first commit
This commit is contained in:
@@ -0,0 +1,366 @@
|
||||
---
|
||||
title: Zarządzanie jawnymi oraz niejawnymi limitami modeli
|
||||
space_id: 2476415
|
||||
status: scheduled
|
||||
published_at: '2026-03-13T04:00:00Z'
|
||||
is_comments_enabled: true
|
||||
is_liking_enabled: true
|
||||
skip_notifications: false
|
||||
cover_image: 'https://cloud.overment.com/addressing-limitations-1772884465.png'
|
||||
circle_post_id: 30408538
|
||||
---
|
||||
Budując narzędzia wykorzystujące modele generatywnej sztucznej inteligencji, na każdym kroku będziemy spotykać ograniczenia. Część z nich ujawnia się dopiero z opóźnieniem, albo obserwujemy ich wpływ na aplikację bez jasnych sygnałów o źródle. Dlatego dziś gruntownie przejdziemy przez zagadnienia, których możemy spodziewać się na produkcji.
|
||||
|
||||
## Podstawy generatywnych aplikacji w środowisku produkcyjnym
|
||||
|
||||
Powiedzieliśmy już, że aplikacje wykorzystujące modele generatywnego AI są w około 80% tym, co znamy z codziennej pracy. Jednocześnie wpływ obecności modeli jest widoczny natychmiast i staje się szczególnie zauważalny, gdy aplikacja przechodzi z fazy prototypu, na produkcję. Dzieje się tak z kilku powodów, a o części z nich zdążyliśmy już wspomnieć:
|
||||
|
||||
- **Kontekst:** Skuteczność modeli zależy od kontekstu, a ten jest ograniczony.
|
||||
- **Kontrola:** Modele halucynują, a ich działanie jest nieprzewidywalne.
|
||||
- **Wydajność:** Modele generatywnego AI są aktualnie bardzo wolne.
|
||||
- **Dynamiczne koszty:** Inferencja jest rozliczana na podstawie przetworzonych tokenów.
|
||||
- **Bezpieczeństwo:** Prompt Injection pozostaje problemem otwartym.
|
||||
- **Stabilność:** Większość dostawców nadal ma problemy ze stabilnością API.
|
||||
- **Skalowanie:** Na skali występują problemy z limitami API oraz kosztami.
|
||||
- **Prywatność:** Dalsze trenowanie modelu na naszych danych jest potencjalnie możliwe.
|
||||
- **Naruszenia:** Niepożądane zachowania użytkowników mogą prowadzić do blokad API.
|
||||
- **Elastyczność:** Wzrost możliwości modeli i rozwój toolingu wymaga utrzymania dużej elastyczności architektury aplikacji oraz nierzadko także modelu biznesowego.
|
||||
|
||||
Powyższe problemy ujawniają się bardzo szybko, niekiedy już przy pierwszych użytkownikach, a ich sprawne rozwiązanie nie zawsze okazuje się możliwe, nawet pomimo potencjału generowania kodu i szybkiego iterowania funkcjonalności. Przyjrzyjmy się więc każdemu z nich.
|
||||
|
||||
**Kontekst**
|
||||
|
||||
Widzieliśmy już sporo przykładów wpływu treści okna kontekstowego na zachowanie modelu i jeszcze wiele będziemy o tym mówić. Natomiast w kontekście produkcyjnym należy pamiętać o kilku aspektach:
|
||||
|
||||
- jeśli użytkownik ma możliwość dostarczenia własnych dokumentów, to możemy być niemal pewni, że część z nich będzie miało formę kilkusetstronicowych dokumentów PDF czy docx i musimy się na to przygotować.
|
||||
- jeśli użytkownik ma możliwość podłączenia MCP bądź wbudowanych integracji, to z pewnością niektórzy spróbują aktywować setki narzędzi jednocześnie
|
||||
- użytkownicy nie będą mieć wiedzy na temat LLM i na przykład limitów okna kontekstowego. Będą więc oczekiwać możliwości prowadzenia nieskończonych rozmów i realizowania zadań w długim horyzoncie czasu
|
||||
- wszędzie tam gdzie istnieje potencjał na "przepalanie" tokenów czy uruchomienie akcji w sposób, który może przełożyć się na negatywne konsekwencje (na przykład usunięcie danych), musimy uwzględnić programistyczne ograniczenia.
|
||||
|
||||
Powyższe punkty bynajmniej nie stanowią zarzutu wobec użytkowników, ponieważ trudno jest od nich wymagać wiedzy o mechanice agentów czy działaniu modeli językowych. Po prostu te wszystkie rzeczy musimy wziąć pod uwagę przy projektowaniu generatywnych aplikacji.
|
||||
|
||||
Na temat zarządzania kontekstem będziemy jeszcze rozmawiać, ale nie można go teraz pominąć, ponieważ jest to obszar wpływający na wszystkie aspekty oprogramowania oraz samego produktu - doświadczenia użytkownika, skuteczność, bezpieczeństwo, szybkość działania, cenę i tym samym także rentowność.
|
||||
|
||||
**Kontrola**
|
||||
|
||||
LLM sterujący logiką aplikacji będzie popełniał błędy. System powinien umożliwić mu ich samodzielną naprawę bądź wymagać zaangażowania człowieka albo **przed** wykonaniem akcji, albo **po** jej zakończeniu w celu weryfikacji. Wiemy, że automatyczna naprawa (error recovery) jest możliwa w przypadku agentów, o ile system dostarczy wystarczających informacji o tym, co się wydarzyło i ewentualnie, co można z tym zrobić.
|
||||
|
||||
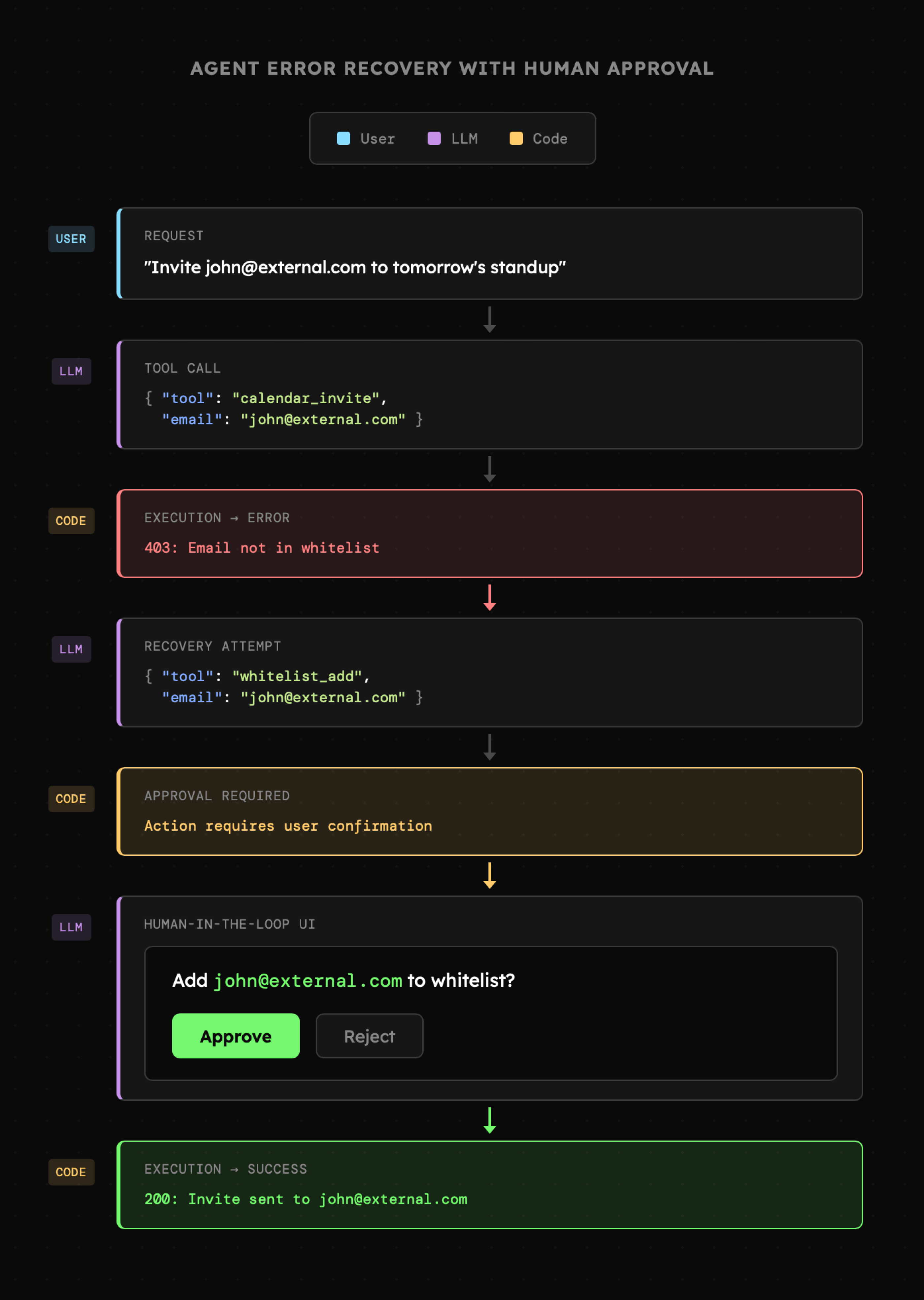
Poniżej widzimy interakcję w której użytkownik prosi o **dodanie wydarzenia** z zaproszeniem wskazanej osoby na spotkanie. Jej adres jednak **nie znajduje się na liście dopuszczalnych kontaktów** i agent zostaje o tym poinformowany. W związku z tym decyduje się na **dodanie kontaktu**, ale to wymaga potwierdzenia ze strony użytkownika. Potwierdzenie to odbywa się poprzez **interfejs graficzny**, czyli **deterministyczną akcję**, która redukuje ryzyko pomyłki. Dodatkowo agent **nie określa "nadawcy"**, ponieważ sesja użytkownika zawiera już tę informację.
|
||||
|
||||
|
||||
|
||||
Z powyższym przykładem jest jednak kilka problemów:
|
||||
|
||||
- Adresy dodane do listy mogą zostać pomylone, więc zaproszenie trafi do **niewłaściwej osoby**
|
||||
- Opis wydarzenia może zawierać informacje pochodzące **z innych narzędzi** (np. poczty e-mail bądź wewnętrznej bazy wiedzy), co może doprowadzić do udostępnienia niechcianych danych.
|
||||
- Zatem potwierdzenie **musi** zawierać wszystkie detale zaproszenia, a nie jedynie adres e-mail.
|
||||
|
||||
Widzimy więc, że system musi być zaprojektowany tak, aby użytkownik miał **kontrolę** nad działaniami agenta. Niekiedy będzie to nieakceptowalne, ale jeśli się chwilę zastanowimy, to do pomyłkowego dodania złego adresu do spotkania może dojść nawet bez AI w wyniku literówki bądź kliknięcia w niewłaściwe miejsce.
|
||||
|
||||
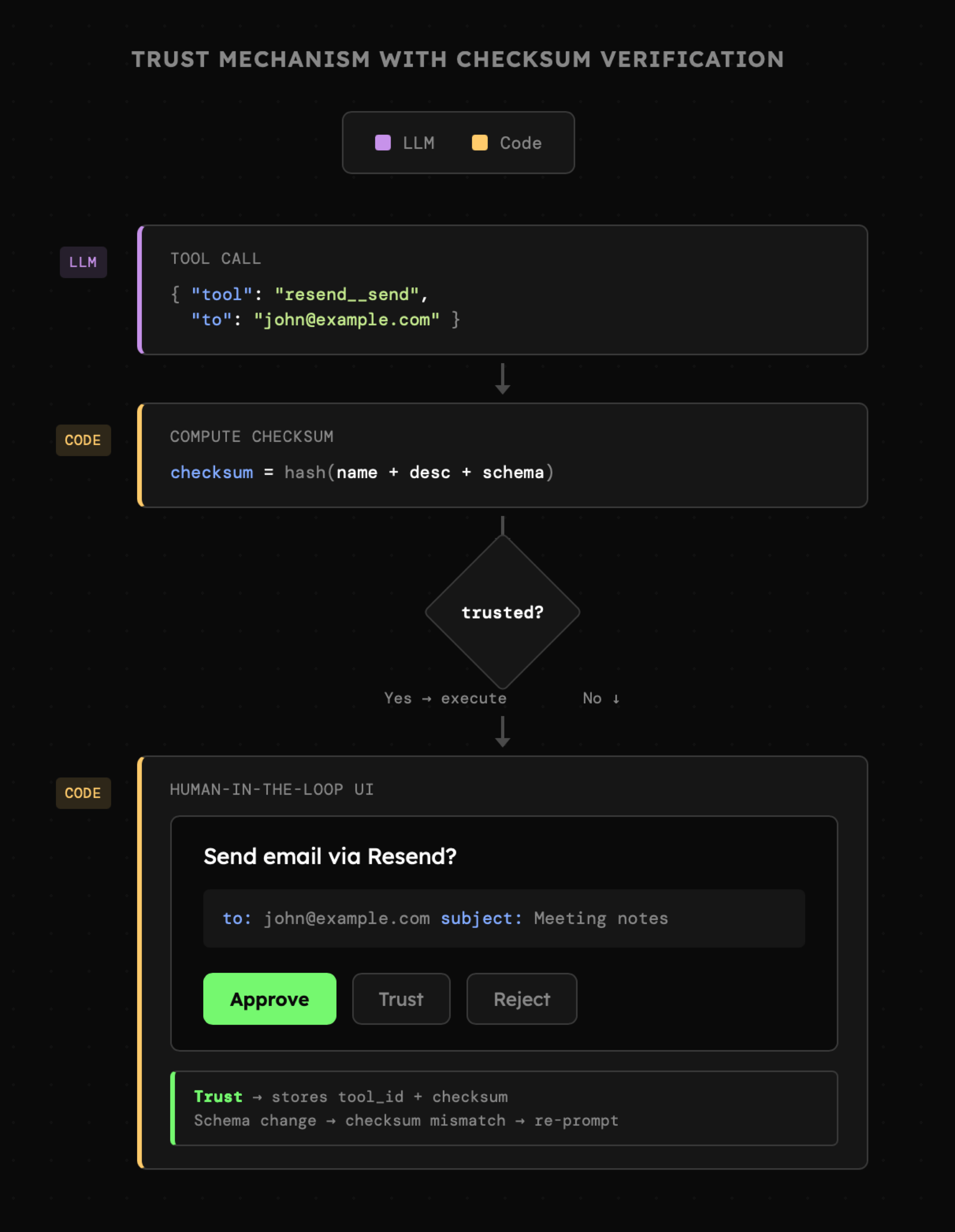
W przykładzie **[01\_05\_confirmation](https://github.com/i-am-alice/4th-devs/tree/main/01_05_confirmation)** znajduje się agent posiadający dostęp do platformy [Resend](https://resend.com/) dzięki której może wysyłać wiadomości e-mail na adresy zapisane w pliku **whitelist.json** (należy tam wpisać swój adres). Gdy po podłączeniu naszego klucza API poprosimy o przesłanie wiadomości na nasz adres, zostaniemy poproszeni o **potwierdzenie tej akcji** opierające się o **"fizyczne" przyciski** takie jak **Akceptuj**, **Zaufaj** oraz **Anuluj**.
