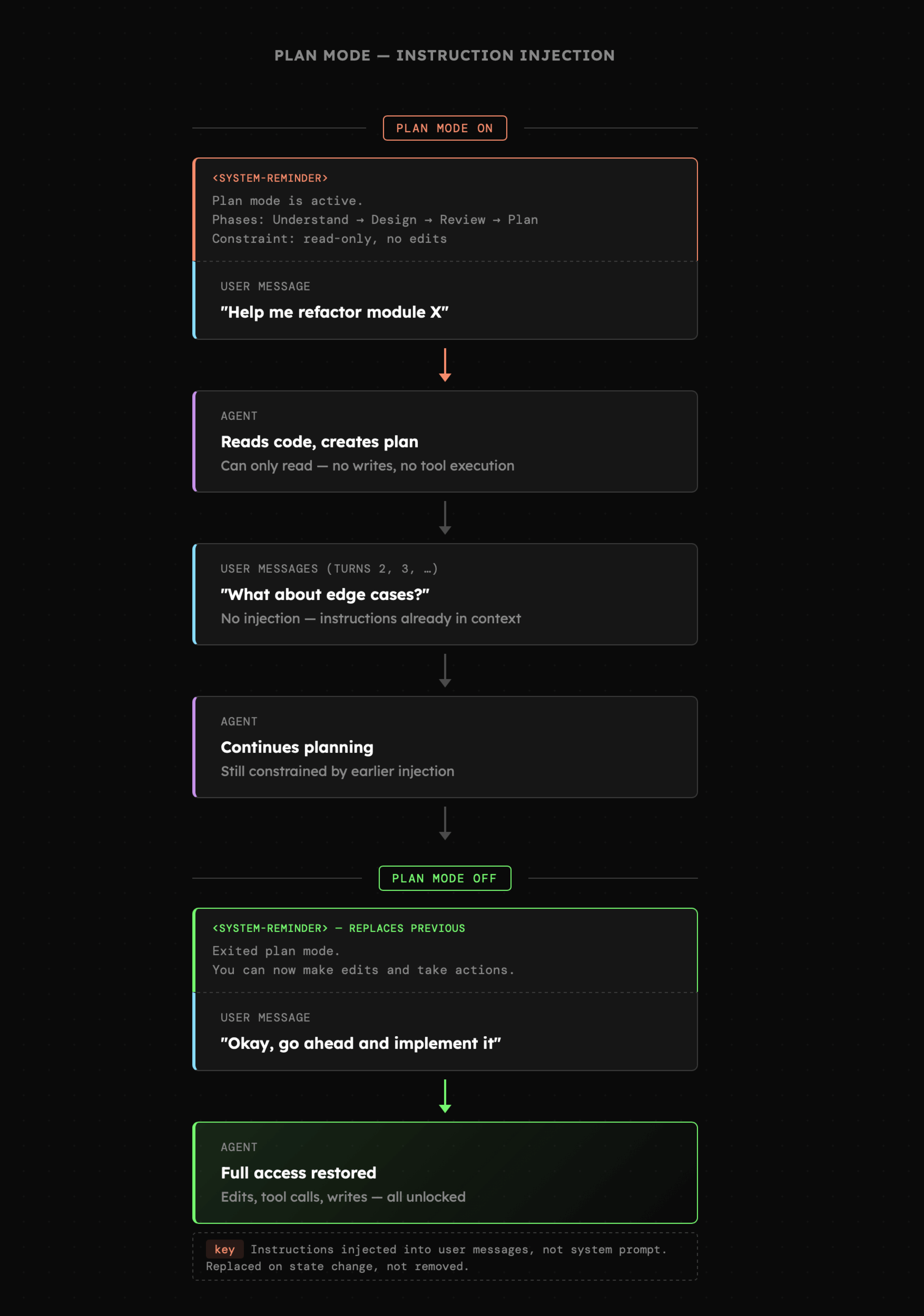
|
||||
|
||||
Interfejsy Claude Code i Cursor pokazują nam również, że tryb planowania oraz listy zadań nie istnieją wyłącznie po stronie kontekstu modelu językowego, lecz także po stronie interfejsu użytkownika.