|
||||
|
||||
Mechanizm "zaufanych" akcji jest kluczowy dla komfortu użytkownika, ponieważ ręczne zatwierdzanie każdego kroku agenta szybko staje się uciążliwe. Z tego powodu uruchomienie konkretnego narzędzia można dodać do listy wyjątków, co sprawi, że jego kolejne użycie nie będzie już wymagało osobnej zgody. Przy implementacji tego mechanizmu należy pamiętać, aby:
|
||||
|
||||
- Narzędzie było dodane do listy zaufanych w sposób bezkolizyjny, np. na podstawie identyfikatora, bądź unikatowej nazwy składającej się z nazwy "serwera (np. MCP)" oraz "akcji". Przykładowo **resend\_\_send**.
|
||||
- Narzędzie powinno być automatycznie **usunięte** z listy zaufanych jeśli zmieni się jego struktura - nazwa, opis, bądź schemat. Jest to **krytyczne** szczególnie w przypadku serwerów MCP, których interfejs może zmienić się **bez wiedzy użytkownika (!)**
|
||||
- Zatwierdzenie bądź odrzucenie akcji **musi być deterministyczne** i odbywać się przez kod, a nie decyzję LLM.
|
||||
|
||||
|
||||
|
||||
Na powyższych przykładach widzimy wyraźnie, że utrzymanie kontroli jest możliwe, ale jedynie do pewnego stopnia. Wszędzie tam, gdzie agent ma dostęp do danych i akcji, musimy brać pod uwagę, że coś może pójść nie tak i informacje z jednego źródła zostaną przekazane do drugiego. Dlatego problem ten musi być adresowany na poziomie założeń projektowych i jeśli przypadkowe przesłanie danych w niepożądane miejsce jest niedopuszczalne, a akceptacja ze strony użytkownika nie będzie wystarczająca, tam wdrożenie LLM jest **nierekomendowane**.
|
||||
|
||||
**Wydajność**
|
||||
|
||||
Na temat wydajności rozmawialiśmy już w S01E02 w kontekście optymalizacji narzędzi. Wszystkie omówione tam techniki mają zastosowanie do całościowej interakcji z modelami. Na produkcji musimy uwzględnić jeszcze kilka dodatkowych obszarów związanych z wydajnością, które jednocześnie są powiązane z architekturą aplikacji:
|
||||
|
||||
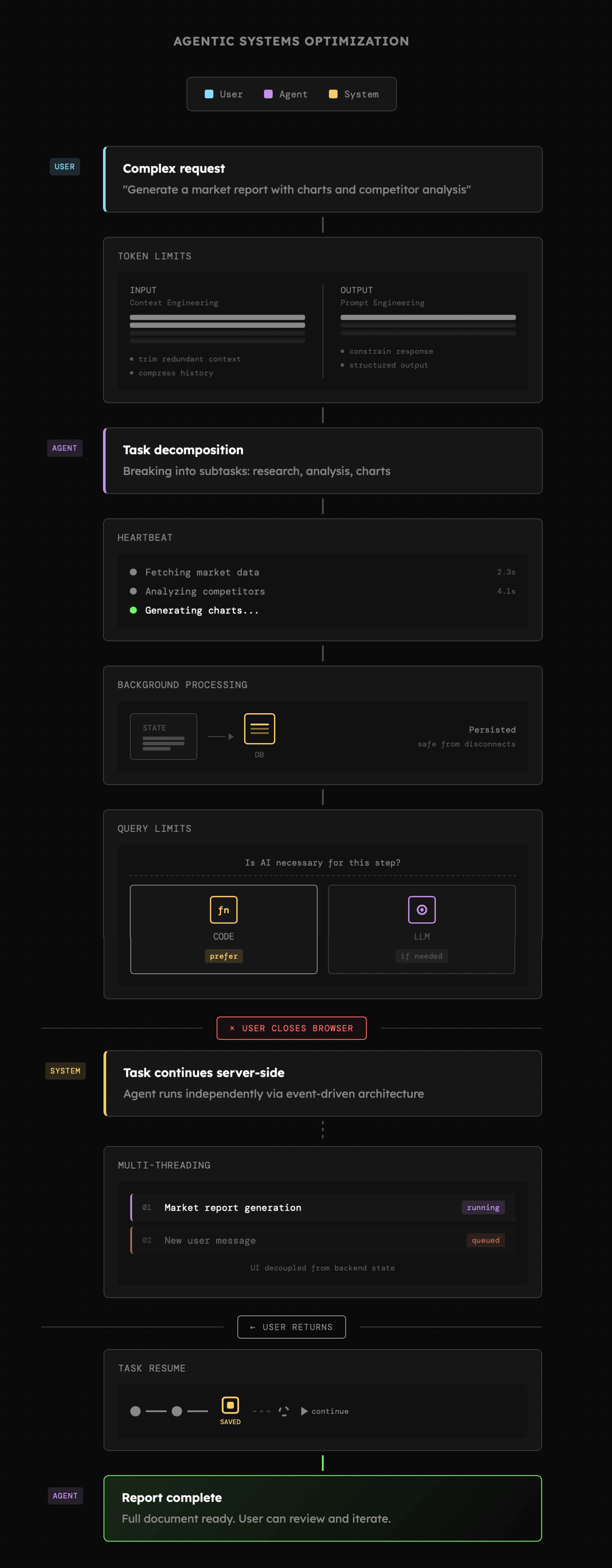
- **heartbeat**: pracując z agentami AI, nie zawsze mamy możliwość poinformowania użytkownika o tym, kiedy zadanie zostanie zakończone. Możemy jednak informować go o tym, co aktualnie się dzieje. Mowa nie tylko o raportowaniu kolejnych kroków, ale niekiedy także o możliwości wglądu w rezultat końcowy, na przykład w budowany dokument. Uwzględnienie przy tym możliwości reakcji również jest bardzo użyteczne. Choć „heartbeat” sam w sobie nie ma bezpośredniego wpływu na wydajność, z pewnością zmienia wydajność postrzeganą przez użytkownika.
|
||||
- **wielowątkowość:** niektóre zadania, np. generowanie obrazów czy wideo, naturalnie będą wymagały więcej czasu. Użytkownik musi być poinformowany o trwającym generowaniu oraz musi mieć możliwość **przesłania wiadomości do kolejki** (która zostanie wysłana, gdy będzie to możliwe) oraz **otworzenia nowego wątku**. Uwzględnienie takiej możliwości musi mieć miejsce już na poziomie planowania architektury aplikacji bo chociażby sam stan UI nie może być powiązany bezpośrednio z akcjami na back-endzie. Choć to samo w sobie jest dobrą praktyką, tak łatwo o tym zapomnieć.
|
||||
- **przetwarzanie w tle:** przetwarzanie zapytania i zapisywanie rezultatów czy nawet samo pisanie promptu, musi uwzględniać scenariusz w którym użytkownik **zamyka aplikację**, okno przeglądarki bądź po prostu posiada niestabilne połączenie z Internetem. W związku z tym, że działanie modeli językowych (i akcje agentów AI) mogą trwać nawet kilka minut, musimy ograniczyć konieczność powtarzania tych samych zapytań.
|
||||
- **wznawianie zadań:** Wystąpienie błędu, oczekiwanie na akceptację użytkownika bądź ukończenie pracy agenta będzie wymagać możliwości **wstrzymania realizacji zadania** oraz jego późniejszej kontynuacji. Co więcej, złożoność tego mechanizmu może być większa i agent może oczekiwać na więcej niż jedną rzecz. Dlatego projektowanie systemu z myślą o komunikacji w oparciu o zdarzenia to z reguły dobry pomysł.
|
||||
- **ograniczenie zapytań:** obecność modelu w aplikacji sprawia, że możemy sięgać po niego częściej, niż jest to potrzebne. Dlatego jeśli jakieś zadanie nie jest niezbędne, bądź może zostać zrealizowane inaczej ale z pomocą kodu, to powinniśmy z tego skorzystać i zawsze zadawać sobie pytanie "czy AI jest tutaj niezbędne?"
|
||||
- **ograniczenia tokenów:** podczas interakcji z LLM, wydajność jest uzależniona od liczby tokenów wejściowych oraz wyjściowych. W praktyce, niemal zawsze możliwe jest zmniejszenie ich ilości po obu stronach, albo poprzez Context Engineering albo przez Prompt Engineering i sterowanie zachowaniem modelu.
|
||||
|
||||
|
||||
|
||||
Powyższe punkty jasno sugerują, że (obecnie) **wydajność modeli** jest niska i musimy adresować ją na poziomie architektury aplikacji oraz projektowania doświadczeń użytkownika (UX). Połączenie tego z technikami optymalizacji samej interakcji z modelami o której rozmawialiśmy w S01E02 zwykle jest wystarczające. Jeśli jednak tak nie jest, nasza uwaga może skierować się w obszar **fine-tuningu** mniejszych modeli, bądź **[destylacji](https://openai.com/index/api-model-distillation/)** tych większych. W obu przypadkach mówimy o optymalizacji na poziomie samego modelu. Techniki te są jednak jeszcze dość rzadko stosowane, chociażby ze względu na fakt, że cena i szybkość działania modeli "Flash" (np. Gemini 3 Flash, Sonnet Haiku) okazują się wystarczające.
|
||||
|
||||
**Cena**
|
||||
|
||||
Jednostkowe koszty tokenów systematycznie spadają, co na pierwszy rzut oka może sugerować, że stosowanie AI w środowisku produkcyjnym nie jest kosztowne. Niestety rzeczywistość bywa inna, ponieważ:
|
||||
|
||||
- Modele LRM (Large Reasoning Models) mogą oferować niższą cenę za token, **ale generują ich znacznie więcej**.
|
||||
- Na każde zdarzenie, na przykład „wiadomość użytkownika”, przypada zwykle więcej niż jedno zapytanie do AI. Niekiedy proporcja ta przekracza 1:50. Tutaj ponownie dbanie o cache'owanie jest fundamentalnie ważne, ale też nie zawsze możliwe.
|
||||
- Wraz ze wzrostem możliwości modeli rośnie także złożoność logiki agentów oraz horyzont czasowy, w którym operują. To bezpośrednio przekłada się na liczbę przetwarzanych tokenów.
|
||||
- AI coraz częściej przybiera proaktywną formę, obejmującą działanie w tle. W tym przypadku nawet proste zadania wykonywane w małych interwałach, szybko przekładają się na duże liczby.
|
||||
|
||||
Przy optymalizacji ceny często mówi się o tym, że warto wybrać **tańszy** model, ale nie zawsze jest to odzwierciedlone w praktyce. Dobrym przykładem jest [Solving A Million-step LLM Task With Zero Errors](https://arxiv.org/pdf/2511.09030), gdzie GPT-4.1-nano okazał się mniej efektywnym cenowo modelem niż GPT-4.1-mini, ponieważ ten pierwszy wymagał znacznie większej liczby kroków. Nadal jednak mówimy tu o zastosowaniu modelu "mini", który nie jest najmocniejszy w swojej klasie, a pomimo tego okazał się tu najlepszy.
|
||||
|
||||
Podstawą optymalizacji kosztowej jest obserwowanie aplikacji oraz zachowań użytkowników, nawet w minimalnym stopniu, który pozwoli nam określić skalę zużycia tokenów na produkcji. Bardzo pomocne okazują się platformy takie jak [Langfuse](https://langfuse.com/) czy [Confident AI](https://www.confident-ai.com/), dzięki którym możemy nie tylko obserwować, ale też ewaluować działanie systemu. Oczywiście nie zawsze będziemy mieli natychmiastowy dostęp do użytkowników produkcyjnych, ale nawet udostępnienie aplikacji lub konkretnej funkcjonalności małej grupie testerów bywa pomocne w oszacowaniu skali.
|
||||
|
||||
**Potencjalne naruszenia**
|
||||
|
||||
Niezależnie od tego, czy system wchodzi w bezpośrednią interakcję z użytkownikiem, czy działa w tle, przetwarzając na przykład dokumenty bądź wyniki wyszukiwania, może dojść do sytuacji, w której do modelu trafią dane, które nie powinny się tam znaleźć. Mogą to być między innymi:
|
||||
|
||||
- dane poufne, takie jak dokumenty firmowe bądź prywatne dane użytkowników, wliczając w to klucze API;
|
||||
- treści nieodpowiednie, poruszające tematy niezgodne z prawem bądź po prostu wykraczające poza zakres działania systemu;
|
||||
- niepożądane wykorzystanie systemu, na przykład dążenie do naruszenia jego zabezpieczeń i nadużywanie zasobów;
|
||||
- problemy wynikające z nieintencjonalnych działań użytkownika, na przykład przesłanie uszkodzonego załącznika bądź zapytania, które negatywnie wpływa na zachowanie modelu (na przykład powodując zapętlenie).
|
||||
|
||||
Błędne działanie systemu może wywołać nawet zwykłe wczytanie strony internetowej, której wybrane fragmenty wpływają na pracę AI, na przykład poprzez przekierowanie agenta do innych źródeł lub podjęcie działań, o które domyślnie nie był on proszony.
|
||||
|
||||
OpenAI udostępnia [Moderation API](https://platform.openai.com/docs/guides/moderation), które może pomóc w analizie informacji pod kątem najważniejszych problemów, ale także zgodności z polityką OpenAI. Nie stosowanie tego API w przypadku pracy z ich modelami **może doprowadzić do zablokowania całego konta organizacji**. W przypadku pozostałych providerów bądź w chęci dostosowania zasad klasyfikacji, możemy skorzystać z własnych reguł, co sugeruje na przykład [dokumentacja Gemini](https://docs.cloud.google.com/vertex-ai/generative-ai/docs/multimodal/gemini-for-filtering-and-moderation).
|
||||
|
||||
Moderacja treści oraz blokowanie potencjalnie niezgodnych z zasadami żądań może działać także w sposób zakłócający normalne funkcjonowanie aplikacji. Jest to widoczne nawet przy klasyfikacji zdjęć bądź ich edycji, gdzie część akcji zostanie zablokowana nawet pomimo dobrych intencji użytkownika. Na przykład wygenerowanie reklamy z interfejsem czatu Messenger może (nie musi) być zablokowane przez modele takie jak Gemini.
|
||||
|
||||
Filtrowanie zapytań nie zawsze będzie dotyczyło wyłącznie łamania prawa czy zasad dostawców. Niekiedy kluczowy będzie sam zakres działania systemu. Wówczas będzie nam zależało na określeniu, czy dana interakcja nie wykracza poza ustalone ramy. Możemy to zweryfikować za pomocą promptu, którego zadaniem będzie zwrócenie **ustrukturyzowanej odpowiedzi** opisującej dane wejściowe. Następnie, na podstawie otrzymanych właściwości, programistycznie decydujemy o dalszym przebiegu logiki.
|
||||
|
||||

|
||||
|
||||
Jak zwykle należy mieć tutaj na uwadze **halucynacje modelu**, które mogą mieć wpływ na błędne klasyfikacje. Tutaj jednak nie możemy zrobić zbyt wiele, a jeśli stosujemy Moderation API, to zwykle będzie to wystarczające.
|
||||
|
||||
**Niewłaściwe zachowanie modeli**
|
||||
|
||||
Bez względu na działania, które podejmujemy w kontekście architektury czy monitorowania interakcji użytkowników, może dojść do sytuacji w której system zrobi coś, czego nie powinien. Z tego powodu aplikacja powinna jasno informować o tym fakcie, a sam produkt być pod tym kątem zabezpieczony na poziomie prawnym.
|
||||
|
||||
Jeśli więc będziemy projektować aplikacje, funkcjonalności czy narzędzia na potrzeby firm bądź klientów, zawsze musimy pamiętać o poinformowaniu właściwych osób o konieczności zadbania o odpowiednie dokumenty w postaci Regulaminów, Polityki Prywatności, a także umów z dostawcami czy użytkownikami końcowymi. W związku z tym, że jest to obszar biznesowo-prawny, nie będziemy wchodzić w szczegóły. Tym bardziej, że poziom detali będzie różnił się w zależności od projektu, firmy oraz zakresu działalności.
|
||||
|
||||
**Główne decyzje dotyczące architektury**
|
||||
|
||||
Wybór modeli, frameworków, narzędzi oraz pozostałych elementów stacku technologicznego aplikacji od zawsze stanowi dość duże wyzwanie. Zwykle są to decyzje wiążące, które nierzadko trudno jest odwrócić i niekiedy staje się to niemożliwe ze względu na zbyt duży koszt alternatywny.
|
||||
|
||||
W przypadku generatywnych aplikacji sytuacja do pewnego stopnia wygląda podobnie, ale pojawiają się pewne zmienne, które trzeba mieć na uwadze. Dotyczy to głównie obszaru **integracji z providerami** i ich modelami oraz **wyborze frameworków**. Aktualnie "najlepsze" zasady, którymi można się kierować obejmują:
|
||||
|
||||
- **Wspólny interfejs** dla providerów, umożliwiający swobodne (bądź łatwe) przełączanie się pomiędzy modelami. Tutaj pomocne są biblioteki takie jak [AI SDK](https://ai-sdk.dev/), choć korzystanie bezpośrednio z oficjalnych SDK również jest dobrym pomysłem. Tym bardziej że pozwala to na lepsze dopasowanie logiki, na przykład przez własny system zdarzeń czy hooków.
|
||||
- **Brak frameworków** - choć ich stosowanie w klasycznych aplikacjach jest dziś standardem, tak w obszarze generatywnego AI powinniśmy ich (jeszcze) unikać. Dynamiczny rozwój modeli, wciąż kształtujące się API oraz techniki pracy z modelami sprawiają, że frameworki szybko stają się dużym obciążeniem a ich aktualizacja bądź migracja są problematyczne. Nie jest to wyłącznie moje zdanie, ponieważ nawet w sieci trudno jest znaleźć wpisy na temat produkcyjnego zastosowania LLM, które mówiłoby o dobrych doświadczeniach z Langchain czy CrewAI.
|
||||
- **Niezależność** obejmuje ograniczenie korzystania z natywnych funkcjonalności API, a także platform wymagających przechowywania danych z utrudnionym eksportem, takich jak niektóre wyszukiwarki wektorowe czy narzędzia do ewaluacji. Choć nie mówimy tutaj o popadaniu w skrajności i unikaniu wszelkich zobowiązań, należy mieć na uwadze, że rozwiązanie, z którego korzystamy dziś, pozostanie z nami znacznie krócej niż ma to miejsce w klasycznych aplikacjach.
|
||||
- **Przemyślana architektura** od zawsze zwiększała elastyczność aplikacji pod kątem jej rozwoju. Obecnie nabiera to jeszcze większego znaczenia z uwagi na rosnącą dynamikę zmian oraz zwiększone prawdopodobieństwo wprowadzania istotnych modyfikacji nawet w obrębie fundamentalnych modułów aplikacji.
|
||||
|
||||
Wraz z upływem czasu i dalszym rozwojem modeli, technik projektowania agentów oraz narzędzi, część powyższych punktów może stracić na znaczeniu. Jednocześnie zasady te są dość uniwersalne i aktualnie jeszcze obserwujemy wzrost ich roli. Jeśli połączymy je z obszarami omówionymi powyżej (np. architektury opartej o zdarzenia), to zyskujemy pełen obraz generatywnej aplikacji.
|
||||
|
||||
## Rodzaje limitów modeli generatywnego AI oraz API
|
||||
|
||||
Wiele mówi się o różnych limitach umiejętności modeli językowych, jednak na produkcji dotyczyć będą nas także ograniczenia techniczne, takie jak **limit tokenów wyjściowych**, **ograniczenie bazowej wiedzy modelu** a także **limity zapytań API**.
|
||||
|
||||
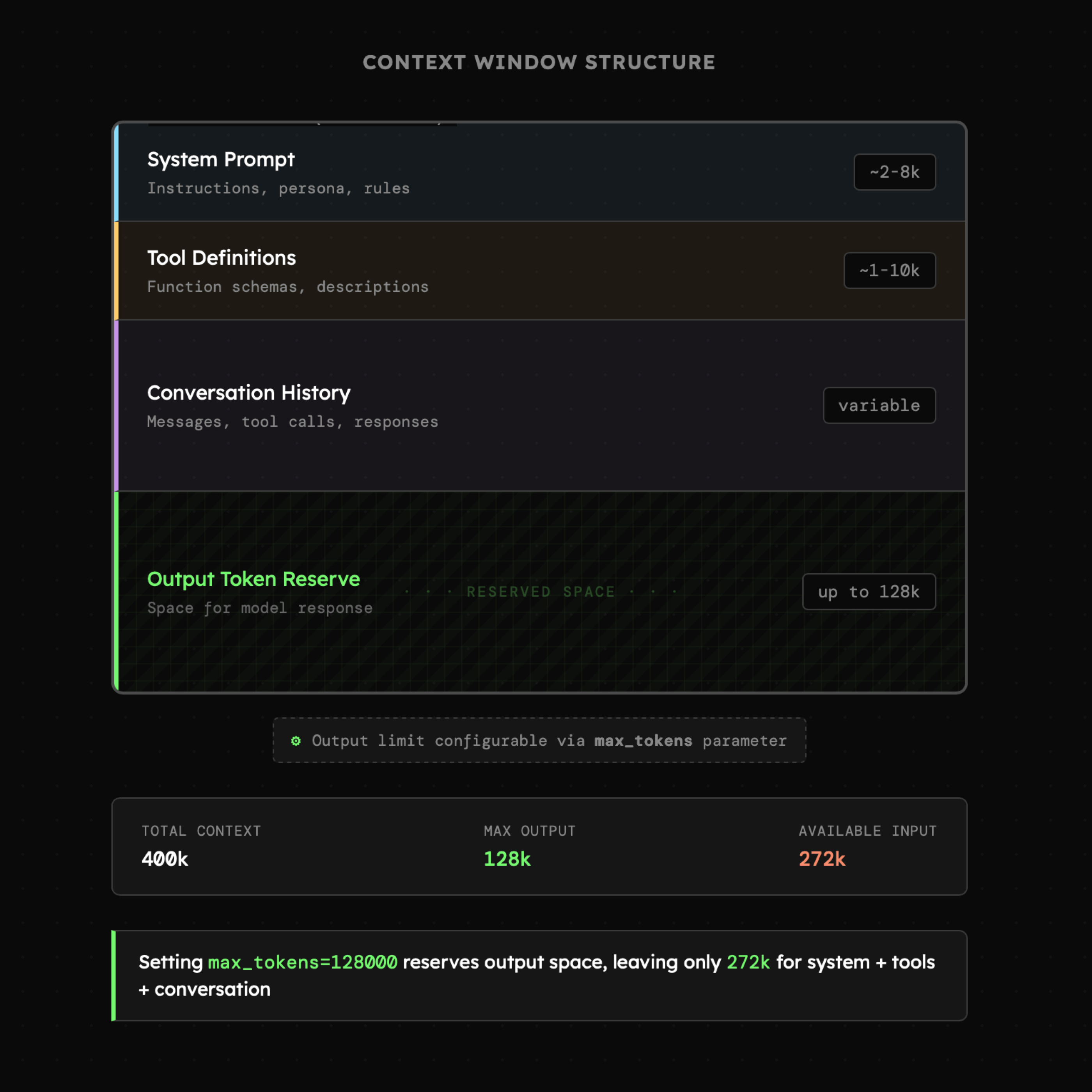
Modele językowe aktualnie nie mogą generować treści w nieskończoność w pojedynczym zapytaniu, ponieważ limity wypowiedzi modelu wynoszą obecnie od 2 000 do 128 000 tokenów. Zatem jeśli model GPT-5.2 ma deklarowane okno wielkości **400k** tokenów, a limit tokenów wyjściowych wynosi **128k**, to przy ustawieniu parametru **max\_tokens** na najwyższą wartość, pozostanie nam "jedynie" 272k tokenów do wykorzystania.