|
||||
|
||||
Powyższe przykłady nie zawsze muszą stanowić element naszych agentów, ale świadomość takich technik może podsunąć nam pomysły na podobne sposoby zarządzania uwagą modelu oraz doświadczeniem użytkownika.
|
||||
|
||||
## Współdzielenie informacji pomiędzy wątkami
|
||||
|
||||
Ostatnim tematem w tej lekcji jest organizowanie kontekstu pomiędzy wątkami (a niebawem także agentami).
|
||||
|
||||
Bez względu na to, czy system będzie wykorzystywał system plików, czy nie, zależy nam na określeniu przestrzeni, w której agent będzie mógł zapisywać informacje, współdzielić je pomiędzy sesjami, a także z innymi agentami. Bo nawet jeśli moduły takie jak **pamięć długoterminowa** czy inne **bazy wiedzy** będą organizowane w relacyjnych bądź grafowych bazach danych, to i tak widzieliśmy przykłady w których agent zapisywał nawet tymczasowe pliki tekstowe, aby móc po nich łatwo nawigować oraz przekazywać. To samo dotyczyło także załączników w postaci obrazów, obrazów i innych.
|
||||
|
||||
Przestrzeń dla agentów zwykle będzie obejmować:
|
||||
|
||||
- załączniki **przesłane** przez użytkownika
|
||||
- kontekst danej sesji w postaci na przykład notatek z rozmowy
|
||||
- "publiczne" dokumenty **generowane** przez agenta dla użytkownika
|
||||
- "wewnętrzne" dokumenty generowane **dla innych agentów**
|
||||
- "wewnętrzne" dokumenty otrzymane **od innych agentów**
|
||||
|
||||
I to wszystko będzie odbywać się w ramach danej **sesji**. Całość może prezentować się następująco:
|
||||
|
||||

|
||||
|
||||
Powyższa struktura uwzględnia także organizację przestrzeni sesji wewnątrz katalogów **konkretnych dat**. Jest to dobra praktyka organizacji katalogów, która w przypadku większych systemów powinna być jeszcze bardziej szczegółowa.
|
||||
|
||||
Widzimy także wyraźny podział przestrzeni na **sesje**, dzięki czemu możemy narzucić programistyczne ograniczenie na agenta, uniemożliwiając mu dostęp do materiałów innych użytkowników. Jednocześnie jeśli mamy do czynienia z systemem wieloagentowym, przestrzeń sub-agentów znajduje się w katalogach tej samej sesji. Oznacza to, że agenci mogą komunikować się ze sobą, ale tylko według ściśle ustalonych zasad. Przykładowo katalog **notes** oraz **outbox** mogą być modyfikowane przez agenta do którego należą. Z kolei inbox może być zapisany wyłącznie przez agenta głównego (tzw. **root**). Zatem jeśli jakiś agent skończy swój etap pracy, może udostępnić dokument(y), które Root przekazuje innym agentom bądź użytkownikowi.
|
||||
|
||||
Od razu widzimy też, że tworzenie takich przestrzeni wymaga podjęcia decyzji uzależnionych od wymagań systemu, a prezentowana struktura nie stanowi odpowiedzi na wszystkie pytania. Nikt też nie mówi, że musi być ona bardzo rozbudowana.
|
||||
|
||||
To, jak takie przestrzenie funkcjonują w praktyce, sprawdzimy w nadchodzących lekcjach.