|
||||
|
||||
|
||||
|
||||
Przy większości pojedynczych zapytaniach, takie limity raczej nie są problemem i utrzymywanie domyślnych wartości oraz pomijanie estymacji tokenów jest w porządku. Natomiast dla złożonych interakcji, agentów oraz systemów wieloagentowych, kontrola liczby tokenów w kontekście staje się niezwykle istotna. Niestety nie jest to oczywiste, i obecnie najlepsze techniki obejmują:
|
||||
|
||||
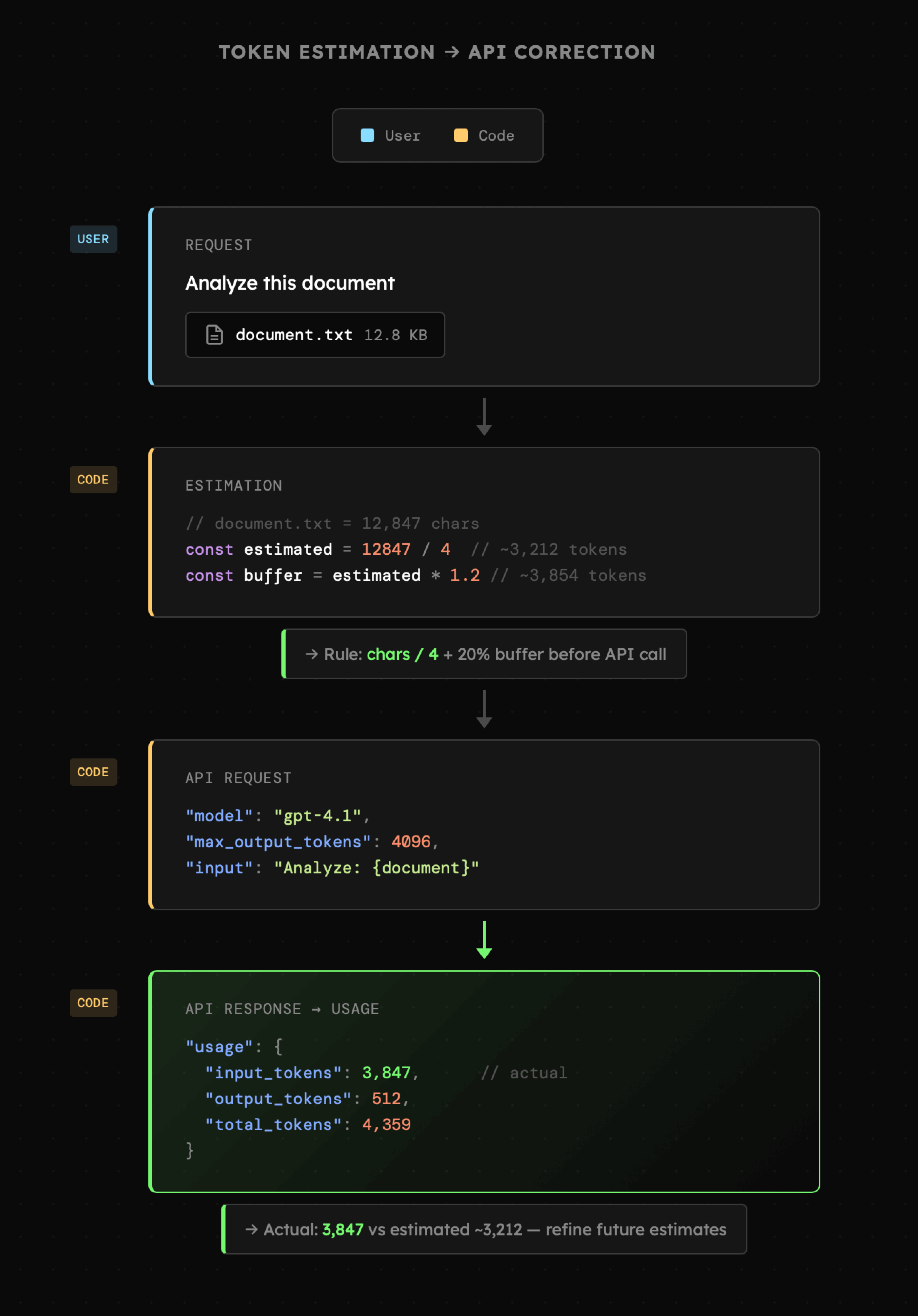
- wstępną estymację tokenów poprzez zastosowanie uproszczenia **chars / 4** (ponieważ 1 token to zwykle 3-4 litery w języku angielskim) oraz zachowanie bufora w formie około 20% limitu danego modelu.
|
||||
- po wysłaniu zapytania API zwraca odpowiedź z informacją o wykorzystanych tokenach zarówno dla danych wejściowych, jak i wyjściowych. Pozwala to na **doprecyzowanie wstępnej estymacji** oraz ewentualne dopasowanie właściwości **max\_tokens** przy zapytaniu.
|
||||
|
||||
|
||||
|
||||
W zależności od aktualnej liczby tokenów dla danej interakcji, możemy uruchamiać akcje związane z kompresją, przesłanianiem bądź ekstrakcją informacji. Obecnie warto to robić bardzo wcześnie i pierwsze z nich mogą być uruchamiane już przy około 30% zużycia dostępnego limitu.
|
||||
|
||||
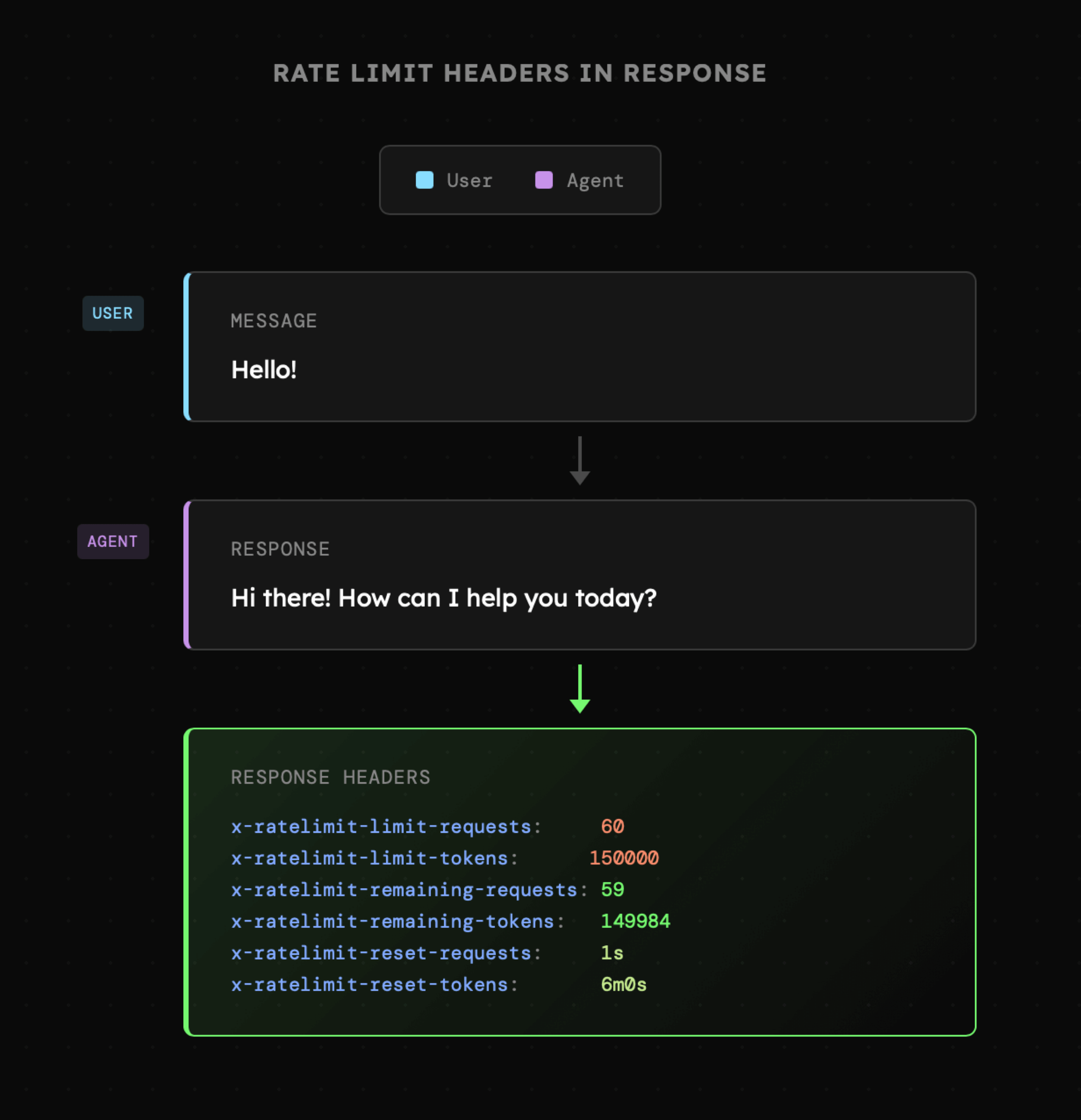
Kolejnym wątkiem są wspominane już limity zapytań do API, które zwykle obejmują **zapytania na minutę** oraz **tokeny na minutę**. Informacje o nich uzyskujemy zwykle w nagłówkach odpowiedzi, na podstawie których wartości możemy zaadresować zbliżający się limit przy jednoczesnym poinformowaniu użytkownika o konieczności wydłużonego oczekiwania na odpowiedź.
|
||||
|
||||
|
||||
|
||||
Na produkcji zawsze będzie nam zależało nie tylko na kontrolowaniu limitów danego providera, lecz także na narzuceniu ograniczeń samemu użytkownikowi. Przykładowo, jeśli jedna z funkcjonalności aplikacji wymaga interakcji z AI, to w celu uniknięcia jej zbyt częstego wywoływania, użytkownik powinien posiadać własny limit zapytań.
|
||||
|
||||
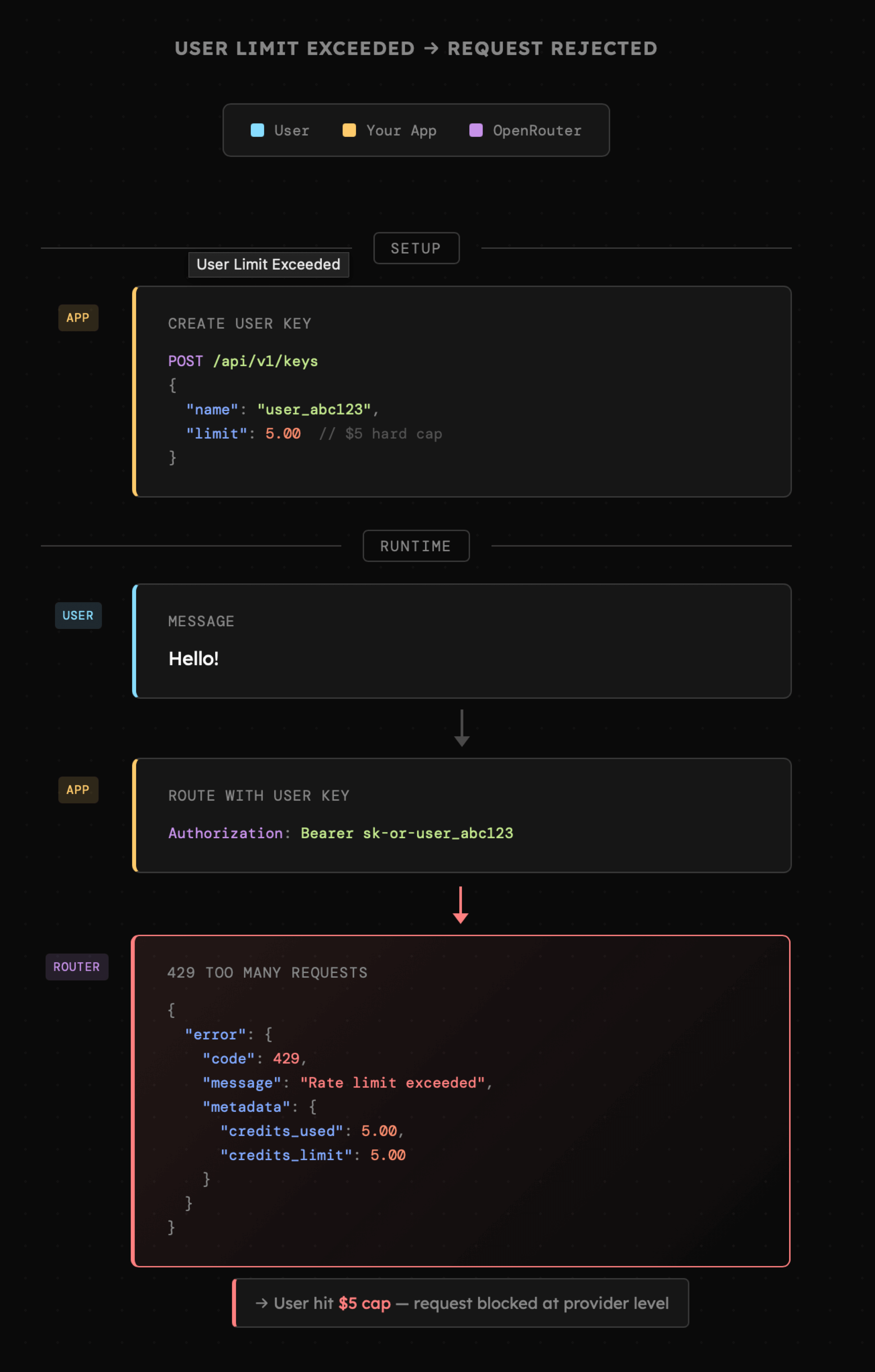
W zależności od charakteru aplikacji którą tworzymy, może interesować nas ścisłe ograniczenie wydatków na danego użytkownika. Pod tym kątem świetnie sprawdza się wspominany już [OpenRouter](https://openrouter.ai/) w przypadku którego możemy programistycznie zarządzać kluczami użytkowników, generując indywidualne tokeny, które posiadają swoje własne limity.
|
||||
|
||||
|
||||
|
||||
Zasadniczo wszędzie tam, gdzie udostępniamy akcje API w których logikę zaangażowany jest model, powinniśmy szczególnie dbać o ich zabezpieczenie przed zbyt dużą liczbą zapytań, bez względu na to czy wymagają one logowania czy są otwarte dla anonimowych użytkowników.
|
||||
|
||||
## Niejawne ograniczenia oraz powszechne błędy modeli
|
||||
|
||||
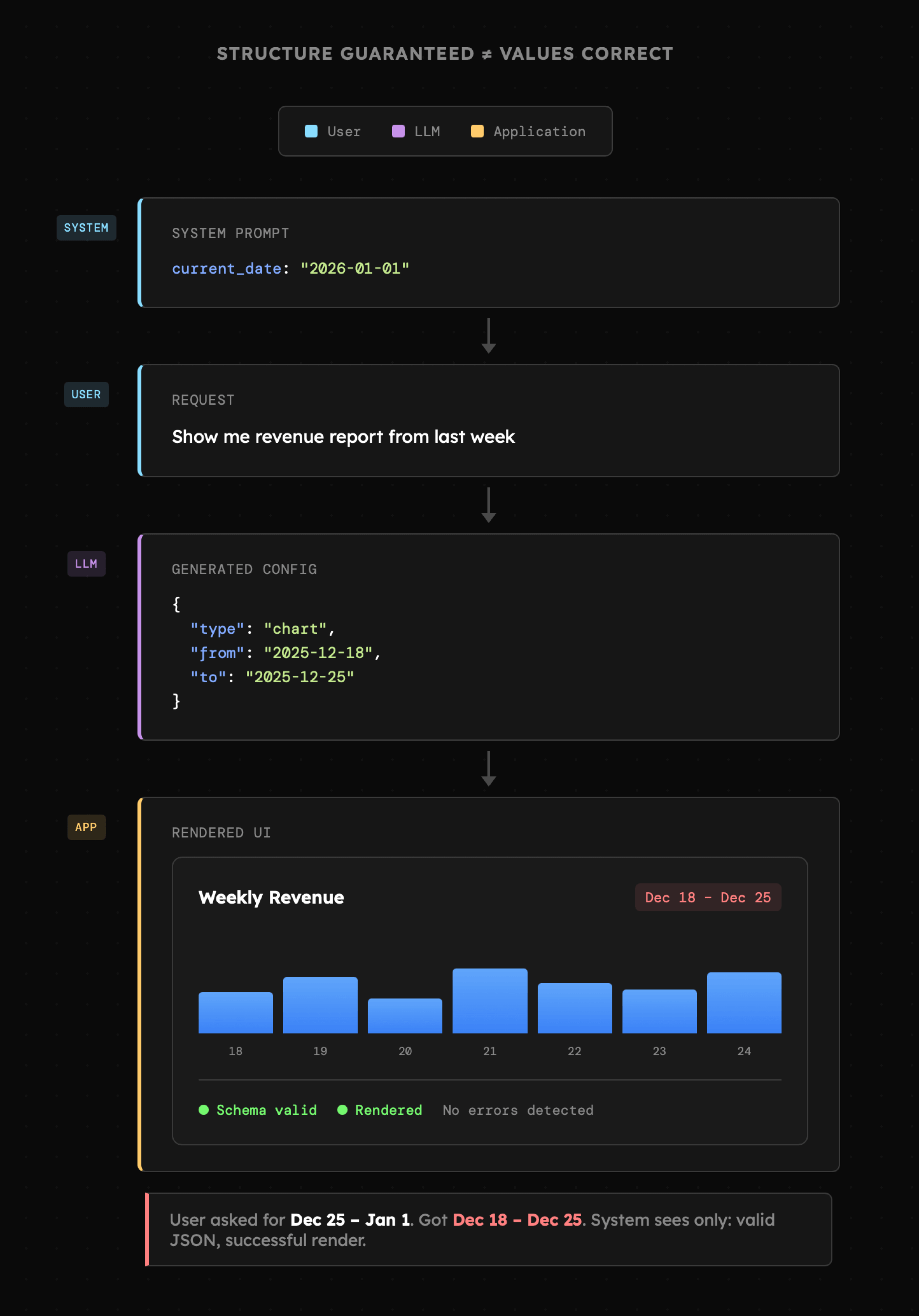
Projekty takie jak **[json-render](https://github.com/vercel-labs/json-render)**, umożliwiające generowanie dynamicznych interfejsów, są prezentowane hasłami **guardrailed** i **predictable**, a niekiedy także **deterministic**. Na tym etapie powinno być jasne, że działanie tych interfejsów nie ma nic wspólnego ze 100% pewnością co do uzyskanych rezultatów. Chodzi o to, że **gwarancja struktury** nie oznacza **gwarancji wartości**, czyli nawet jeśli zwrócony obiekt JSON będzie mieć odpowiedni kształt, tak poszczególne wartości mogą być ustawione błędnie. Prosty przykład widzimy poniżej.
|
||||
|
||||
|
||||
|
||||
Pomimo tego, że **struktura** wypowiedzi modelu została zachowana i pozwoliło to na renderowanie dynamicznego wykresu, tak prezentowane wartości są błędne, ale system nie był w stanie tego wykryć. W dodatku nawet jeśli generowana odpowiedź miałaby zostać **weryfikowana przez sam model**, to choć istnieje szansa na to, że błąd zostałby wykryty, tak dalej nie mamy pewności czy tak będzie.
|
||||
|
||||
Poziom halucynacji modeli spada w czasie, co sugerują chociażby publikacje takie jak [GPT-5.2 System Card](https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf), ale też nie możemy powiedzieć, że problem nie istnieje.
|
||||
|
||||
Obecnie najłatwiej go zaobserwować w przypadku modeli takich jak Gemini Flash, gdzie w przypadku pytania o treść strony www model **w pełni halucynuje** odpowiedź, jedynie domyślając się jej treści na podstawie adresu URL oraz przypadkowych informacji z własnej bazy wiedzy. Jednocześnie model GPT-5.2 w tej samej sytuacji jasno mówi nam, że **nie posiada dostępu do danej strony www**.
|
||||
|
||||

|
||||
|
||||
Podobne halucynacje mają miejsce także wtedy, gdy model **zamiast poprosić o doprecyzowanie zapytania**, jedynie zakłada, że wie o czym mówi. Przykładem może być uzupełnianie brakujących wartości przy wywołaniu narzędzi, na przykład poprzez "domyślenie się" adresu e-mail jedynie na podstawie nazwiska.
|
||||
|
||||
Ryzyko takich halucynacji można zmniejszyć poprzez:
|
||||
|
||||
- Informowanie modelu o jego ograniczeniach, na przykład o tym, czy narzędzie **web search** jest aktywne, czy posiada dostęp do plików.
|
||||
- Instrukcje na temat oczekiwanego zachowania w przypadku braku wystarczających informacji (np. dopytanie o nie, bądź przerwanie wykonywanego zadania)
|
||||
- Zmniejszenie złożoności zadania, na przykład poprzez rozbicie go na mniejsze kroki
|
||||
- Zmniejszenie objętości kontekstu, który zwykle rozprasza uwagę modelu
|
||||
|
||||
Oczywiście w żaden sposób nie wyeliminujemy tego problemu, ale z dużym poziomem pewności można stwierdzić, że ryzyko zostanie obniżone a przy zastosowaniu GPT-5.2 domyślnie będzie niskie.
|
||||
|
||||
W kontekście halucynacji warto wspomnieć, że zachowanie modelu może wynikać również z **błędów aplikacji**. Podczas tworzenia narzędzi i modułów może się zdarzyć, że część instrukcji zostanie wczytana w niewłaściwy sposób. Zdarza się też, że model otrzymuje informację o dostępie do narzędzi, z których w rzeczywistości nie może skorzystać. Każda z takich pomyłek bywa trudna do zauważenia, szczególnie w systemach wieloagentowych. Warto zatem **zapisywać i monitorować wszystkie zdarzenia,** uwzględniając przy tym instrukcje systemowe oraz to, jak zmieniają się one w trakcie interakcji.
|
||||
|
||||
## Limity narzędzi i ograniczenia środowiskowe
|
||||
|
||||
Część ograniczeń związanych z budową generatywnych aplikacji **nie ma związku z możliwościami modeli**. Wyzwania pojawiają się także w otoczeniu, na etapie integracji z zewnętrznymi usługami czy urządzeniami, a także w istniejących procesach firmowych. Wśród nich są:
|
||||
|
||||
- rozproszone bazy wiedzy i zróżnicowane formaty dokumentów
|
||||
- niepisane i nieustrukturyzowane procesy, oparte na pracy manualnej
|
||||
- zestawach narzędzi funkcjonujących od lat, bez możliwości integracji przez API
|
||||
- fizycznym braku dostępu do aktualnych informacji, np. stanów magazynowych
|
||||
- procesach realizowanych w terenie, np. działaniach sprzedażowych
|
||||
|
||||
Takie problemy muszą być adresowane przy ścisłej współpracy z biznesem oraz także osobami zaangażowanymi w poszczególne procesy. Wówczas wspólnie możliwe będzie wypracowanie **nowych procesów bądź modyfikacji istniejących**, a także **migracja na nowsze zestawy narzędzi**, które umożliwią integrację oraz **ujednolicenie źródeł i formatów baz wiedzy**.
|
||||
|
||||
Powyższe aktywności są 1:1 tym, co znamy od lat w kontekście wdrażania nowych rozwiązań w procesach firmowych oraz ich automatyzacji. W przypadku AI wygląda to bardzo podobnie i choć możliwości są zwykle **znacznie większe**, tak wiemy już, że zastosowanie generatywnego AI nie zawsze będzie dobrym pomysłem. W dodatku rzadko będziemy mówić o pełnej automatyzacji, lecz **optymalizacji procesu**. Z biznesowego punktu widzenia, niekiedy w pełni uzasadnione i nadal wartościowe będzie rozwiązanie **ułatwiające proces o kilka-kilkanaście procent.** Warto mieć to na uwadze.
|
||||
|
||||
Zanim pójdziemy dalej dodam, że zarówno wśród dotychczasowych jak i nadchodzących lekcji AI\_devs między wierszami znajduje się wiele wskazówek na temat projektowania rozwiązań dla biznesu. Choć nasze szkolenie nie obejmuje wprost procesów szeroko określanych mianem transformacji cyfrowej, tak ich techniczna strona jest niemal w całości tym, czym się teraz zajmujemy.
|
||||
|
||||
## Przygotowanie produkcyjnego środowiska
|
||||
|
||||
Przejdźmy teraz gruntownie przez kolejne etapy przygotowania produkcyjnej aplikacji na przykładzie API agenta, który może stać się częścią naszej codzienności. Kod źródłowy prostej aplikacji znajduje się w pliku **[01\_05\_agent](https://github.com/i-am-alice/4th-devs/tree/main/01_05_agent)**. Naszym zadaniem będzie:
|
||||
|
||||
- przygotowanie minimalnej struktury bazy danych sqlite
|
||||
- zaprojektowanie interfejsu API oraz middleware do transformacji danych
|
||||
- wsparcie dwóch różnych providerów (OpenAI i Gemini)
|
||||
- stworzenie interfejsu dla zarówno dedykowanych narzędzi, jak i MCP
|
||||
- podłączenie monitorowania aplikacji oraz aktywności agentów
|
||||
- przygotowanie automatycznego deploymentu przez Github Actions
|
||||
- podłączenie i przekierowanie domeny
|
||||
- połączenie z graficznym interfejsem
|
||||
|
||||
Na początek przyjrzyjmy się strukturze projektu. Jest on napisany w JavaScript/TypeScript, ale nas będzie interesować wyłącznie **architektura** oraz **założenia projektowe** i wdrożone **koncepcje**. Dla kontekstu dodam, że 100% kodu źródłowego zostało wygenerowane przez Opus 4.5/4.6 w ciągu niespełna 3 godzin - obrazuje to potencjalne tempo w jakim obecnie możemy poruszać się z AI, ale nie chodzi o sugestię, że tak musi to wyglądać(!) bo warunki produkcyjne i praca w zespole zwykle nie będą na to pozwalać.