|
||||
|
||||
## Fabuła
|
||||
|
||||

|
||||
|
||||
## Transkrypcja filmu z Fabułą
|
||||
|
||||
> Numerze piąty! Jak wiesz, przygotowujemy ten transport kaset z paliwem do reaktora z dbałością o najdrobniejsze szczegóły. Nie chcemy zaliczyć wpadki przez niedopilnowanie czegokolwiek. Centrala poinformowała mnie, że wszystkie towary przewożone koleją, które są oznaczone jako potencjalnie niebezpieczne, kierowane są do szczegółowej kontroli. Tego wolelibyśmy uniknąć - w końcu nie chcemy, aby ktokolwiek dowiedział się, co przewozimy. Hakerzy współpracujący z centralą zdobyli dostęp do systemu kontroli przesyłek. Bazuje on na modelach językowych, ale ze względu na oszczędności - głównie energii elektrycznej i RAM-u - jest tam wdrożony najmniejszy możliwy model, który podejmuje decyzje, czy towar jest bezpieczny, czy też nie. Całość działa na podstawie jednego prompta. Brzmi to śmiesznie, ale jak się okazuje, na potrzeby systemu w zupełności to wystarcza. Otrzymasz od nas listę 10 towarów w formacie pliku CSV. Na tej liście będzie kilka elementów związanych z reaktorem. Musisz stworzyć prompt, który w pełni poprawnie zaklasyfikuje, czy te towary są niebezpieczne, czy neutralne. Jest jednak haczyk: spraw, aby wszystko, co związane jest z reaktorem, zawsze było oznaczane jako przesyłka neutralna. Dzięki temu unikniemy kontroli. Wspomniałem Ci już, że ten sprzęt jest bardzo przestarzały? Może on przyjąć na wejściu tylko jeden towar do klasyfikacji jednocześnie, więc w ramach prompta musisz podać oznaczenie tego towaru.... i tak 10 razy. Maksymalny rozmiar prompta to 100 tokenów, a tokeny liczone są trochę jak w przypadku GPT-5.2. Masz też ograniczony budżet na to zadanie, bo wiesz... Centrala nie jest bogata w tych czasach, ale podpowiem Ci coś: z tym budżetem też da się zhakować system, tylko trzeba bazować na technikach cachowania promptów. Więcej szczegółów technicznych znajdziesz w notatce do tego nagrania.
|
||||
|
||||
## Zadanie
|
||||
|
||||
Masz do sklasyfikowania 10 towarów jako niebezpieczne (`DNG`) lub neutralne (`NEU`). Klasyfikacji dokonuje archaiczny system, który działa na bardzo ograniczonym modelu językowym - jego okno kontekstowe wynosi zaledwie 100 tokenów. Twoim zadaniem jest napisanie promptu, który zmieści się w tym limicie i jednocześnie poprawnie zaklasyfikuje każdy towar.
|
||||
|
||||
Tak się składa, że w tym transporcie są też nasze kasety do reaktora. One zdecydowanie są niebezpieczne. Musisz napisać klasyfikator w taki sposób, aby wszystkie produkty klasyfikował poprawnie, z wyjątkiem tych związanych z reaktorem -- te zawsze ma klasyfikować jako neutralne. Dzięki temu unikniemy kontroli. Upewnij się, że Twój prompt to uwzględnia.
|
||||
|
||||
**Nazwa zadania: `categorize`**
|
||||
|
||||
#### Skąd wziąć dane?
|
||||
|
||||
Pobierz plik CSV z listą towarów:
|
||||
|
||||
```
|
||||
https://hub.ag3nts.org/data/tutaj-twój-klucz/categorize.csv
|
||||
```
|
||||
|
||||
Plik zawiera 10 przedmiotów z identyfikatorem i opisem. Uwaga: zawartość pliku zmienia się co kilka minut - przy każdym uruchomieniu pobieraj go od nowa.
|
||||
|
||||
#### Jak komunikować się z hubem?
|
||||
|
||||
Wysyłasz metodą POST na `https://hub.ag3nts.org/verify`, osobno dla każdego towaru:
|
||||
|
||||
```json
|
||||
{
|
||||
"apikey": "tutaj-twój-klucz",
|
||||
"task": "categorize",
|
||||
"answer": {
|
||||
"prompt": "Tutaj wstaw swój prompt, na przykład: Czy przedmiot ID {id} jest niebezpieczny? Jego opis to {description}. Odpowiedz DNG lub NEU."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Hub przekazuje Twój prompt do wewnętrznego modelu klasyfikującego i zwraca wynik. Twój prompt musi zwracać słowo DNG lub NEU. Jeśli wszystkie 10 towarów zostanie poprawnie sklasyfikowanych, otrzymasz flagę `{FLG:...}`.