|
||||
|
||||
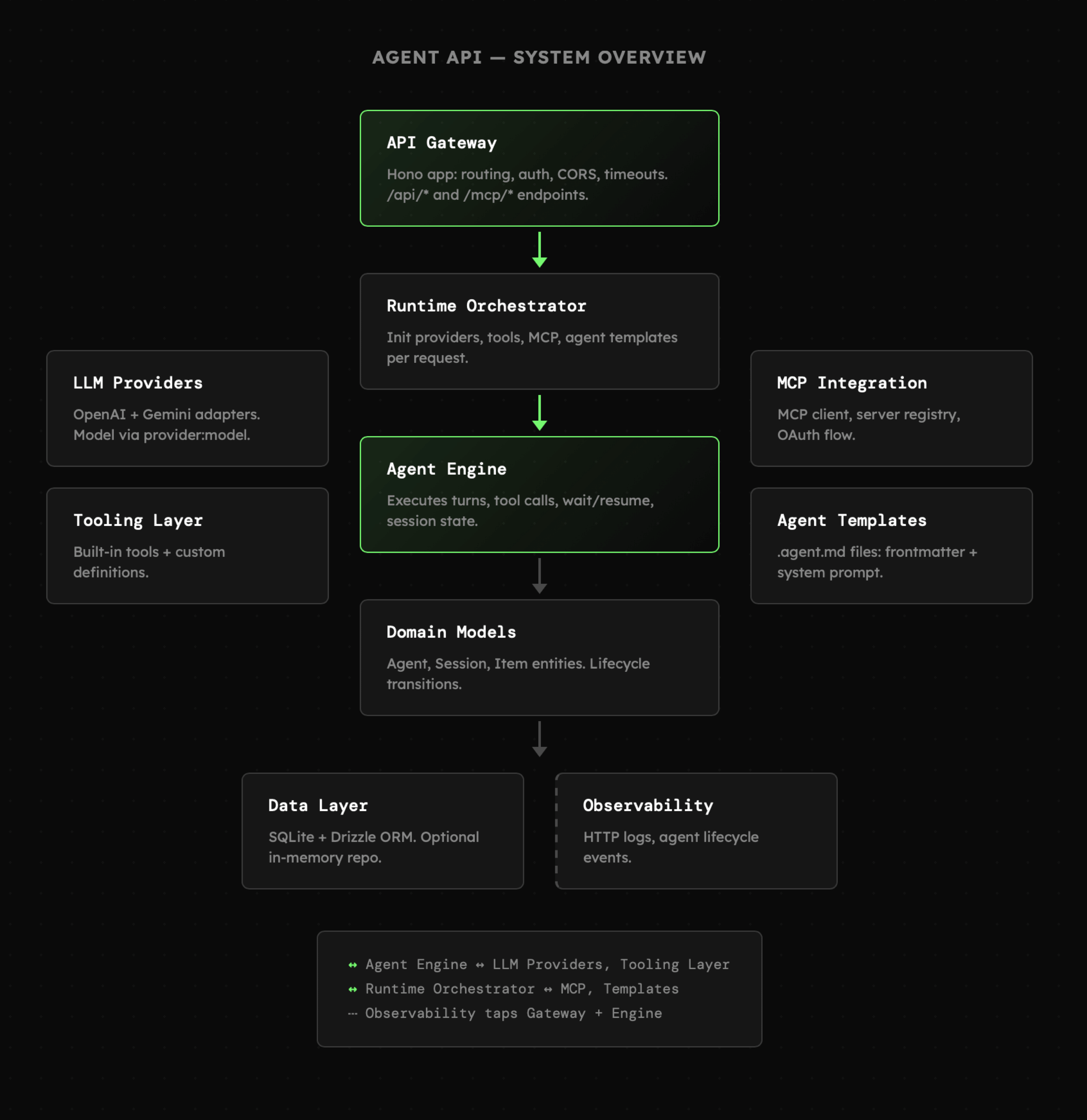
Poniższy schemat prezentuje szeroką perspektywę aplikacji i jej główne komponenty. W praktyce mówimy tutaj o niemal wszystkim, o czym rozmawialiśmy w tym tygodniu, czyli:
|
||||
|
||||
- API, przede wszystkim **/api/chat** do interakcji z agentami
|
||||
- Konfigurację obejmującą zabezpieczenie ścieżek, CORS, timeout'y i rate-limit
|
||||
- Logikę pętli agenta pozwalającą na prowadzenie sesji oraz interakcję z otoczeniem
|
||||
- Architekturę opartą o zdarzenia, umożliwiającą działanie asynchroniczne
|
||||
- Pełną niezależność od frameworków i bibliotek AI
|
||||
- Spójny interfejs do interakcji z różnymi providerami (tutaj OpenAI i Gemini)
|
||||
- Możliwość dodawania narzędzi zarówno dedykowanych jak i MCP (stdio/streamable)
|
||||
- Logikę zarządzającą kontekstem, w tym także prompt cache oraz kompresję interakcji
|
||||
- Skalowalną strukturę bazy danych omawianą w lekcji **S01E02**
|
||||
- Pełną integrację z systemem do monitorowania generatywnych aplikacji
|
||||
- Elastyczną architekturę umożliwiającą dynamiczny rozwój
|
||||
|
||||
|
||||
|
||||
Zanim przejdziemy dalej, chciałbym podkreślić, że **powyższe komponenty** nie będą zawsze wymagane przy budowaniu systemów agentowych, albo w szczególności pojedynczych funkcjonalności w których część logiki musi być zrealizowana przez agenta. Jednocześnie w przypadku aplikacji produkcyjnych, przykład ten daje bardzo solidny wgląd w to, co potencjalnie możemy budować.
|
||||
|
||||
Przyjrzyjmy się zatem podstawowej konfiguracji aplikacji, oraz strukturze endpoint'ów. Konkretnie:
|
||||
|
||||
- Zmienne środowiskowe w ustawień aplikacji (host, port, cors, limity), połączeń z bazą danych i providerami, są przechowywane w pliku .env, który **nie jest częścią repozytorium** (choć to akurat, powinno być oczywiste)
|
||||
- Niemal wszystkie ścieżki API **są zabezpieczone** kluczem API przypisanym do **użytkownika**, który jest przechowywany w formie hash'a w bazie danych. (domyślny klucz jest zapisany w pliku **seed.ts**).
|
||||
- API udostępnia akcje do **interakcji ze wskazanym agentem** poprzez przesłanie **najnowszej wiadomości** w ramach sesji, której **identyfikator** jest przesłany w zapytaniu. Domyślnie format ten wzoruje się na [Responses API](https://platform.openai.com/docs/api-reference/responses/create) i pozostaje taki sam niezależnie od providera wykorzystywanego przez danego agenta.
|
||||
- API udostępnia także akcje pozwalające na autoryzację Serwerów MCP, które wymagają połączenia OAuth 2.1. Adres, którego rolą jest zainicjowanie procesu **jest publiczny**.
|
||||
- API naturalnie może udostępniać więcej akcji, powiązanych chociażby z rejestracją i zarządzaniem użytkownikami, bądź innymi elementami aplikacji. W naszym przykładzie jednak nie ma to obecnie miejsca.
|
||||
|
||||
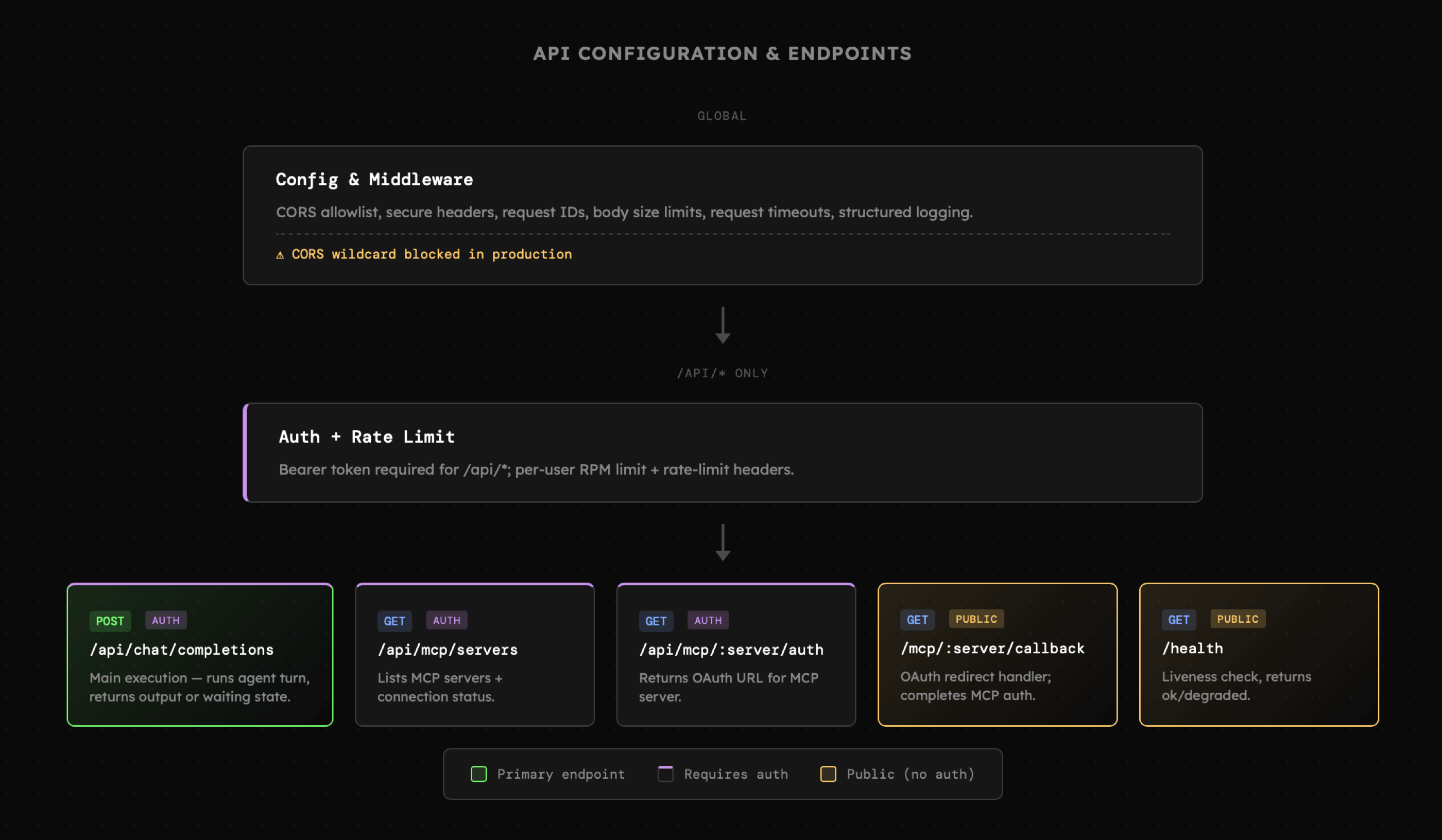
|
||||
|
||||
Zatem z punktu widzenia konfiguracji stosujemy tutaj wszystkie typowe techniki znane z klasycznych aplikacji, zwracając szczególną uwagę na endpointy, w których pojawia się model.
|
||||
|
||||
Na tym etapie do gry wchodzi budowanie kontekstu oraz ustawień dla bieżącej interakcji. Agent ma tutaj formę **pliku markdown**, który zawiera ustawienia (nazwę, opis, model, narzędzia), a także wiadomość systemową. To także miejsce na zbudowanie listy narzędzi (zarówno dedykowanych jak i zewnętrznych z serwerów MCP) oraz utworzenie bądź wczytanie sesji.
|
||||
|
||||
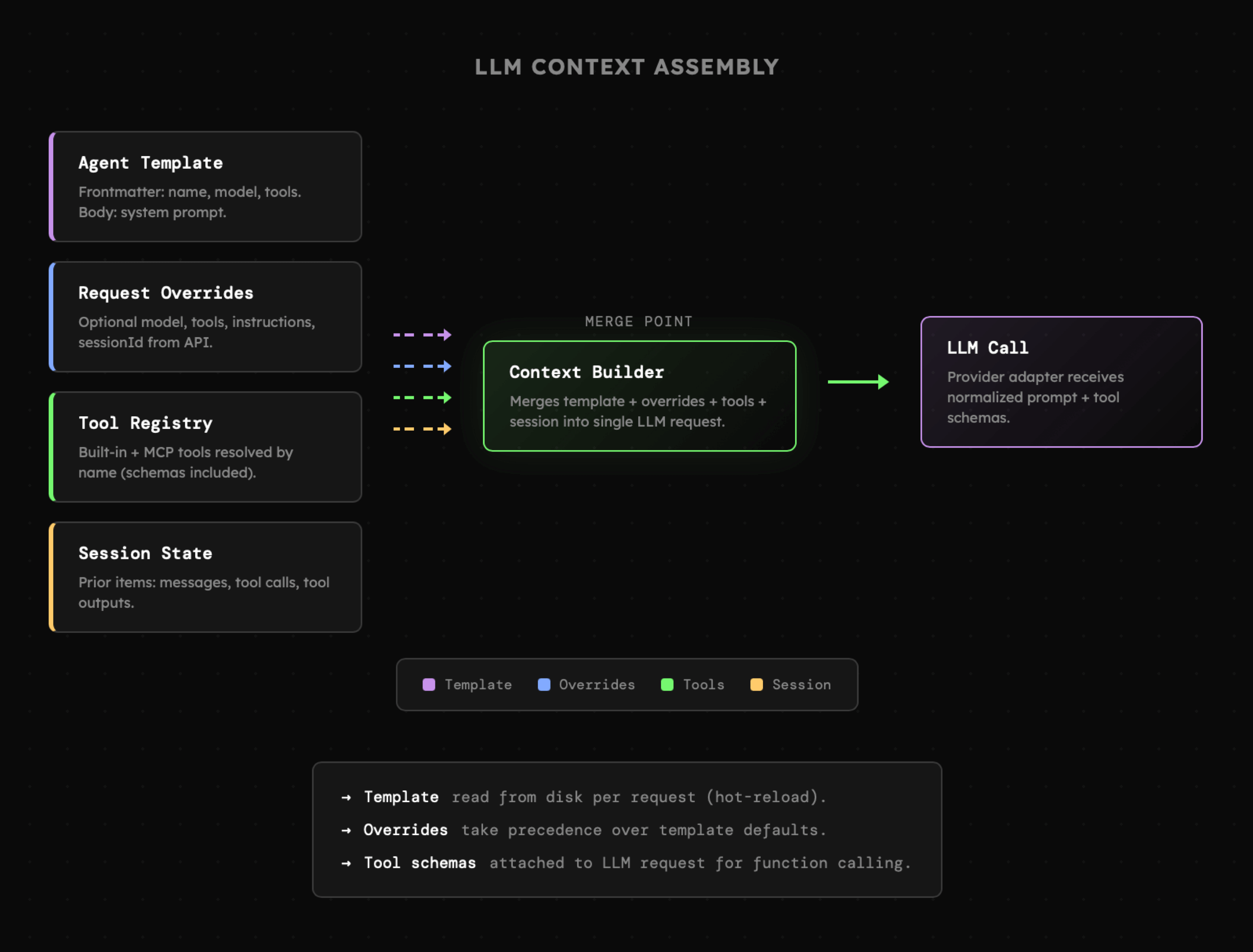
|
||||
|
||||
Dalej mamy pętlę agenta, czyli strukturę, która jest nam już znana. Tym razem kładziemy jednak nacisk na zdarzenia, do których możemy się podłączyć w celu ich monitorowania lub podejmowania konkretnych działań (na przykład kompresji kontekstu). Wśród zdarzeń wyróżniamy:
|
||||
|
||||
- rozpoczęcie interakcji z danym agentem
|
||||
- rozpoczęcie bieżącej iteracji
|
||||
- wybór, wywołanie oraz zakończenie działania narzędzi
|
||||
- zakończenie bieżącej iteracji
|
||||
- zdarzenia dotyczące wstrzymania i wznowienia działań
|
||||
- zdarzenia dotyczące błędów oraz anulowania interakcji
|
||||
|
||||
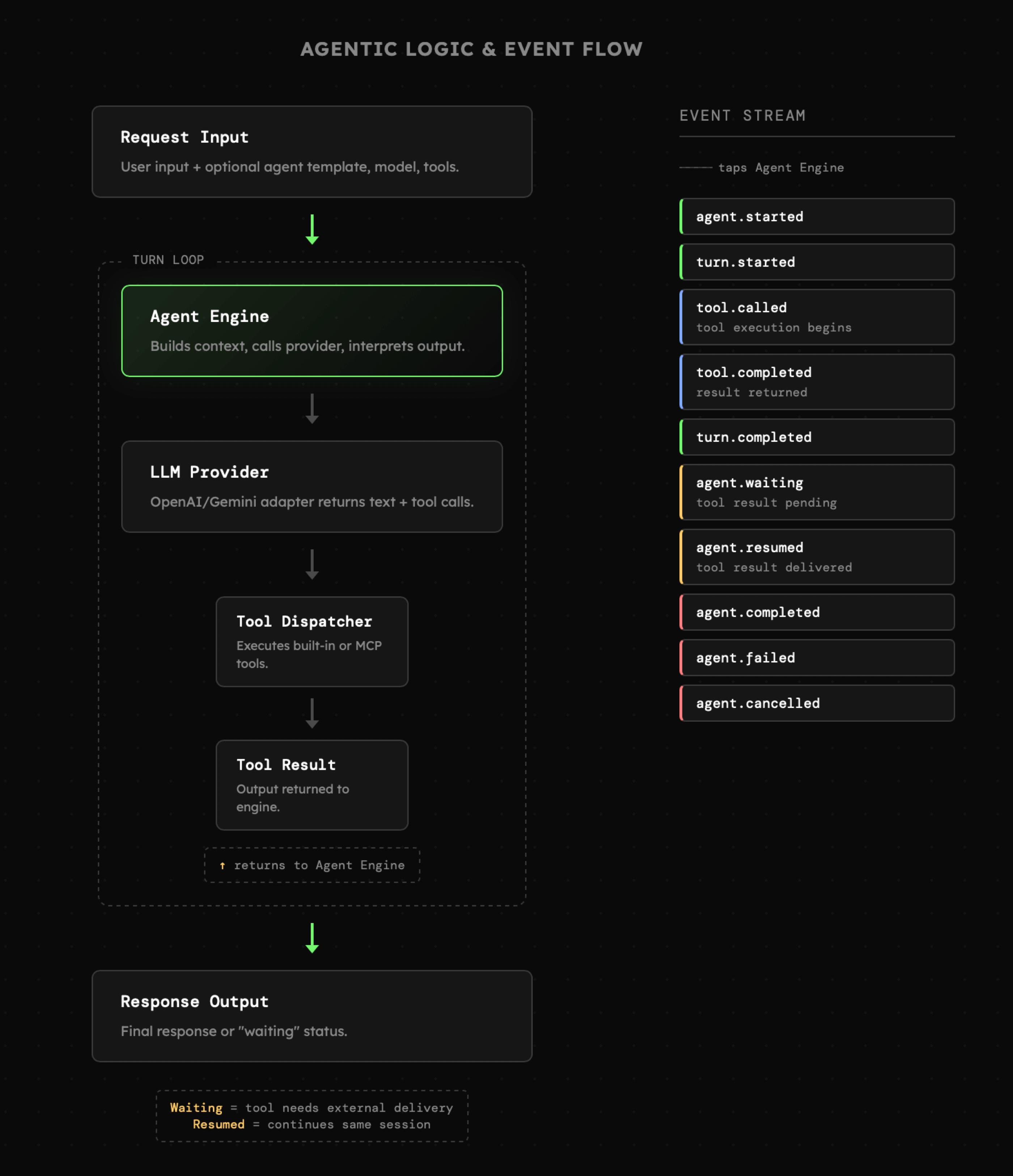
|
||||
|
||||
Na uwagę w logice agenta zasługują przede wszystkim **dbałość o poprawne utrzymanie stanu** od którego w dużym stopniu zależy wykorzystanie prompt cache, oraz obsługa zdarzeń związanych z oczekiwaniem, anulowaniem oraz błędami. Logika którą widzimy powyżej to najważniejszy element aplikacji, od którego uzależnione są niemal wszystkie pozostałe. Dobrze jest więc go dobrze przemyśleć, szczególnie gdy strukturą będzie odbiegał od typowych założeń logiki agenta (np. w związku z naciskiem na dekompozycję czy rozbudowane struktury wieloagentowe).
|
||||
|
||||
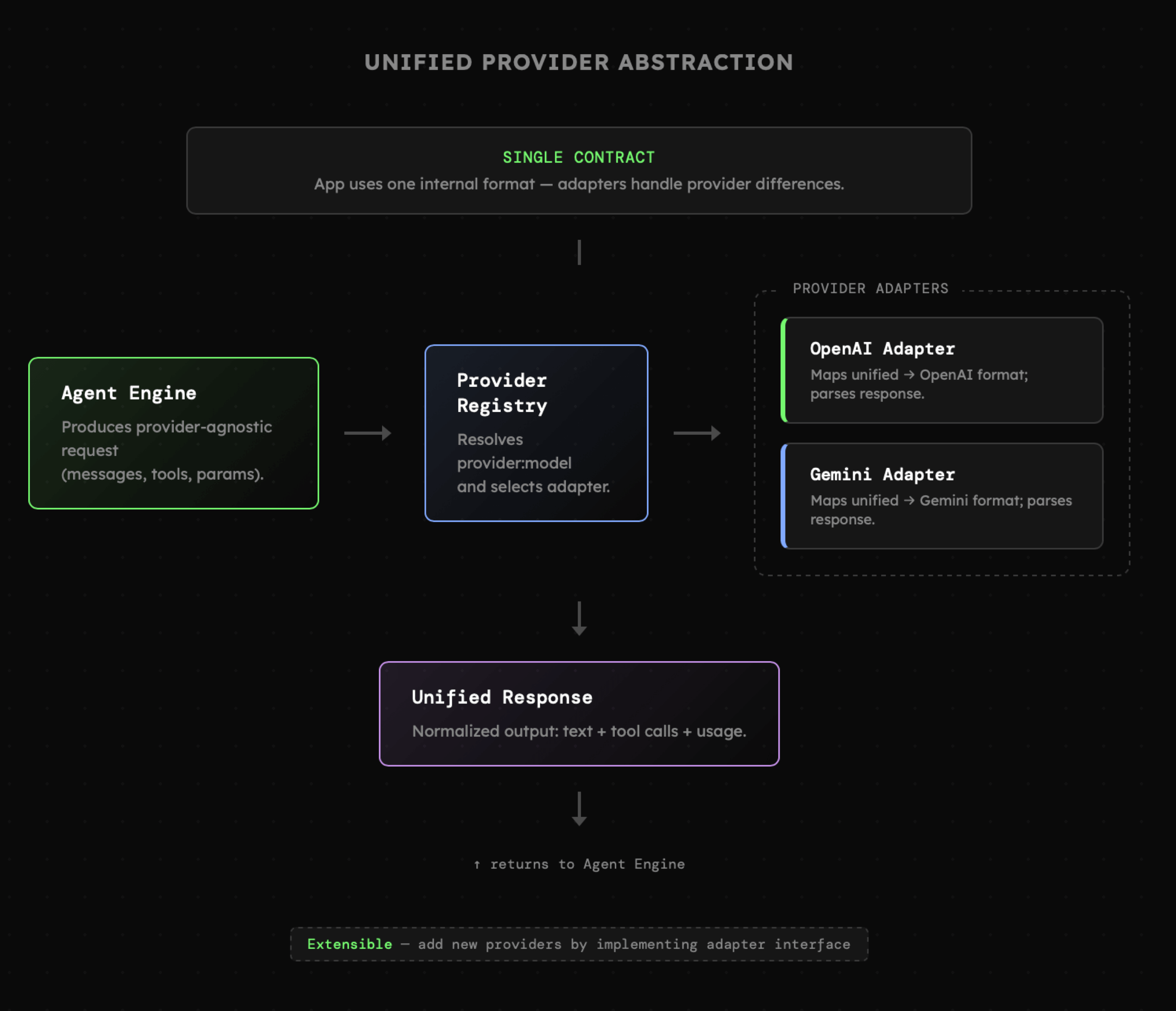
Następnym elementem aplikacji jest **ujednolicony interfejs** do komunikacji z różnymi providerami, co tym samym daje dostęp do różnych modeli i ich możliwości. Jak widać poniżej, zarówno API, jak i agent "rozmawiają tym samym językiem", ale warstwa tłumaczeń dba o poprawne przeniesienie interakcji na dany model. Poza tłumaczeniem struktur, dochodzi tu także do dostosowania ustawień takich jak limity kontekstu, czy wykluczenia niektórych funkcji ze względu na ograniczenia danego połączenia.
|
||||
|
||||
|
||||
|
||||
Z praktycznego punktu widzenia, w tym miejscu można zastosować [OpenRouter](https://openrouter.ai/) i w wielu przypadkach będzie to wystarczające. Należy jednak pamiętać, że takie platformy **nie wspierają wszystkich funkcjonalności** oraz modeli. Bardzo szybko okazuje się, że dedykowane połączenia i tak są potrzebne. Co więcej, Gemini, Anthropic oraz OpenAI coraz częściej przedstawiają elementy API, które niemal **całkowicie blokują** możliwość "tłumaczenia" interakcji pomiędzy providerami. Jednocześnie problem ten nie ma znaczenia w przypadku systemów wieloagentowych, gdzie każdy z agentów może pracować z innym API.
|
||||
|
||||
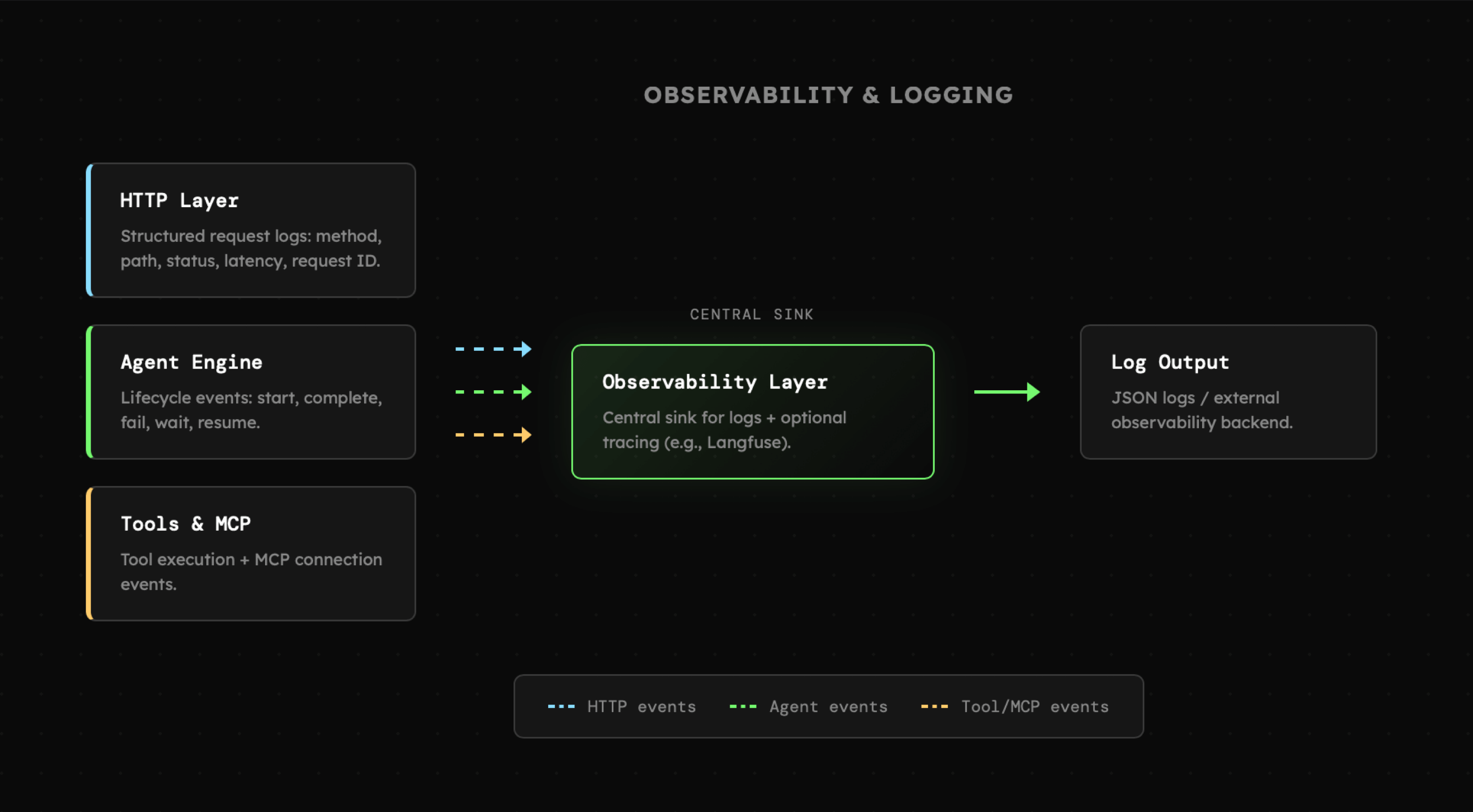
Ostatnim elementem spośród głównych komponentów aplikacji, jest system logów oraz monitorowanie działań agentów oraz komunikacji z użytkownikiem. W związku z tym, że mamy do czynienia z architekturą opartą o zdarzenia, to w dużym stopniu polegamy tu na ich subskrypcji. W tym miejscu otwieramy sobie także przestrzeń na moderowanie interakcji oraz ewentualne blokady.
|
||||
|
||||
|
||||
|
||||
Monitorowanie aplikacji ma tutaj charakter dwupoziomowy, ponieważ jeden dotyczy klasycznego systemu logów, natomiast drugi skupia się wyłącznie na działaniach agenta.