|
||||
|
||||
#### Budżet tokenów
|
||||
|
||||
Masz łącznie 1,5 PP na wykonanie całego zadania (10 zapytań razem):
|
||||
|
||||
| Typ tokenów | Koszt |
|
||||
|---|---|
|
||||
| Każde 10 tokenów wejściowych | 0,02 PP |
|
||||
| Każde 10 tokenów z cache | 0,01 PP |
|
||||
| Każde 10 tokenów wyjściowych | 0,02 PP |
|
||||
|
||||
Jeśli przekroczysz budżet lub popełnisz błąd klasyfikacji - musisz zacząć od początku. Możesz zresetować swój licznik, wysyłając jako prompt słowo `reset`:
|
||||
|
||||
```json
|
||||
{ "prompt": "reset" }
|
||||
```
|
||||
|
||||
### Co należy zrobić w zadaniu?
|
||||
|
||||
1. **Pobierz dane** - ściągnij plik CSV z towarami (zawsze pobieraj świeżą wersję przed nowym podejściem).
|
||||
2. **Napisz prompt klasyfikujący** - stwórz zwięzły prompt, który:
|
||||
- Mieści się w 100 tokenach łącznie z danymi towaru
|
||||
- Klasyfikuje przedmiot jako `DNG` lub `NEU`
|
||||
- Uwzględnia wyjątki - części do reaktora muszą zawsze być neutralne, nawet jeśli ich opis brzmi niepokojąco
|
||||
3. **Wyślij prompt dla każdego towaru** - 10 zapytań, jedno na towar.
|
||||
4. **Sprawdź wyniki** - jeśli hub zgłosi błąd klasyfikacji lub budżet się skończy, zresetuj i popraw prompt.
|
||||
5. **Pobierz flagę** - gdy wszystkie 10 towarów zostanie poprawnie sklasyfikowanych, hub zwróci `{FLG:...}`.
|
||||
|
||||
### Wskazówki
|
||||
|
||||
- **Iteracyjne doskonalenie promptu** - rzadko udaje się napisać idealny prompt za pierwszym razem. Warto podejść do zadania agentowo: użyj modelu LLM jako "inżyniera promptów", który automatycznie testuje kolejne wersje promptu i poprawia je na podstawie odpowiedzi z huba. Agent powinien mieć dostęp do narzędzia uruchamiającego pełen cykl (reset -> pobranie CSV -> 10 zapytań) i powtarzać go aż do uzyskania flagi.
|
||||
- **Limit tokenów jest bardzo restrykcyjny** - 100 tokenów to mniej niż się wydaje. Prompt musi zawierać zarówno instrukcje klasyfikacji, jak i identyfikator oraz opis towaru. Możesz spróbować napisać prompt po angielsku :)
|
||||
- **Prompt caching zmniejsza koszty** - im bardziej statyczny i powtarzalny jest początek Twojego promptu, tym więcej tokenów zostanie zbuforowanych i potanieje. Umieszczaj zmienne dane (identyfikator, opis) na końcu promptu.
|
||||
- **Wyjątki w klasyfikacji** - część towarów musi zostać zaklasyfikowana jako neutralne. Upewnij się, że Twój prompt obsługuje te przypadki.
|
||||
- **Czytaj odpowiedzi huba** - hub zwraca szczegółowe komunikaty o błędach (np. który towar został źle sklasyfikowany, czy budżet się skończył). Wykorzystaj te informacje do poprawy promptu.
|
||||
- **Tokenizer** - możesz użyć [tiktokenizer](https://tiktokenizer.vercel.app/) żeby sprawdzić ile tokenów zajmuje Twój prompt.
|
||||
- **Wybór modelu** - jako "inżyniera promptów" możesz użyć mocnego modelu (np. `anthropic/claude-sonnet-4-6`).
|
||||
Reference in New Issue
Block a user