|
||||
|
||||
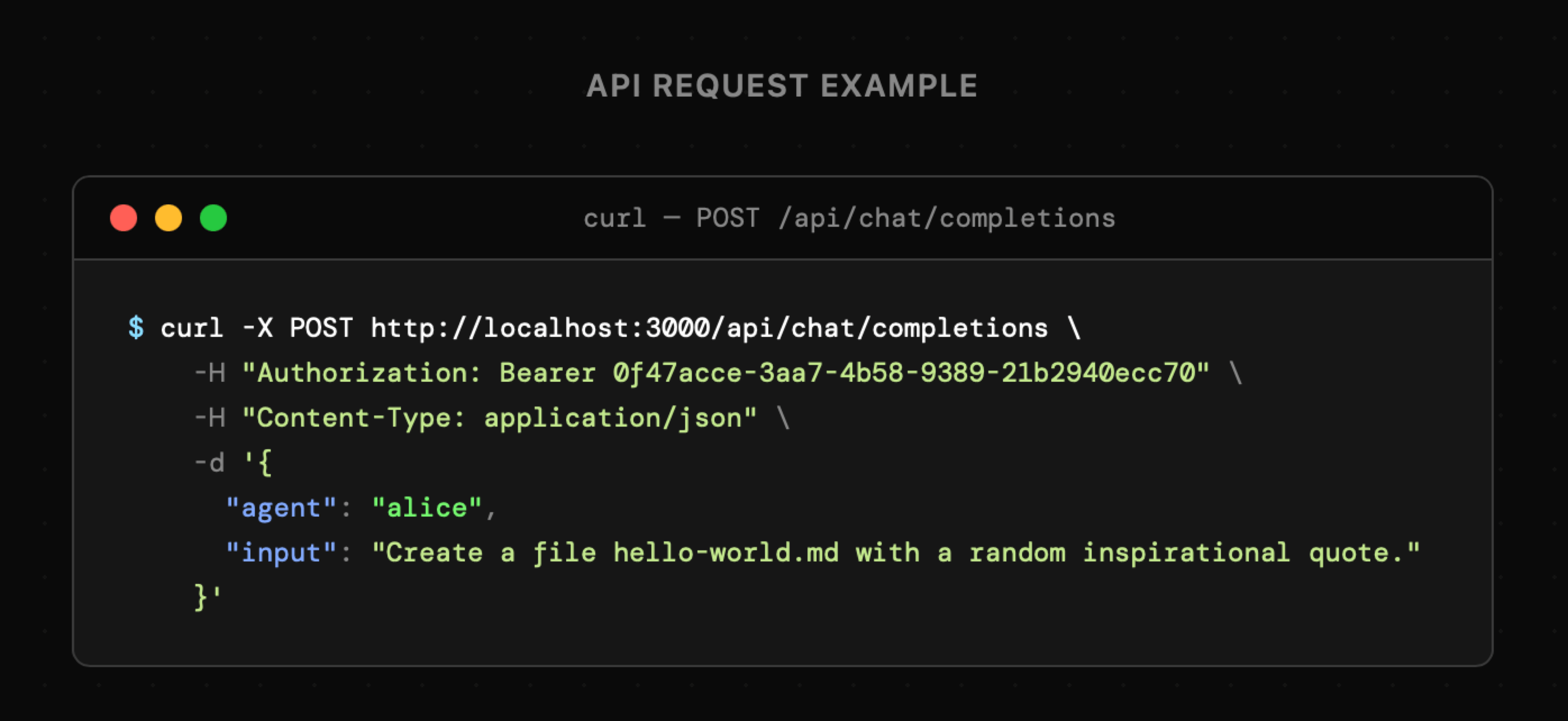
Zatem jeśli uruchomimy aplikację, a wcześniej uzupełnimy klucze **[OpenAI](https://platform.openai.com/api-keys)**, **[Gemini](https://aistudio.google.com/api-keys)** oraz ewentualnie [**Langfuse**](https://langfuse.com/) (bezpłatne konto), to możliwe będzie przesłanie poniższego zapytania. W związku z tym, że agent automatycznie połączy się z serwerem [Files MCP](https://github.com/iceener/files-stdio-mcp-server) o którym już wspominaliśmy, to możliwa będzie bardzo swobodna interakcja z plikami tekstowymi w katalogu **workspace**.
|
||||
|
||||
|
||||
|
||||
(uwaga: powyższy klucz API jest poprawny i pochodzi z pliku **seed.ts**). Przed opublikowaniem aplikacji należy go zmienić).
|
||||
|
||||
Na koniec mamy jeszcze deployment aplikacji, która co prawda może działać na naszym komputerze, ale prędzej czy później będziemy chcieli ją opublikować. Tutaj w zależności od naszych umiejętności oraz potrzeb, możemy wykupić VPS, na przykład w ramach usługi [DigitalOcean](https://digitalocean.com/) bądź [Mikr.us](https://mikr.us/).
|
||||
|
||||
> **Publikacja aplikacji nie jest konieczna!** Można jedynie przeczytać poniższe punkty, szczególnie jeśli na co dzień pracujemy na front-endzie albo temat konfiguracji deploymentu w ogóle nas nie dotyczy. Ale nawet na własne potrzeby warto jest tego doświadczyć.
|
||||
|
||||
Poszczególne kroki, obecnie już bardzo sprawnie może przeprowadzić nas AI (aczkolwiek w przypadku faktycznego serwera produkcyjnego, warto wiedzieć, co dokładnie się robi). Natomiast nawet na własne potrzeby, warto przynajmniej wiedzieć, o co należy zapytać:
|
||||
|
||||
1. Założenie konta na DigitalOcean i utworzenie tzw. dropletu, ustawionego na najnowszą wersję Ubuntu oraz Frankfurt. Do uwierzytelnienia połączenia możemy początkowo wykorzystać hasło, ale zdecydowanie lepszą opcją jest posługiwanie się kluczami SSH oraz wyłączenie możliwości logowania hasłem.
|
||||
2. Po utworzeniu serwera, należy nawiązać z nim połączenie z serwerem w terminalu i zainstalować kolejno git, node, nginx oraz skonfigurować ufw.
|
||||
3. Jeśli posiadamy wykupioną domenę, na przykład na [cloudflare](https://cloudflare.com/), możemy przekierować rekordy DNS A na adres IP naszego serwera i poczekać na jej propagację (zwykle nie trwa dłużej niż kilkanaście minut).
|
||||
4. Kolejnym krokiem jest skonfigurowanie TLS z wykorzystaniem bezpłatnego letsencrypt oraz polecenia certbot --nginx.
|
||||
5. Na tym etapie nasz projekt powinien być już w zdalnym repozytorium Github, gdzie w ustawieniach możemy utworzyć tzw. Action Runner i przejść krok po kroku przez instrukcję instalacji widoczną bezpośrednio po jego utworzeniu.
|
||||
6. Po konfiguracji runnera potrzebujemy jeszcze ustawić reverse proxy z pomocą nginx, kierując je na 127.0.0.1:3000 (bądź inny port, na którym ma działać aplikacja).
|
||||
7. Przed pierwszym udostępnieniem aplikacji należy także dodać sekretne wartości na potrzeby runnerów, w ustawieniach repozytorium Github. W naszym przypadku chodzi o wartości związane z plikiem .env.
|
||||
8. W katalogu .github naszego projektu znajduje się plik .yml zawierający workflow Github Actions. Uruchamia się ono po dodaniu zmian na głównej gałęzi git.
|
||||
|
||||
Jeśli wszystko pójdzie zgodnie z planem, aplikacja zacznie być dostępna na domenie.
|
||||
|
||||
W przypadku gdy powyższe punkty nic nie mówią, to bardzo dobrym pomysłem jest uruchomienie [Google AI Studio Live](https://aistudio.google.com/live) z udostępnionym ekranem, gdzie asystent może przeprowadzić nas przez wszystkie powyższe punkty. Ale **UWAGA** w trakcie konfiguracji serwera widoczne mogą być klucze API, więc albo należy zadbać o **wyłączenie** udostępniania ekranu na czas ich dodawania, albo wykonać proces raz w ramach nauki, oraz drugi raz, na docelowych kluczach.
|
||||
|
||||
## Fabuła
|
||||
|
||||
<https://vimeo.com/1169705378>
|
||||
|
||||
## Transkrypcja filmu z Fabułą
|
||||
|
||||
"Numerze piąty.
|
||||
|
||||
Prawdopodobnie zauważyłeś pewną nieścisłość w tym co robimy. Udało nam się przekierować transport do elektrowni w Żarnowcu. Pomogłeś nam także przygotować fałszywe dokumenty niezbędne do realizacji tego przewozu. Wszystko idzie jak po maśle, ale... jest jeszcze jedna sprawa!
|
||||
|
||||
Pewnie rzuciło Ci się w oczy, że trasa, którą ma przejechać nasz transport, jest "zamknięta". To nie jest fizyczne zamknięcie. To tylko status w systemie. Jest ona w pełni przejezdna, po prostu jeszcze nie oddali jej do użytku po przebudowie.
|
||||
|
||||
Musisz przejąć kontrolę nad systemem do sterowania trasami kolejowymi i oznaczyć tę trasę jako otwartą. Jeśli operatorzy systemu zauważą, że pociąg został wysłany na zamkniętą trasę, to z pewnością podniosą alarm, a tego byśmy nie chcieli.
|
||||
|
||||
W opisie do tego filmu znajdziesz wszelkie informacje, które pozyskaliśmy na temat tego systemu, ale powiem szczerze, że nie ma tego wiele. Czeka Cię samodzielna analiza, ale już z trudniejszymi zadaniami nam pomagałeś, więc i tym razem wierzę w Ciebie.
|
||||
|
||||
Postaraj się proszę ogarnąć tę sprawę jeszcze przed weekendem, aby na poniedziałek kasety z paliwem były już u nas w elektrowni. Nasi ludzie czekają na nie z niecierpliwością.
|
||||
|
||||
Powodzenia!"
|
||||
|
||||
## Zadanie
|
||||
|
||||
Musisz **aktywować trasę kolejową o nazwie X-01** za pomocą API, do którego nie mamy dokumentacji. Wiemy tylko, że API obsługuje akcję `help`, która zwraca jego własną dokumentację — od niej należy zacząć.
|
||||
|
||||
Nazwa zadania to **railway**. Komunikacja odbywa się przez ten sam endpoint co poprzednie zadania. Wszystkie żądania to **POST** na `https://hub.ag3nts.org/verify`, body jako raw JSON.
|
||||
|
||||
Przykład wywołania akcji `help`:
|
||||
|
||||
```json
|
||||
{
|
||||
"apikey": "tutaj-twoj-klucz",
|
||||
"task": "railway",
|
||||
"answer": {
|
||||
"action": "help"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Niestety, tylko tyle udało nam się dowiedzieć na temat funkcjonowania tego systemu. API jest celowo przeciążone i regularnie zwraca błędy 503 (to nie jest prawdziwa awaria, a symulacja), a do tego ma bardzo restrykcyjne limity zapytań. Zadanie wymaga cierpliwości.
|
||||
|
||||
### Krok po kroku
|
||||
|
||||
1. **Zacznij od `help`** — wyślij akcję `help` i dokładnie przeczytaj odpowiedź. API jest samo-dokumentujące: odpowiedź opisuje wszystkie dostępne akcje, ich parametry i kolejność wywołań potrzebną do aktywacji trasy.
|
||||
2. **Postępuj zgodnie z dokumentacją API** — nie zgaduj nazw akcji ani parametrów. Używaj dokładnie tych wartości, które zwróciło `help`.
|
||||
3. **Obsługuj błędy 503** — jeśli API zwróci 503, poczekaj chwilę i spróbuj ponownie. To celowe zachowanie symulujące przeciążenie serwera, nie prawdziwy błąd.
|
||||
4. **Pilnuj limitów zapytań** — sprawdzaj nagłówki HTTP każdej odpowiedzi. Nagłówki informują o czasie resetu limitu. Odczekaj do resetu przed kolejnym wywołaniem.
|
||||
5. **Szukaj flagi w odpowiedzi** — gdy API zwróci w treści odpowiedzi flagę w formacie `{FLG:...}`, zadanie jest ukończone.
|
||||
|
||||
### Wskazówki
|
||||
|
||||
- **API jest samo-dokumentujące** — nie szukaj dokumentacji gdzie indziej. Odpowiedź na `help` to wszystko, czego potrzebujesz.
|
||||
- **Czytaj błędy uważnie** — jeśli akcja się nie powiedzie, komunikat błędu zwykle precyzyjnie wskazuje co poszło nie tak (zły parametr, zła kolejność akcji itp.).
|
||||
- **503 to nie awaria** — błąd 503 jest częścią zadania. Kod musi go obsługiwać automatycznie przez retry z backoffem, inaczej zadanie nie da się ukończyć.
|
||||
- **Limity zapytań są bardzo restrykcyjne** — to główne utrudnienie zadania. Monitoruj nagłówki po każdym żądaniu i bezwzględnie respektuj limity. Zbyt agresywne odpytywanie spowoduje długie blokady.
|
||||
- **Wybór modelu ma znaczenie** — przy restrykcyjnych limitach API liczy się każde zapytanie. Modele, które potrzebują więcej kroków do rozwiązania zadania (lub robią niepotrzebne wywołania API), szybciej wyczerpią limit. Warto przetestować różne modele.
|
||||
- **Loguj każde wywołanie i odpowiedź** — przy zadaniach z limitami i losowymi błędami dobre logowanie to podstawa debugowania.
|
||||
Reference in New Issue
Block a user